来源:ECCV 2024
作者:Shilong Liu、Zhaoyang Zeng、Tianhe Ren、Feng Li、Hao Zhang…
单位:IDEA
一、背景
传统目标检测模型如 Faster R-CNN 或 DINO,主要是 闭集目标检测(Closed-set Object Detection):只能识别训练时见过的固定类别。而现实世界中存在大量“开放类别”,因此需要能处理 开放集目标检测(Open-set Object Detection, OOD)的模型。
因此,本文目标是构建一个可通过人类语言输入检测任意物体的开放集目标检测模型 —— Grounding DINO。
二、贡献
- 提出 Grounding DINO 模型:结合 DINO 的 Transformer 检测架构与 grounding 预训练,支持以自然语言检测任意物体。
- 三阶段模态融合机制:在Neck、Query 初始化与 Decoder 中均实现语言与图像特征融合,即紧耦合模态融合(tight modality fusion)。
- 子句级文本表示:提出Sub-sentence文本表示法,通过 attention mask 屏蔽无关类别间干扰,提升语言特征表达能力。
- 支持指代表达检测任务(REC):扩展开放集检测模型用于 RefCOCO/+/g 等任务。
三、方法
- 整体架构
Grounding DINO 采用双编码器 + 单解码器的结构:图像编码器使用 Swin Transformer 提取多尺度图像特征,文本编码器使用 BERT 提取文本 token 向量。随后通过特征增强器进行多模态融合,再使用语言引导的 query 选择模块生成检测 query,最后经由跨模态解码器输出目标框及对应文本。
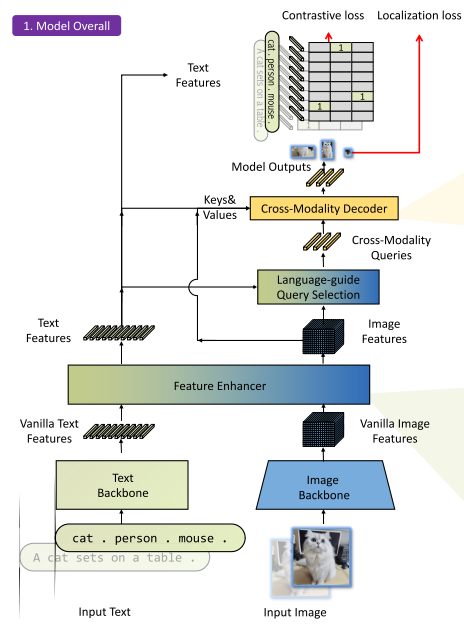
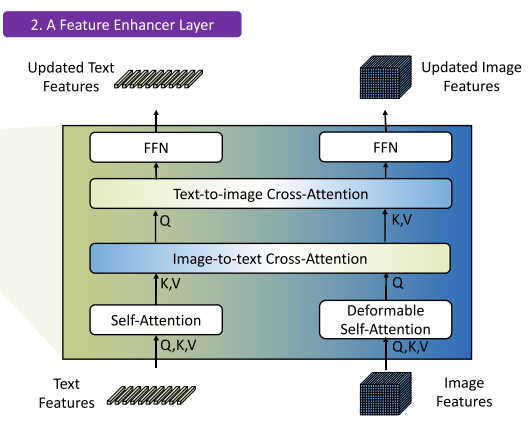
2. 特征增强器(Feature Enhancer)
该模块对图像特征和文本特征进行交叉融合,由多层堆叠组成:
- 图像通道:使用 deformable self-attention 提升图像空间建模能力;
- 文本通道:使用 vanilla self-attention 提取上下文语义;
- 图文融合:通过 image-to-text 和 text-to-image cross-attention 实现跨模态对齐,增强局部与全局语义理解。
3. 语言引导的 Query 选择(Language-Guided Query Selection)
该模块从图像编码特征中选出与文本最相关的若干区域作为 decoder 输入的初始 query:
- 首先计算图像特征与文本特征的相似度矩阵;
- 对每个图像位置取其与所有文本 token 的最大相似度;
- 按得分选出前 Nq(如 900)个位置;
- 生成对应的 content 和 positional query(其中位置采用动态 anchor box 初始化,内容部分为可学习参数)。
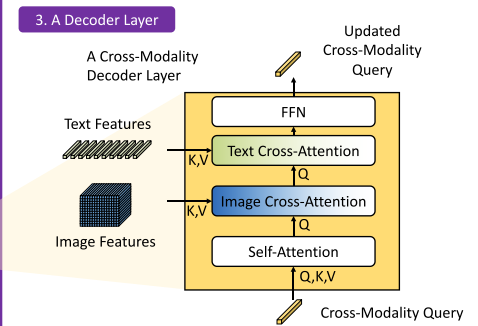
4. 跨模态解码器(Cross-Modality Decoder)
每层解码器包含四部分:
- 自注意力层(Self-Attention);
- 图像 cross-attention(从图像特征中提取相关区域);
- 文本 cross-attention(增强语言语义对 query 的指导);
- FFN(前馈神经网络)更新 query 表征。
与 DINO 相比,该解码器引入额外的文本 cross-attention,使每层都注入语言信息。
5. 子句级文本表示
针对多个类别名拼接为句子的情况,该方法引入 attention mask,阻止不同类别词之间产生注意力联系:
- 避免无关词之间互相干扰;
- 同时保留每个词的独立向量,提升细粒度的语义表示能力;
- 在 grounding 训练中更符合检测类 token 的使用场景。
6. 损失函数设计
采用 DETR 系列的标准损失组合:
- 边界框回归:L1 + GIOU Loss;
- 目标分类:query 与所有文本 token 做点积得到预测 logits,使用 Focal Loss 进行 supervision;
- 使用 Hungarian 匹配(基于分类损失 + 回归损失)决定正负样本对齐关系;
- 每层 decoder 和 encoder 输出均加入辅助损失(auxiliary loss)以稳定训练。
四、实验
- Zero-shot Transfer 零样本迁移
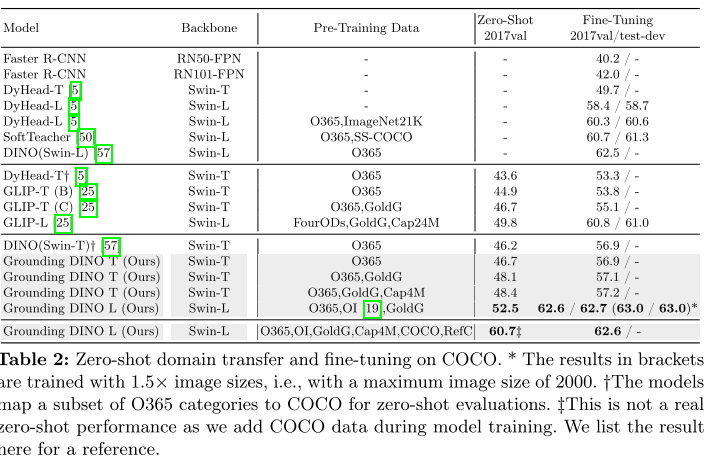
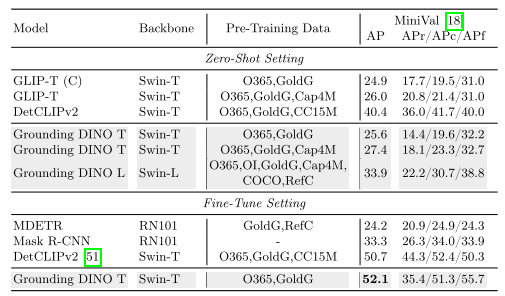
- COCO:Zero-shot 下达成 52.5 AP,优于 DINO 和 GLIP
- LVIS:在常见类别表现优于 GLIP,但在稀有类别略逊
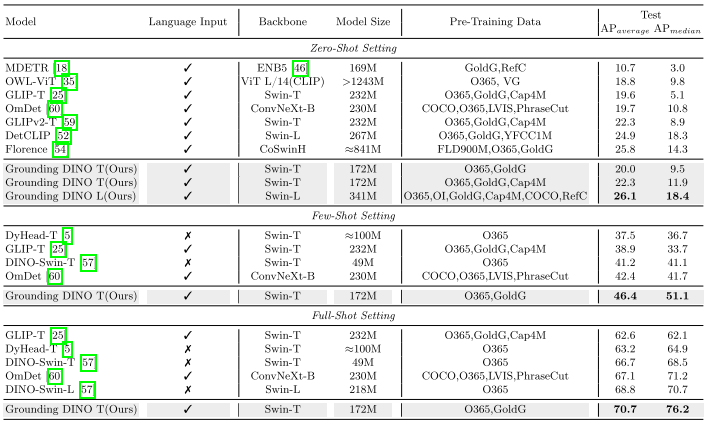
- ODinW:在 35 个真实世界数据集中平均 AP 达 26.1,超过 Florence 等大型模型
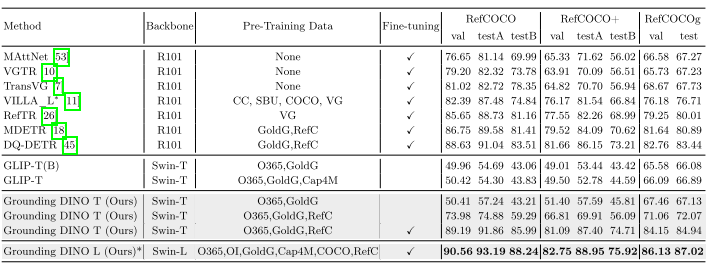
2. Referring Expression Comprehension
未微调时效果一般;加入 RefCOCO 训练后大幅提升,提示当前模型在细粒度检测任务仍有发展空间
五、总结
Grounding DINO 是开放集检测领域的重要进展。通过对 Transformer 检测器的多模态扩展与语言感知机制设计,展现出强大的通用性和扩展性。在图文结合检测、指代理解等任务中具备领先性能。未来工作可进一步拓展到实例分割、多模态编辑、复杂视觉问答等场景。