作者:Lior Shabtay,Philippe Fournier-Viger,Rami Yaari,Itai Dattner
发表期刊:Information Sciences
发表日期:2021年
一、背景
频繁项目集挖掘的重要性与局限性
传统算法(Apriori、Eclat、FP-Growth)设计目标是发现所有频繁项目集,但实际应用中用户往往只关心特定子集。
现有算法在大型或密集数据集上处理时间长,可能发现数千个项目集但用户仅需少量结果。
目标导向挖掘需求的兴起
用户需求从”挖掘所有模式”转向”挖掘特定目标模式”,现有目标挖掘方法存在性能瓶颈,需要更高效的解决方案。
不平衡数据处理的挑战
传统类关联规则挖掘算法在处理不平衡数据时需要设置极低的最小支持度,导致性能急剧下降。
二、创新点
理论贡献
首次提出目标导向的频繁模式挖掘理论框架,突破传统”全量搜索”局限
创新TIS-tree数据结构,为精准数据挖掘提供新的算法基础
技术突破
解决不平衡数据中少数类规则挖掘的效率瓶颈
实现内存减少30-40倍、时间减少100倍的显著性能提升
三、GFP-Growth算法

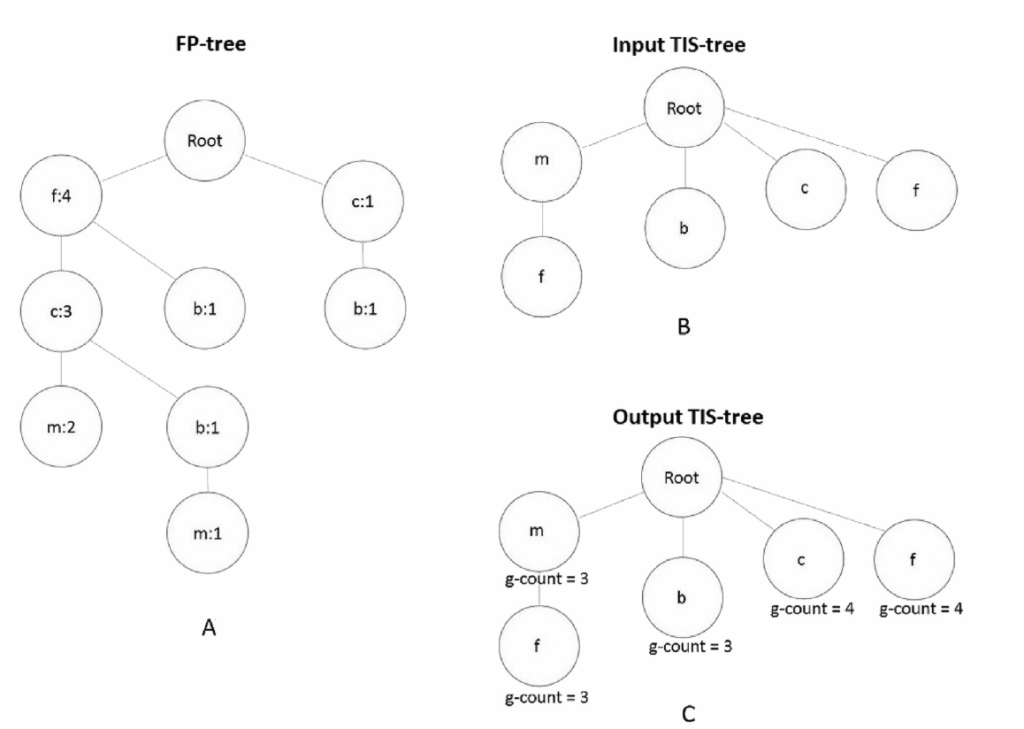
(A) FP-tree: 根据示例数据构建的标准FP-tree结构
(B) 输入TIS-tree: 存储用户指定的目标项目集{f}、{m}、{b}、{c}、{m,f}
(C) 输出TIS-tree: 执行算法后每个目标项目集标注了支持度计数(g-count)
四、MRA算法的FP-tree构建

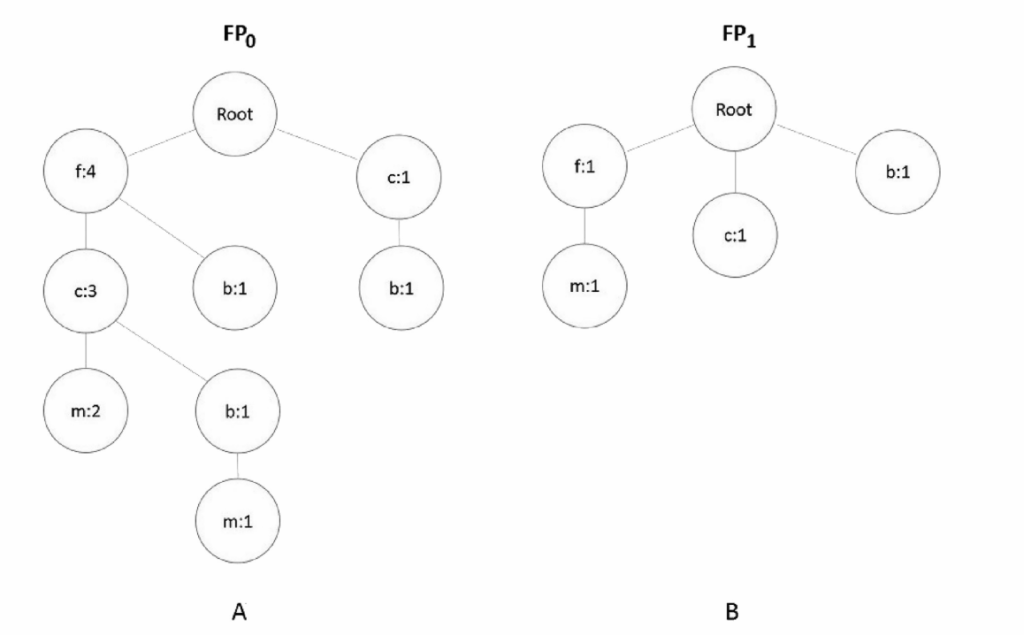
(A) FP0: 多数类(类0)数据构建的FP-tree,结构复杂
(B) FP1: 少数类(类1)数据构建的FP-tree,结构简单
作用: 分别处理不平衡数据的两个类别
五、TIS-tree的构建和更新过程
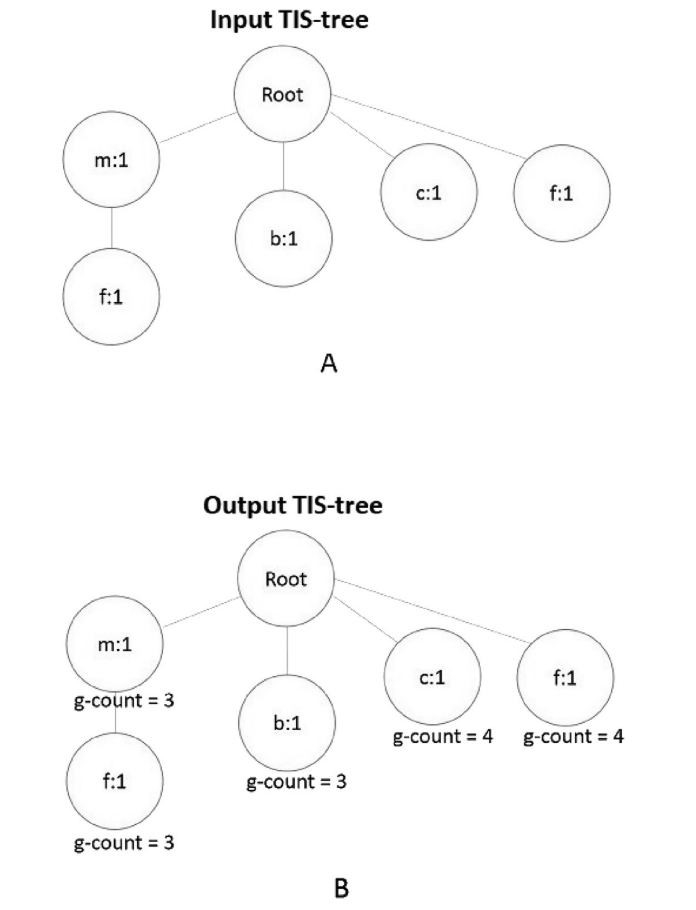
(A) 输入TIS-tree: 从少数类FP1中提取的频繁项目集
(B) 输出TIS-tree: 用GFP-Growth处理多数类后,标注了最终计数值
目的: 展示MRA算法的完整处理过程
六、实验以及实验结果
实验分为三个层次的验证:
模拟数据实验:控制变量验证算法基本性能
真实数据实验:验证算法在实际场景中的表现
对比实验:与现有先进算法的性能比较
模拟数据性能对比
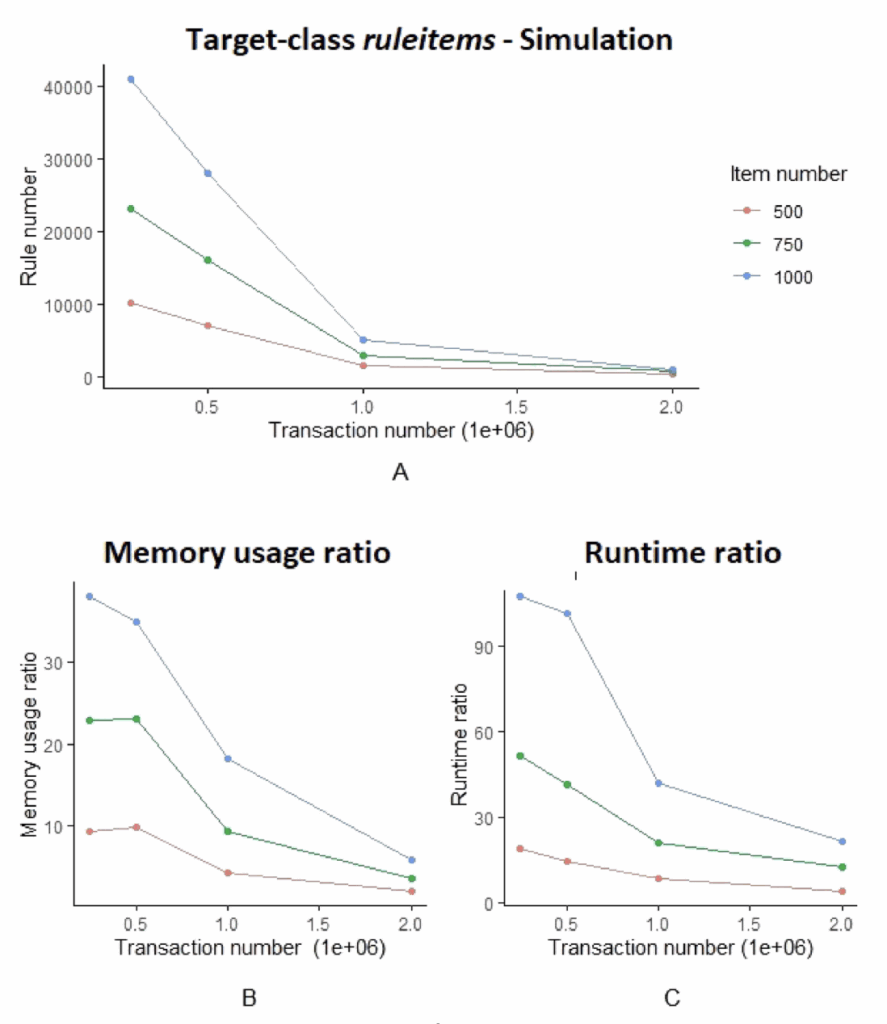
(A) 目标类规则项数量:
结果:随着事务数增加,生成规则数量减少
趋势:1000项目数据集生成规则最多,500项目最少
(B) 内存使用比率:
结果:MRA内存使用比FP-Growth减少30-40倍
趋势:项目数越多,MRA的内存优势越明显
(C) 运行时间比率:
趋势:数据规模越大,时间优势越显著
真实数据性能对比(Chainstore数据集)
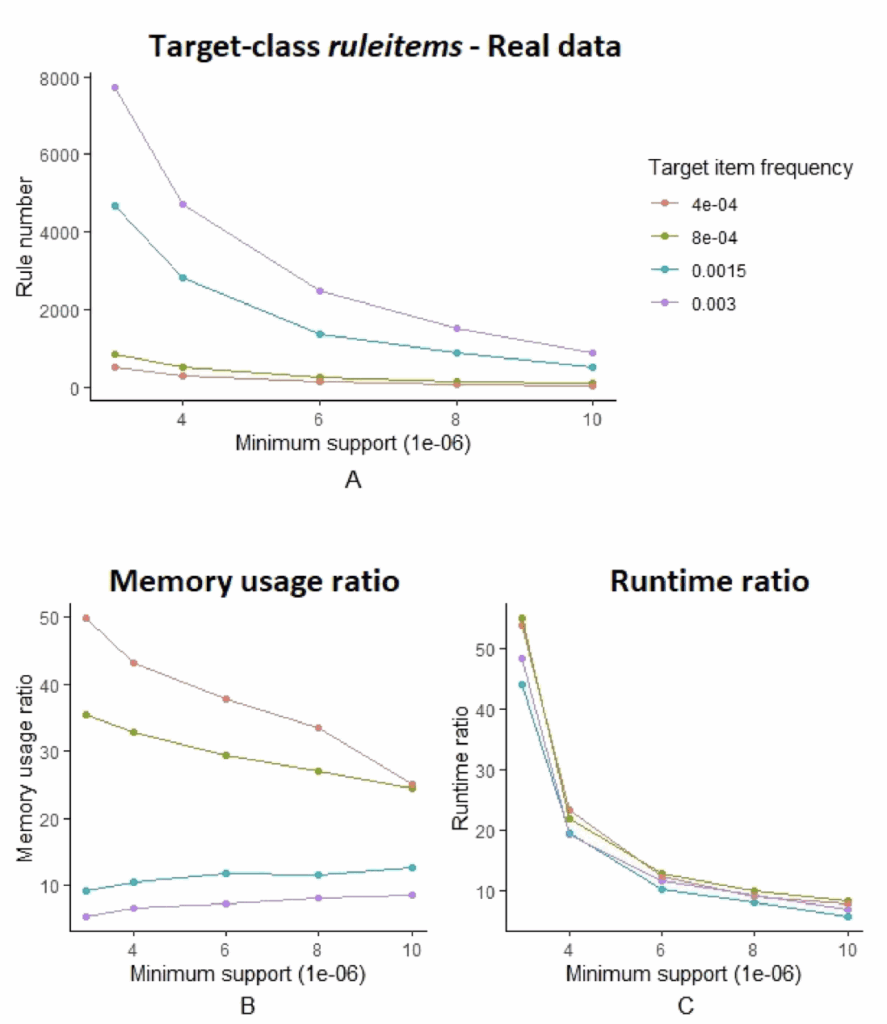
(A) 目标类规则项数量:
趋势:支持度降低时,规则数量呈指数增长
验证:两算法生成相同数量规则,保证结果一致性
(B) 内存使用比率:
频率影响:目标项目频率越低,内存优势越明显
稳定性:在不同支持度下都保持显著优势
(C) 运行时间比率:
关键发现:FP-Growth运行时间随支持度降低呈指数增长
Lymph数据集算法比较
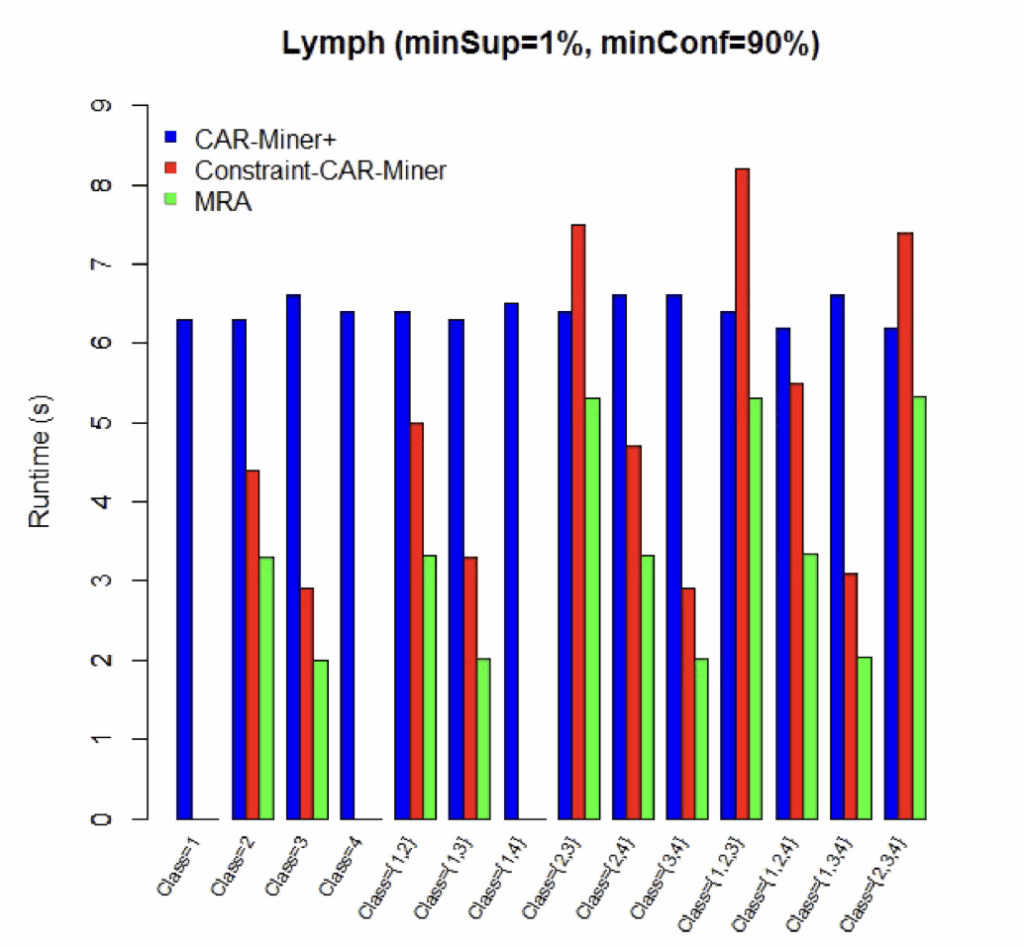
性能比较:
少数类(类1、4):MRA运行时间接近0,与Constraint CAR-Miner相当
多数类(类2、3):MRA比两个对比算法都更快
多类查询:MRA在组合查询中保持最佳性能
整体优势:在所有测试场景中MRA都表现最优或相当
German数据集算法比较
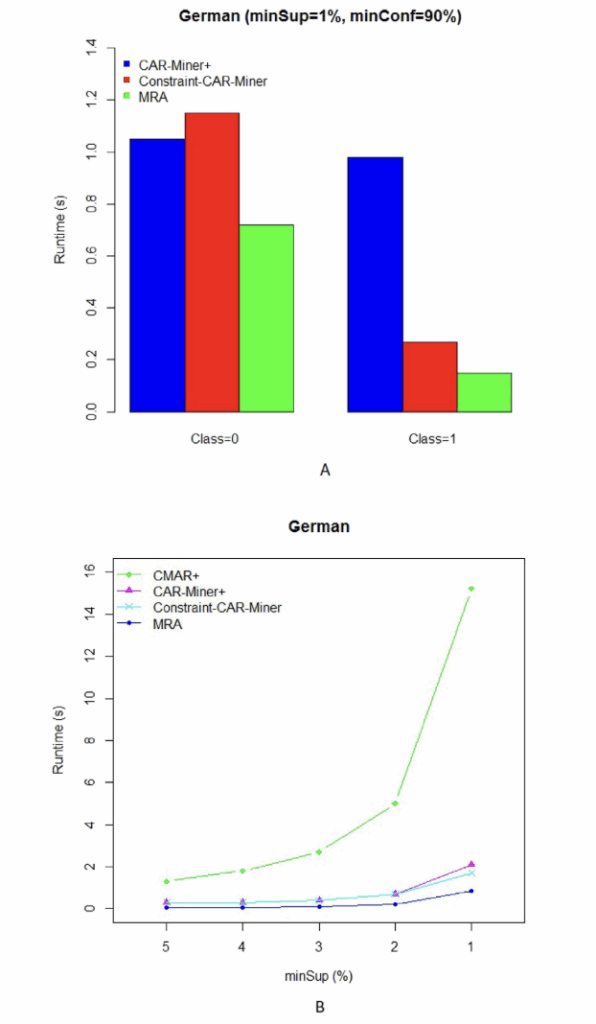
(A) 单类性能比较:
Class-0:MRA性能最优
Class-1:MRA显著优于其他算法
一致性:在两个类别上都保持优势
(B) 支持度敏感性分析:
关键发现:其他算法时间复杂度随支持度降低呈指数增长
MRA稳定性:性能曲线相对平缓,受支持度影响小
实用性:在实际应用的低支持度场景下优势突出
七、总结
这篇论文提出GFP-Growth算法(引导FP-Growth)和少数类报告算法(MRA):引入TIS-tree(目标项目集树)数据结构,只针对用户感兴趣的项目集进行挖掘;通过分别构建少数类和多数类的FP-tree,优化不平衡数据处理。
在模拟和真实数据集上验证性能:内存使用减少30-40倍;运行时间减少高达100倍;在不平衡数据场景下相比传统算法有显著优势。