作者:Junying Chen, Zhenyang Cai, Ke Ji, Xidong Wang, Wanlong Liu, Rongsheng Wang, Jianye Hou, Benyou Wang.
单位:The Chinese University of Hong Kong, Shenzhen Research Institute of Big Data.
来源:arxiv
时间:2024.12
一、论文背景
1.OpenAI-o1的启发:OpenAI-o1的出现展示了通过扩展思维链(CoT)和强化学习(RL)来提升 LLM 能力的潜力。
2.医疗领域的特殊性:医疗领域的推理过程复杂且步骤不明确,验证推理过程的正确性具有挑战。与数学问题不同,医疗问题的推理过程更难以验证。
3.前人工作的不足:现有方法主要集中在数学推理,缺乏在医疗等专业领域的探索;已有的医疗 LLM 主要通过 Prompting 或海量数据训练实现,没有着重提升模型的推理能力。
二、主要内容
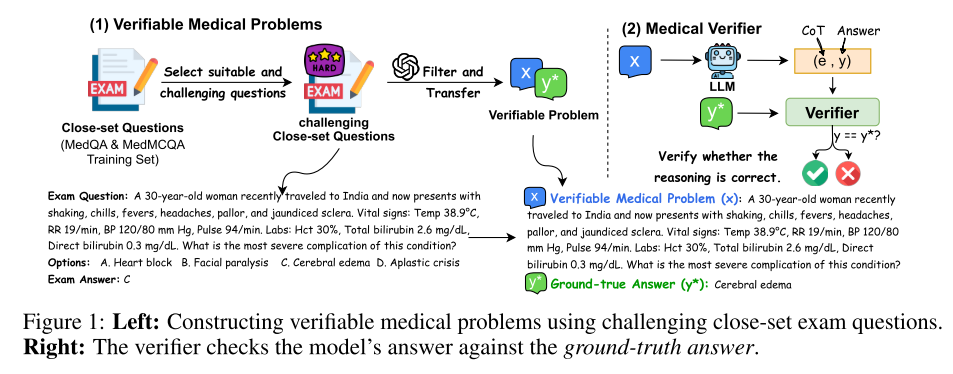
1.可验证的医疗问题:
灵感来源:借鉴数学问题可以通过最终答案来验证推理过程的做法。
方法:将医学考试的客观题(有标准答案)转化为开放式的可验证问题。
2.两阶段训练方法:
(1)学习复杂推理:
策略引导的搜索:使用验证器(Verifier)的反馈,指导模型探索不同的推理路径,直到找到正确的答案。
微调 LLM:利用成功的推理路径微调 LLM,使其具备复杂推理能力。
(2)增强复杂推理:
强化学习:使用验证器提供的稀疏奖励,通过近端策略优化(PPO)算法进一步优化模型的推理能力。
3.医疗验证器(Medical Verifier):
作用:判断模型生成的答案是否正确。
实现方式:使用 GPT-4o 作为验证器,并给出详细的 Prompt。
输出:返回一个二元反馈(True 或 False)。
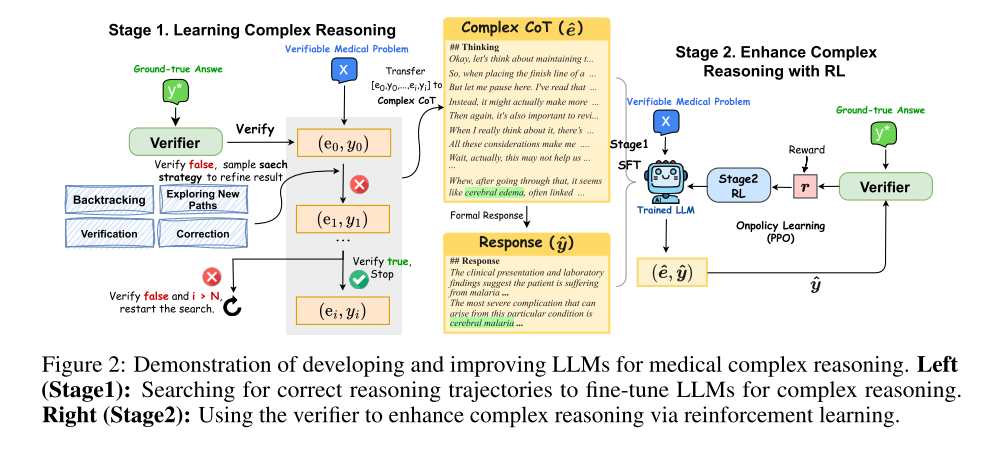
4.复杂推理轨迹的搜索:
初始 CoT:LLM 首先生成一个初始的思维链(CoT)和答案。
搜索策略:
探索新路径:尝试新的推理方法。
回溯:回到之前的推理步骤,并从那里继续推理。
验证:评估当前的推理过程和结果。
纠正:批评并纠正当前的推理过程。
迭代过程:如果答案错误,模型会迭代地应用搜索策略,直到找到正确的答案或达到最大迭代次数。
数据合成:将成功的推理轨迹转化为连贯的自然语言推理过程,用于后续的微调。
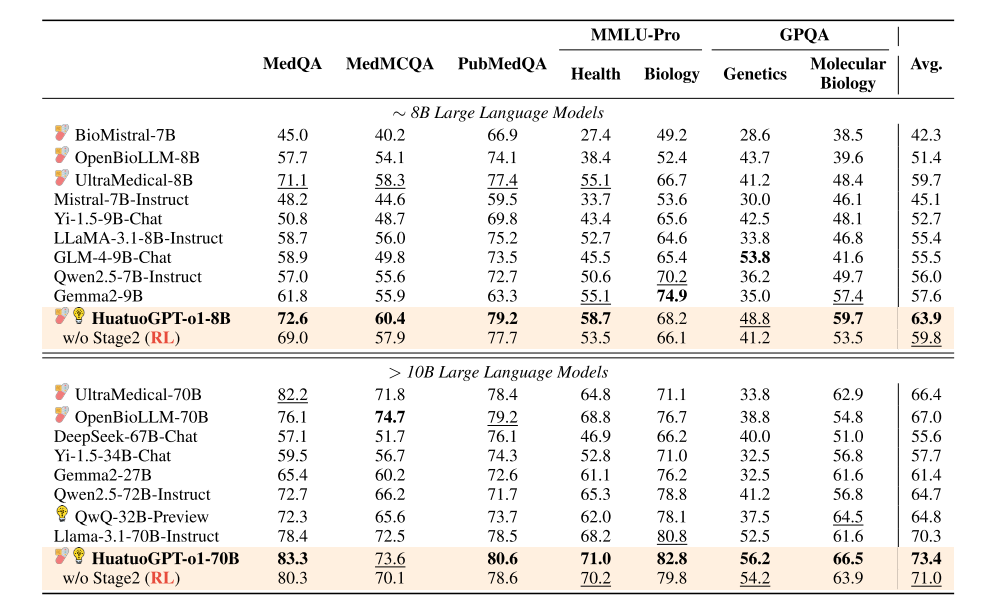
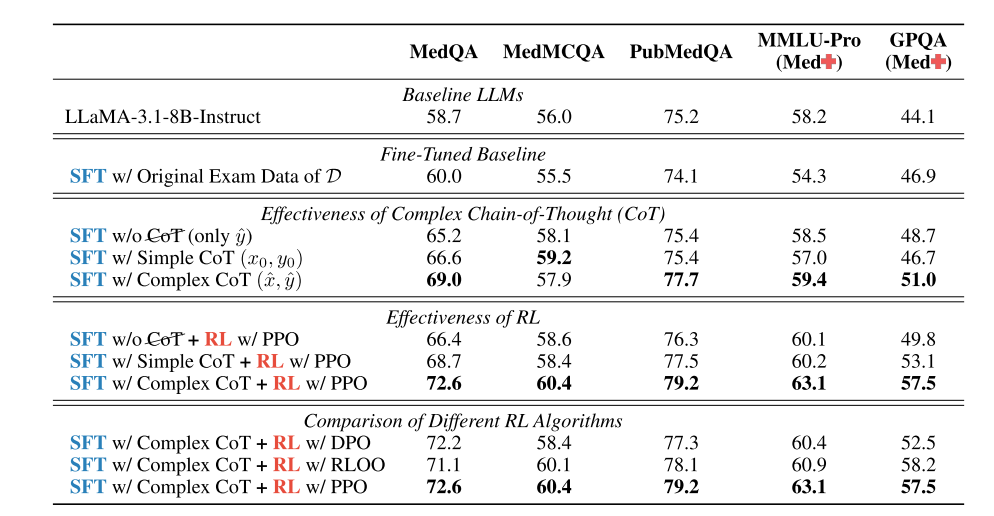
三、实验评估
四、论文总结
1.可验证医学问题与验证器的创新
可验证医学问题:研究者从医学考试问题中筛选并转换出40K个具有挑战性的开放式问题,每个问题都配有唯一的、客观的真实答案,使得模型的推理过程可以通过最终结果进行验证。
医学验证器:开发了一个基于GPT-4o的验证器,用于评估模型输出的正确性。验证器能够处理医学领域的同义词问题,并提供高准确率的二元反馈(True或False),准确率分别达到96.5%和94.5%。
2.两阶段训练方法
第一阶段:学习复杂推理
模型通过初始的思维链(CoT)和答案开始,并在验证器的指导下,通过回溯、探索新路径、验证和修正等策略逐步优化推理过程,直到找到正确答案。这一过程帮助模型学习如何进行复杂的推理。
第二阶段:强化学习增强推理
使用强化学习(特别是PPO算法)进一步优化模型,验证器提供的稀疏奖励用于指导模型的自我改进。这一阶段显著提升了模型的推理能力。