来源: AAAI 2025
作者: Guo Wenxiang,Zhao Zhou等
单位: 浙江大学
一、论文主要工作及贡献
现有歌声合成方法很少提供对强度等声音技术的精确控制,限制了合成声音的表达潜力,对此这篇文章提出TechSinger,支持五种语音和其中人声技术,利用基于流匹配的生成模型增强对各种技术的控制。开发了技术检测模型,自动用音素级技术标签注释数据。实验结果表明,Techsinger显着增强了合成歌声的表现力和现实性,从音频质量和特定技术控制方面优于现有方法。
二、模型框架
TechSinger模型框架:

技术检测器:

三、实验以及实验结果
数据集:GTSinger数据集包括汉语、英语、西班牙语、德语和法语子集。并在音素和句子水平收集并注释了30个小时的汉语数据集,包括两名歌手和四个技术注释(强度、真假声、气音和气泡音)
评价指标:客观指标(F0帧误差,MCD),主观指标(MOS-Q,MOS-C)
基线模型:DiffSinger,VISinger2,StyleSinger
实验结果:
和基线系统比较:

不同的控制策略:

不同文本表示:

mel谱图和F0可视化图:

TechSinger在不同技术下的mel谱图:

消融实验:
技术检测器消融实验:

不同组件的消融:
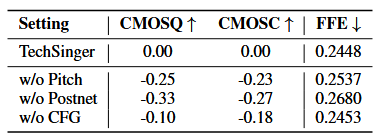
四、总结与思考
(一)、论文的核心内容:
- 提出基于流匹配的F0预测器,捕获各种声音技术的细微差别;
- 无分类器指导的流匹配后网将粗mel谱图改进到细mel谱图。
(二)、综合对齐思考:
- 普通话中,F0的变化体现在声调上,从而影响语音可懂度,基于流匹配的F0预测器有借鉴价值。