单位:约翰斯·霍普金斯大学
来源:CVPR
时间:2024
一、研究背景及意义
个性化图像生成的关键挑战是生成自定义主题的不同变体,同时保留其视觉外观。
大多数现有方法通过在参考图像集上微调预训练模型以使其记住自定义概念来实现此目标。尽管这些方法可以产生良好的合成结果,但它们需要大量资源和较长的训练时间来拟合自定义主题,并且需要多个参考图像以避免过度拟合。为了克服这些挑战,可采用无微调的个性化方法,将参考图像编码到一个紧凑的特征空间中,并在编码特征上约束扩散模型。然而,编码步骤会导致信息丢失,导致外观保留不佳。本文提出JeDi,核心思想是训练一个扩散模型,以学习共享一个共同主题的多个相关文本-图像对的联合分布。
二、研究思路及方法
本文贡献
(1)提出了一种新颖的联合图像扩散模型的免微调文本到图像生成方法。
(2)提出了一个简单且可扩展的数据合成管道,用于生成多图像个性化数据集,其中图像共享同一主题。
(3)设计了新颖的架构和采样技术,如耦合自关注和图像引导,以实现高保真的个性化。
方法
(1)数据集创建
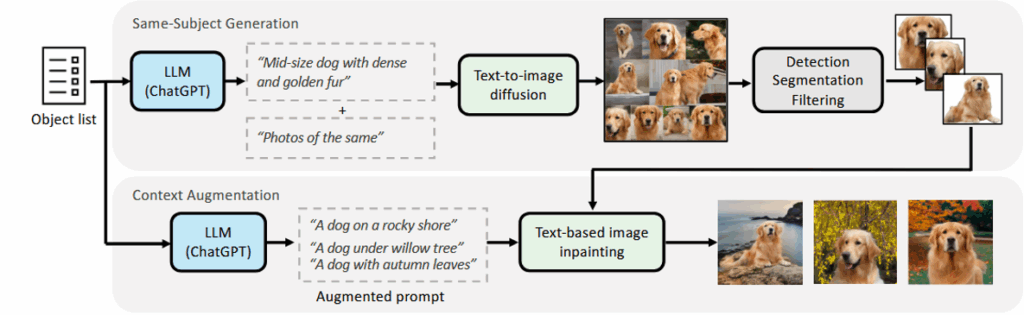
使用大型语言模型 ChatGPT和单图像扩散模型SDXL创建了一个包含相同主题的图像-文本对的多样化大规模数据集,称为合成相同主题 (S3) 数据集。
(2)Joint-Image Diffusion(JeDi)
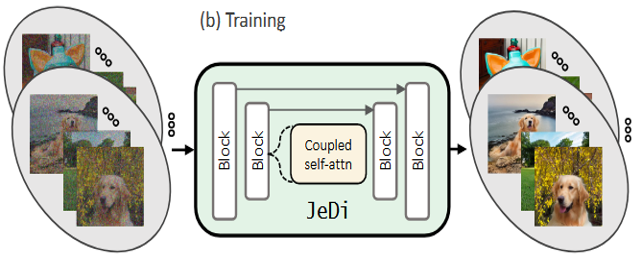
训练联合图像扩散模型的目标是生成共享同一主题的多个相关图像。在训练过程中,JeDi 模型学习对多个相同主题图像一起进行降噪,其中每个图像通过耦合自注意力关注同一主题集的每个图像。
(3)个性化文本到图像生成
个性化作为修复:给定一些文本-图像对作为参考,生成新的个性化样本的任务被视为对包含参考图像的联合图像集的缺失图像进行修复。图像引导:在采样过程中除了使用文本引导外,还使用了图像引导,显著提高对输入参考图像的保真度。

三、结果

四、结论
本文提出了 JeDi,展示了如何使用耦合的自注意层来适应单个图像扩散 U-Net ,学习联合图像分布。为了训练联合图像扩散模型,构建了一个名为 S3 的合成数据集,其中每个样本都包含一组共享相同主题的图像。实验结果表明, JeDi 模型在定量和定性上都优于以前的方法。
五、思考
JeDi模型的无微调方法不更新权重,通过跨图像特征对齐和执行重采用策略实现个性化生成。