作者:Lin Chen,Peipei Wang,Xiaohui Han,Lijuan Xu
单位:计算能力网络与信息安全教育部重点实验室,山东省计算机科学中心(国家超级计算机济南中心)
来源:ICASSP 2025 – 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
一、研究背景
1. POI 推荐的重要性
信息过载问题:在海量的 POI 信息中,用户往往难以快速找到自己真正感兴趣的地方。
提升用户体验:有效的 POI 推荐可以帮助用户发现他们可能喜欢的地点,节省搜索时间,提高在 LBSN 上的体验满意度。
应用场景:为游客推荐附近的旅游景点、为居民推荐适合的餐厅或休闲场所等,具有广泛的 应用价值。
2. 下一步 POI 推荐
定义:下一步 POI 推荐是 POI 推荐的一个子领域,它专注于根据用户的历史轨迹(即用户过去的签到序列)来预测用户接下来可能访问的 POI。
时间连续性:在现实场景中,用户访问 POI 的行为通常是时间上连续的,具有一定的顺序和模式。例如,用户可能在上午访问咖啡馆,然后在下午去附近的图书馆。
关键挑战:如何充分利用用户的历史轨迹信息,准确捕捉用户在不同时间、不同地点之间的潜在转移偏好,是实现准确下一步 POI 推荐的关键。
现有方法的局限性:
1、大多忽视了POI间高阶的语义联系,仅从单一视角挖掘,难以深入理解序列信息的潜在语义。
2、不少基于图神经网络(GNN)的模型,过于侧重直接相邻节点,导致高阶邻居信息未被充分利用,进而引发信息丢失,使得节点表示不够精准,影响推荐效果。
研究目标:
本研究旨在提出一种基于图的多关系变分对比学习(MRVCL)方法,致力于从局部关联和全局依赖两个维度,挖掘用户移动的多语义关系,以解决现有方法因信息利用不充分而导致的表示欠佳问题,从而提升POI推荐的准确性。
二、技术思想
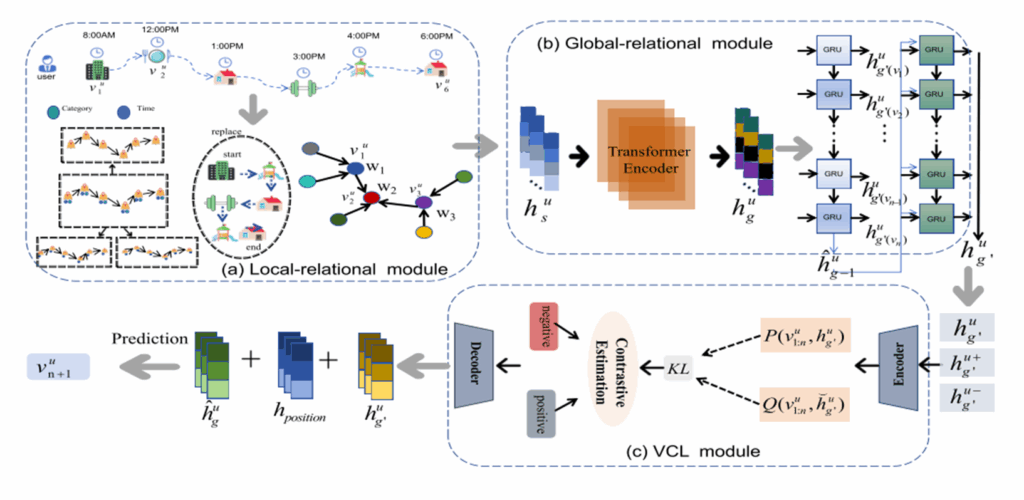
a.无序局部关系自适应加权模块
在POI图构建中,传统方法仅依赖直接相邻节点,难以高效利用高阶邻居信息。本文提出的无序局部关系自适应加权模块不依赖节点邻居的顺序,可以更好地利用节点的多步邻居信息。
节点表示更新:在图神经网络(GNN)中,节点的表示会根据其邻居节点的信息进行更新。对于第l层,节点i的表示为:
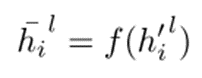
引入注意力机制:在GNN的基础上,引入注意力机制来动态地为不同邻居节点分配权重。节点i的表示更新为:
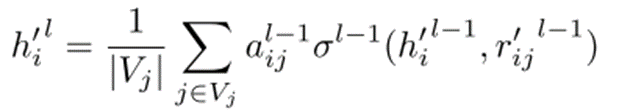
注意力权重计算:注意力权重是根据两个节点的相似性来计算的。我们使用LeakyReLU函数和可训练的矩阵来计算节点间的相似性:
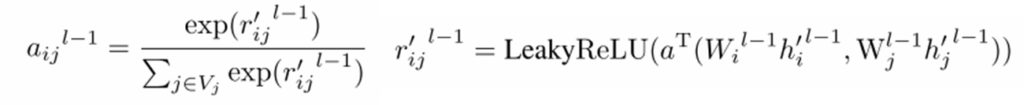
可训练矩阵的作用:设计一个可训练矩阵Wij来进一步优化节点间关系的表示。通过结合这个矩阵,实现了无序局部关系自适应加权:
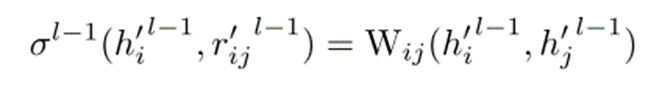
b.无序局部关系自适应加权模块
Transformer编码器的应用
输入序列表示:将拼接后的节点序列表示hs输入到Transformer编码器中。这个输入序列包含了各个节点的表示,这些表示已经通过无序局部关系自适应加权模块进行了优化,捕捉到了节点间的局部相似关联。
Transformer编码器的作用:Transformer编码器通过其自注意力机制,能够捕捉序列中节点间的协作信号和复杂的相互关系。它会根据节点在整个序列中的位置和内容,动态地为每个节点分配权重,从而得到一个更丰富的全局上下文表示 hg。这个过程可以表示为:
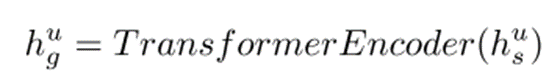
输出结果:输出的 hug 是一个经过 Transformer 编码器处理后的全局上下文表示,它包含了序列中各个节点之间的复杂关系,为后续的建模提供了更丰富的信息。
GRU网络的引入与整合
整合时间嵌入和用户偏好信息:为了进一步增强对长距离依赖的建模能力,将 Transformer 输出 hug 与时间嵌入 hut 和用户偏好信息 hua 进行拼接。时间嵌入用于捕捉用户访问 POI 的时间模式,而用户偏好信息则反映了用户的长期兴趣。拼接后的向量形式为:
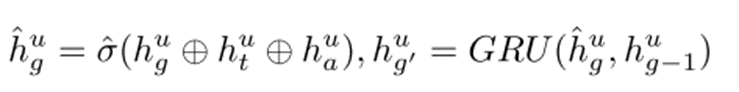
其中,σ^ 表示一个非线性激活函数,用于引入非线性特性;⊕ 表示向量拼接操作。
GRU网络的作用:将拼接后的向量 hug输入到 GRU 网络中,利用 GRU 的隐藏状态来捕捉序列中的动态变化和长期依赖关系。GRU 网络通过其内部的更新门和重置门机制,能够有效地控制信息的流动和更新,从而得到一个更加优化的全局上下文表示 hug ′。
输出结果:最终得到的 hug ′ 是一个融合了时间信息、用户偏好信息以及序列中长距离依赖关系的全局上下文表示,它能够为后续的预测任务提供更全面、更准确的用户行为模式描述。
c.生成变分-对比学习
先验分布构建:将GRU网络的输出特征通过一个概率生成模型转换为先验分布 P,这一步骤捕捉了用户基于历史行为可能访问下一个POI的潜在概率分布。
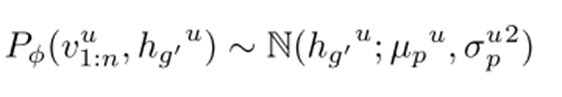
后验分布近似:利用变分推断的方法,通过另一个网络学习后验分布 Q,使其尽可能接近先验分布 P,同时结合实际观察到的用户访问序列信息,对后验分布进行优化。
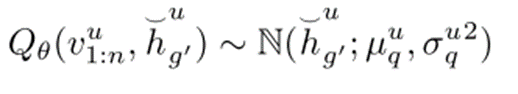
对比学习优化:利用对比学习目标函数,对先验分布和后验分布进行优化。通过这种方式,我们能够使模型在潜在空间中将相似的用户偏好和行为模式拉近,同时将不相似的模式推远,从而提升特征表示的质量和模型的泛化能力。
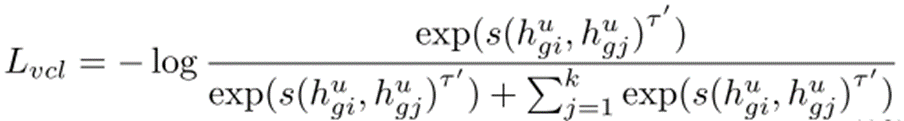
d.预测与优化
预测模型:将hug输入到一个单层的多层感知机(MLP)中,并通过softmax函数将其映射为各个POI的访问概率分布。具体公式为:
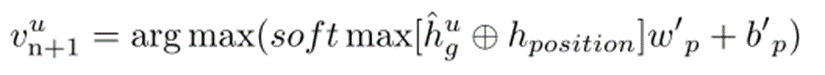
其中,hposition 表示位置嵌入,用于捕捉用户的地理位置偏好;wp′ 和 bp′ 分别是MLP的权重矩阵和偏置项。
损失函数与优化:
损失函数:采用交叉熵损失函数来衡量预测结果与真实标签之间的差异。公式为:
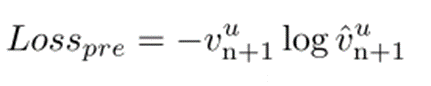
优化方法:使用Adam优化器对模型进行训练,通过最小化损失函数来更新模型参数。Adam优化器结合了动量和自适应学习率的优点,能够有效地加速模型的收敛过程。
三、实验
数据集

基线模型
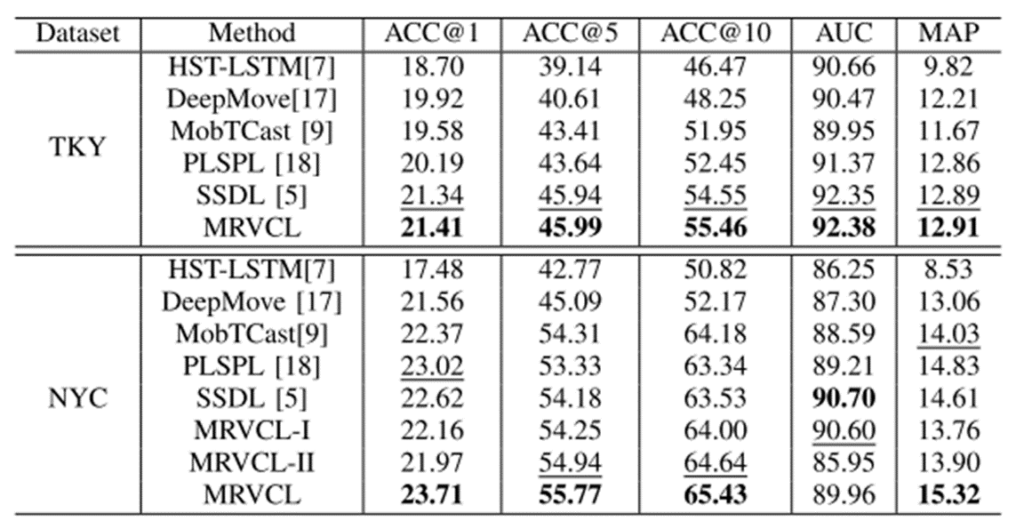
•HST-LSTM:基于LSTM的层次时空长短期记忆网络,用于捕捉用户的行为序列模式。
•DeepMove:基于注意力机制的RNN模型,通过注意力机制突出显示序列中重要的POI。
•MobTCast:基于Transformer的上下文模型,利用Transformer的自注意力机制捕捉全局依赖关系。
•PLSPL:基于影响的LSTM模型,考虑了用户行为的影响因素来预测下一步POI。
•SSDL:基于GRU的自监督模型,通过自监督学习来捕捉用户的行为模式。
评估指标
•ACC@K:衡量在推荐列表的前K个POI中包含正确POI的比例,K取1、5、10等不同值,用于评估模型的准确率。
•AUC:评估模型对正负样本的区分能力,值越接近1表示模型性能越好。
•MAP:衡量模型在所有用户上的平均精度,综合考虑了推荐列表中正确POI的位置和数量。
四、总结与思考
研究结论:
设计无序局部关系自适应加权模块,不依赖节点邻居顺序,利用可训练矩阵和注意力机制动态学习节点间关系,实现自适应加权,更好地利用多步邻居信息。
上下文感知全局关系编码模块结合Transformer编码器和GRU网络,捕捉签到序列中的长距离依赖和全局上下文信息,增强对用户行为模式的理解。
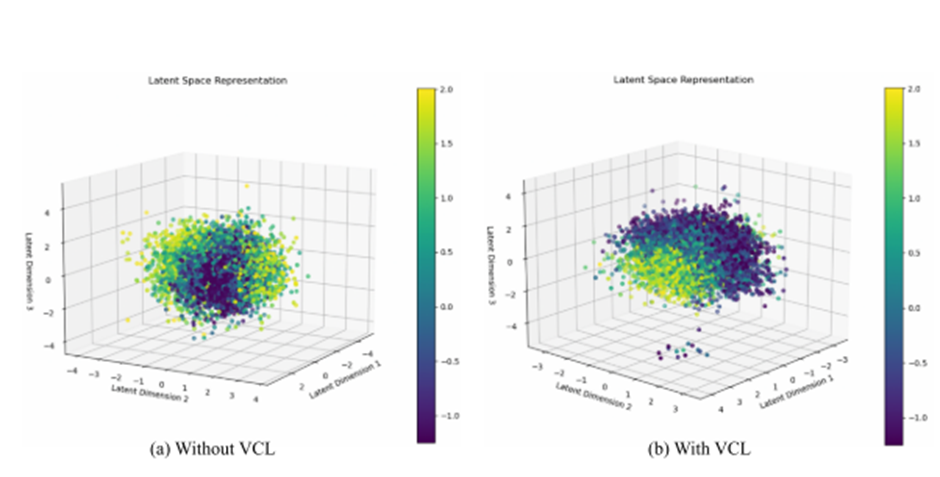
引入生成式变分对比学习模块:构建先验分布和后验分布,通过对比学习目标函数优化特征表示,提升模型的泛化能力。
挖掘POI隐含关系:MRVCL建图不仅基于用户访问轨迹(行为顺序),还包括:POI类别相似性、时间共现、地理接近性、用户共现、热门POI间的结构迁移。
无序图结构聚合:MRVCL 的本地图结构是无序的(不依赖轨迹顺序),可以增加多阶 GAT 聚合(2-hop, 3-hop),或者使用 全连接图结构 Attention Pooling 形式,对用户历史 POI 图做全局图注意力。
Transformer + GRU 组合:MRVCL 使用了 GRU 提取时序上下文 + Transformer 提取长程依赖,避免了Transformer 在短序列中不稳定或注意力过平。
使用对比学习(VCL)提升表示判别性:MRVCL 用 VAE 构建 latent distribution q(z|x),使表示空间具有判别性与泛化能力;同时引入 KL 散度约束 + 对比损失。