来源: arXiv 2025-04-29
作者: Jeongsoo Choi,Ji-Hoon Kim,Joon Son Chung等
单位: 韩国科学技术院
一、论文主要工作及贡献
多模态语音生成旨在从多模态(如文本,视频和参考音频)输入中生成该质量语音,现有方法受到语音清晰度、音视频同步、语音自然性和与参考音频之间的说话人相似性的局限。对此这篇文章提出AlignDiT,从多模态对齐输入中产生准确、同步和自然的音频,探索了三种对齐多模态表示的策略,引入多模态分类器指导机制。广泛实验表明,在质量、同步和说话人相似性方面,AlignDiT显著优于现有方法,并在唇语到语音合成和视觉强制对齐上达到sota水平。
二、模型框架
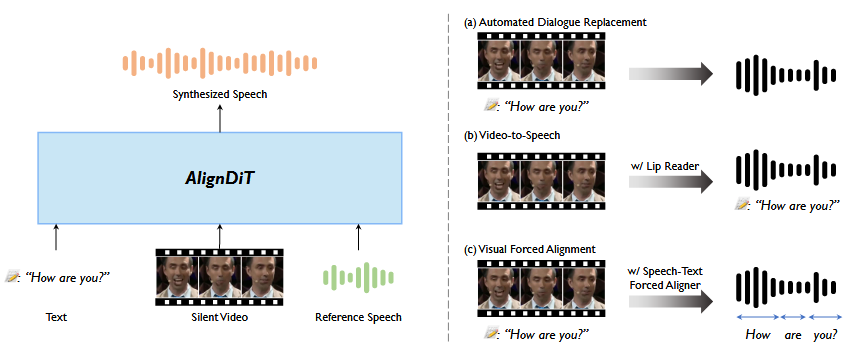
模型目标是根据文本脚本内容和参考音频的说话人特征,生成和视频中唇语相匹配的语音。模型基于DiT,使用流匹配的目标训练模型,从随机噪声开始迭代推理生成Mel谱,对于多模态语音生成,使用融合的多模态表示作为条件指导生成过程。多模态条件
多模态条件
音视频融合:音频在100fps下转换为mel谱,通过反卷积将25fps的视频特征上采样到100fps,使用Conformer编码器更好的捕获上下文信息。对mel采用二进制掩码,随机选择掩蔽跨度增强模型内在学习能力,对视频特征采用互补掩蔽。
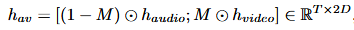
音视频文本融合:音视频流本质上是时间对齐的,但文本仅与其单调对齐,缺乏严格的框架级同步。以前的工作依赖外部强制对齐器和持续时间预测因子,这篇文章旨在训练生成模型自然融合模态,探索了三种策略,对所有情况先通过查找表嵌入字符序列,再由卷积编码器完善。
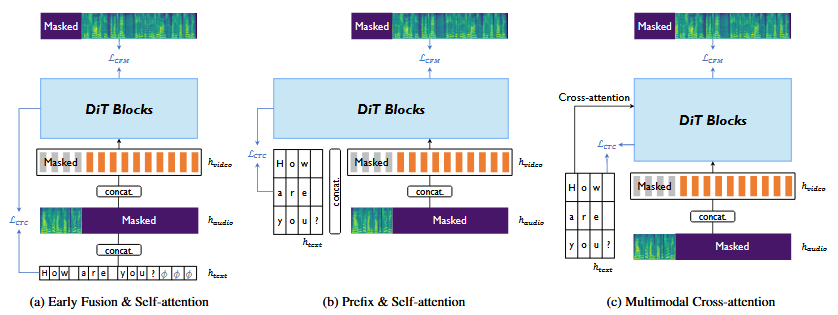
- 早期融合&自注意力:和E2-TTS一样,在文本序列末尾添加填充令牌,DiT块中的自注意层自发学习对齐。
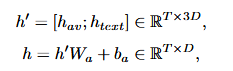
- 前缀&自注意力:将文本视为前缀,模型输出完整序列后将文本长度对应的前缀部分丢弃。
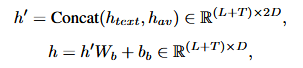
- 多模态交叉注意力:对DiT块插入自注意力之外的交叉注意力层,音视频融合标志作为查询,文本嵌入作为键和值。
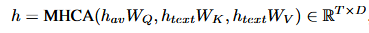
训练目标
通过多任务学习训练对齐,采用流匹配训练模型,预测向量场。
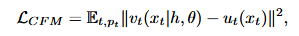
其次将轻量级投影层连接到中间DiT块引入CTC损失。
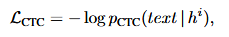
多任务损失定义为:
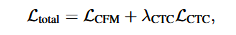
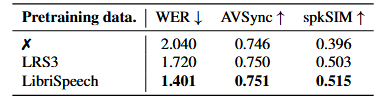
仅音频预训练
在使用视频和文本多模态条件之前,采用仅音频预训练,其被证明在文本到语音合成任务中有效。使用hubert模型特征作为教师模型,对DiT中间层进行蒸馏加快收敛速度。
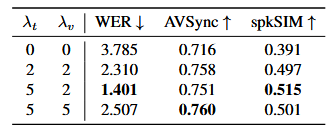
多模态无分类器指导
无分类器指导通过使用来自同一模型的条件和无条件预测来指导生成过程。
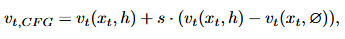
由于每种模态表现出不同的特性,对所有模态采用单个无分类器指导强度可能是次优的,这篇文章提出动态分配指导强度:
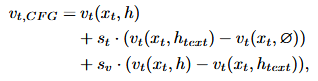
st表示文本指导强度,sv表示视频指导强度,更高的st鼓励模型更仔细遵循文本,更高sv导致更好的唇同步。
三、实验
数据集:LRS3视听数据集,包括439个小时视频,数千个说话人。构建了一个由{参考语音、文本、无声视频}组成的LRS3-cross集,参考语音来自同一说话人的不同语音,而不是使用真实语音,避免可能的信息泄露。对于唇语到语音合成,使用唇读模型从无声视频中提取文本转录。
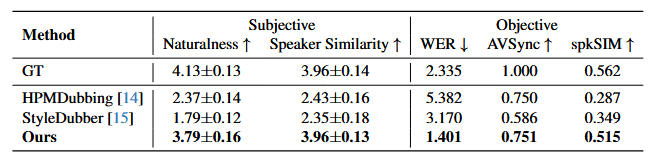
评价指标:主观指标上,对自然性和说话人相似性上进行主观打分,1表示非常差,5表示非常好。客观指标上,使用Whisper-large-v3对生成语音转录文本,计算WER评估内容准确性,使用基于WavLM-large的说话人验证模型提取的特征计算余弦相似度评估说话人相似性,使用AV-HuBERT提取的视频-音频融合特征计算余弦相似度评估视频和语音之间的同步指标。对于对齐任务,通过比较单词级时间戳来评估对齐精度。
基线模型:在ADR任务上,和HPMDubbing和StyleDubber对比,使用AV-HuBERT代替每个模型中的唇部特征提取器。在唇语到语音合成任务上,和DiffV2S、Intelligible和LipVoicer进行比较。在视觉强制对齐上,和KWS-Net、Transpotter和基于CTC的DVFA进行比较。
四、实验结果
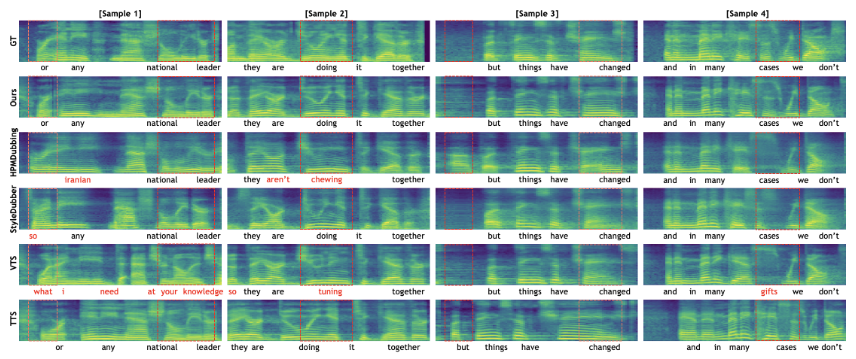
ADR任务上的实验结果:
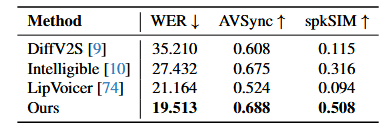
唇语到语音合成上的实验结果:
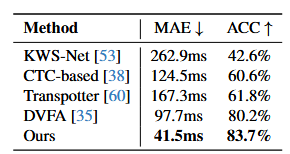
视觉强制对齐上的实验结果:
消融实验
融合策略消融:
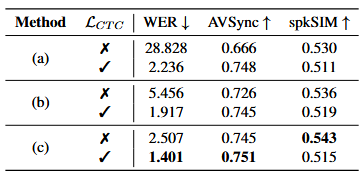
仅音频预训练消融:
多模态无分类器指导强度消融:
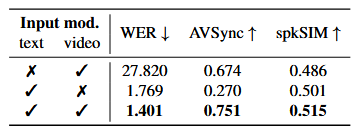
输入模态消融:
五、结论
这篇文章提出AlignDiT,用于从文本、视频和参考音频中产生准确、自然和同步的语音。探索了各种多模态对齐方式,提出了多模态无分类器指导机制,在几个基准测试中实现最先进的性能。
六、思考
- 仅音频预训练加速声学模块收敛有参考价值。
- 多模态对齐方法对加入了文本的唇语到语音合成方法有参考价值。