作者:Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, Tim Rockta ̈schel
单位:Google DeepMind
来源:ICML 2024
近年来,随着深度学习技术的发展,特别是大型语言模型(LLMs)的进步,自然语言处理的能力得到了显著提升。这些模型能够在各种任务上实现先进的性能,包括文本生成、问答系统等。
提示是基础模型下游性能的核心。该文章提出一种通过多样性保持进化算法来解决收益递减问题的解决方案,用于 LLM 提示的自我引用自我完善。
即Promptbreeder,一个提示进化系统,可以自动探索给定领域的提示,并且能够找到任务提示,从而提高 LLM 获得该领域问题的答案的能力。Promptbreeder 是通用的,因为同一个系统能够适应许多不同的领域。
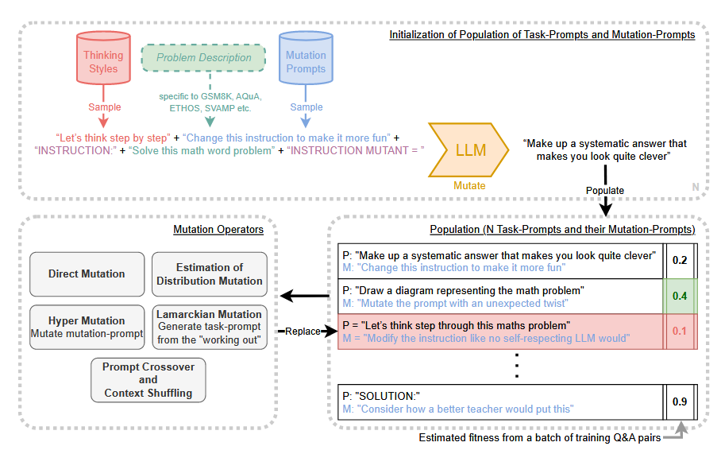
具体的例子,考虑用于为 GSM8K(一个 “小学数学 ”单词问题数据集)生成任务提示和突变提示的初始化步骤:
问题描述是“解决数学单词问题,以阿拉伯数字形式给出您的答案”。
在每个进化单位进化了两个任务提示(加上一个突变提示)。为了促进初始提示的多样性,通过将随机绘制的“突变提示”(例如“Make a variant of the prompt”)和随机绘制的“思维风格”(例如“Let’s think step by step”)连接到问题描述来生成初始任务提示,并将其提供给 LLM 以产生延续,从而产生初始任务提示。
我们这样做两次,以便每个单元生成两个初始任务提示。突变提示和思维方式都是从一组初始突变提示和一组思维方式中随机抽样的。
mutation-prompt 被添加到进化单元中,因此在整个进化运行过程中与其特定的 task-prompt 相关联。
在上面的示例中,用于生成初始任务提示的 LLM 的完整输入字符串可以是 “Make a variant of the prompt.让我们一步一步来思考。说明:解决数学单词问题,以阿拉伯数字形式给出您的答案。指令突变:“。请注意如何添加控制字符串 “INSTRUCTION” 和 “INSTRUCTION MUTANT” 以鼓励适当的延续。
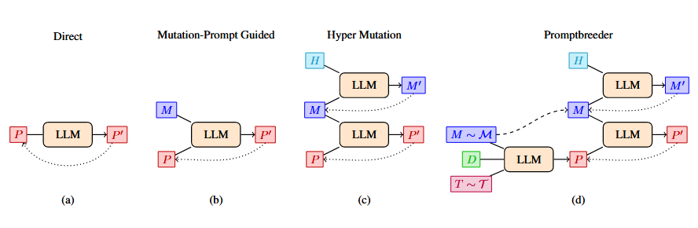
从一个现有的任务提示 P(一阶提示生成)或鼓励自由生成新任务提示的通用提示生成一个新的任务提示 P ′ – 即不使用现有的父级,因此是零阶提示生成。
零阶提示生成:通过将问题描述 D与提示连接起来来生成一个新的任务提示,它邀请 LLM 提出一个可以帮助解决给定问题域中的问题的新提示。将第一个生成的 hint 提取为新的任务提示符。这个新的任务提示符不依赖于以前找到的任何任务提示符。相反,每次都会从问题描述中重新生成它。
包含这个零阶运算符的基本原理是,当提示进化发散时,这个运算符允许生成与原始问题描述密切相关的新任务提示,类似于自动化课程学习方法中的统一重新采样。
一阶提示生成:将 mutation-prompt(红色)连接到父 task-prompt(蓝色),并将其传递给 LLM 以生成 muted task-prompt。例如,“以另一种方式再次说出该指令。不要使用原始说明中的任何单词,这是一个很好的小伙子。说明:解决数学单词问题,以阿拉伯数字给出您的答案。指令突变体:“.此过程与初始化方法相同,只是不使用随机采样的思维样式字符串。一阶提示生成是 Promptbreeder 的标准无性突变运算符,它是每个遗传算法的核心——采用一个亲本基因型(任务提示)并将突变应用于它(在这种情况下受突变提示的影响)。
分布突变的估计下一类突变运算符不仅以零个或一个父级为条件,还以一组父级为条件。
因此,通过考虑总体模式,它们可能更具表现力。 分布估计(EDA)突变:受Hauschild和Pelikan(2011)的启发,我们向LLM提供了一份过滤和编号的当前任务提示列表,并要求它继续这个列表,使用新的任务提示。根据BERT过滤提示的群体,嵌入彼此之间的余弦相似性——如果一个个体与列表中的任何其他条目的相似度超过0.95,则不会被包含在列表中,从而鼓励多样性。提示以随机顺序列出,我们不会让 LLM 访问总体中个体的适应度值——我们在初步实验中发现 LLM 不理解这些适应度值3,并求助于在列表中生成条目的副本。
实验设置
数据集:
GSM8K, SVAMP, MultiArith, AddSub, AQuA-RAT, SingleEq等算术推理数据集。
CommonsenseQA, StrategyQA用于常识推理。
指令归纳任务和其他分类任务。
实验设计:
使用的种群大小、世代数及评估方法。
LLM采样的三种不同上下文:Redescriber, Inducer, Evaluator。
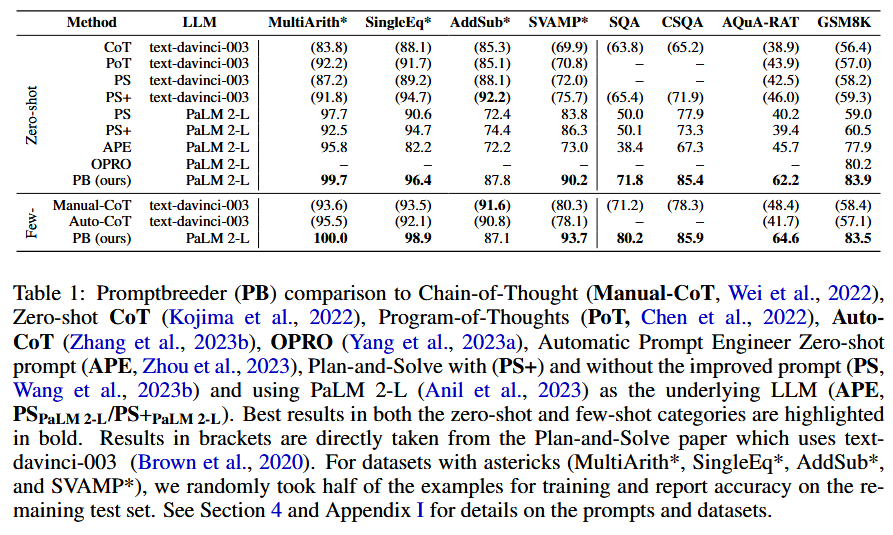
核心内容总结:
1 提出了Promptbreeder,一种用于 LLM 的自我引用自我改进方法,它为目前的领域改进提示,并改进了它改进这些提示的方式,并且能够延伸上下文。
3 该方法核心是通过一个遗传算法来生成和优化提示。
3 文章中对部分广泛的常用算法和常识推理基准上对最先进的提示策略提出了改进。