来源: arXiv 2025年3月
作者: Marshall Thomas,Edward Fish,Richard Bowden
单位: University of Surrey
一、论文主要工作及贡献
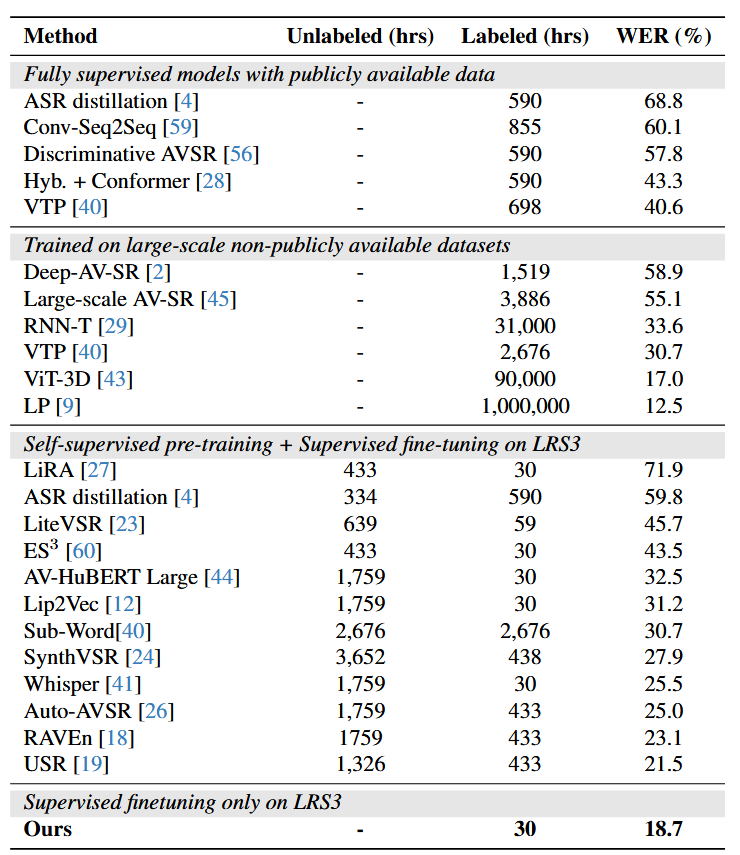
由于固有的歧义以及缺乏听觉信息,从视觉上区分重叠的音素(不同音素表现出相同的唇部运动)时,唇读任务具有挑战性。这篇文章提出以音素为中心的两阶段唇读框架,第一阶段使用ViT预测音素序列,第二阶段微调大语言模型从音素序列生成文本序列。在LRS3数据集上,使用更少99.4%的标签数据实现了18.7%的词错率的最佳性能。
二、模型框架
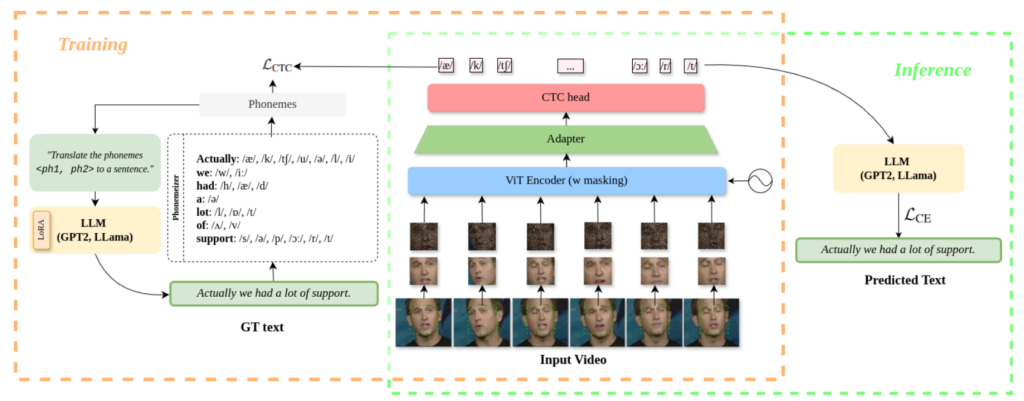
采用ViT编码面部区域的时空信息:
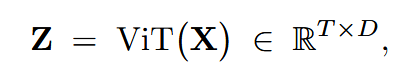
下采样减少时间维度,防止输出序列长度过大:
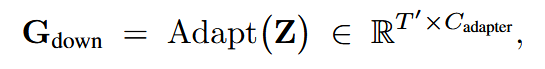
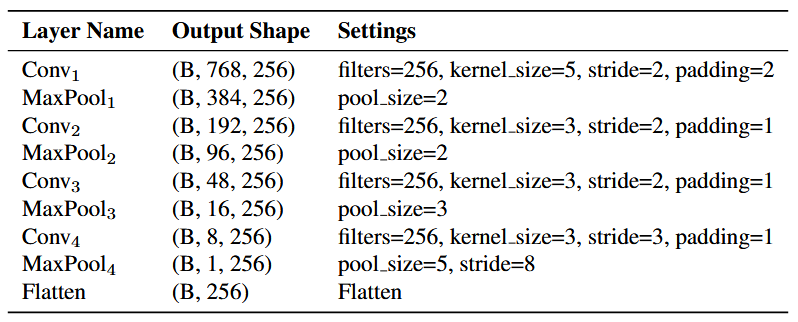
Adapter的结构:
CTC头将特征转换为音素logits:

CTC损失为:
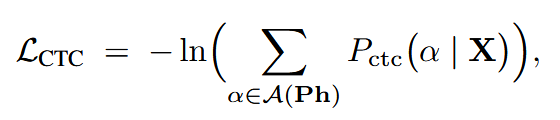
推理时,在CTC对数概率上执行beam search解码得到最终的音素序列。
预测得到的音素序列送入大语言模型,映射到文本序列:
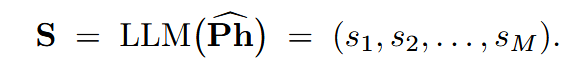
使用WikiText生成的音素-文本语料库上微调LLM:
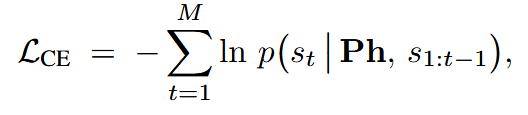
三、实验以及实验结果
视听数据集:LRS2和LRS3
文本数据集:WikiText
实验结果:
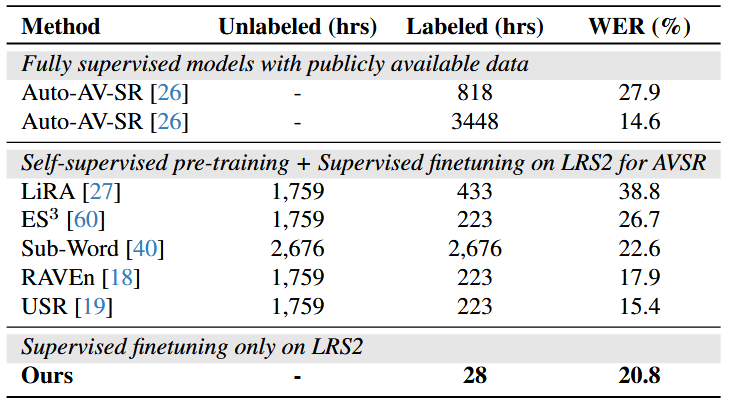
输出示例:

LLM对音素序列的校正:

混淆矩阵:
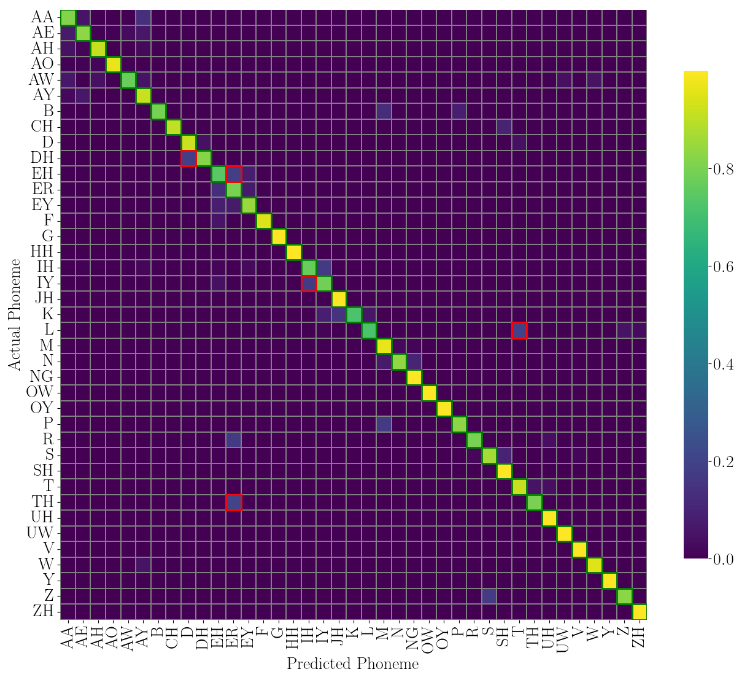
错误分类示例:
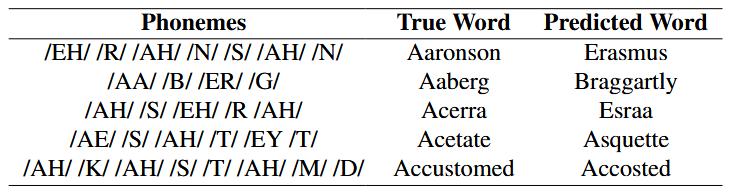
对不同LLM的消融实验:
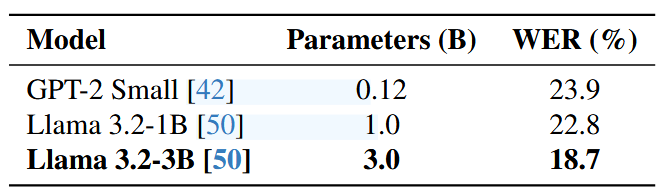
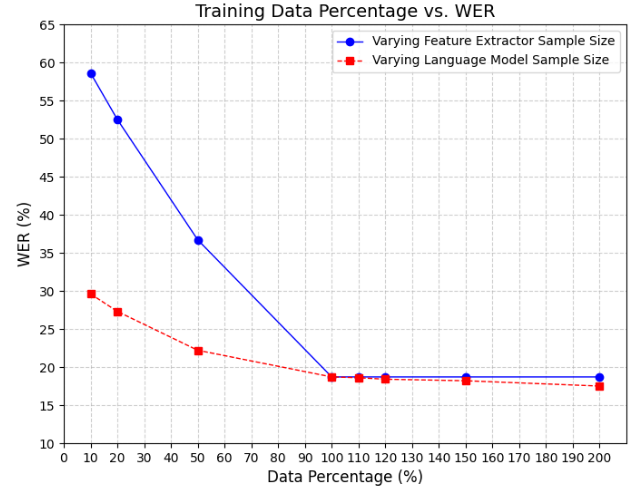
不同的训练数据量对性能的影响:
端到端的影响:

四、总结与思考
(一)、论文的核心内容:
- 引入两阶段以音素为中心的唇读方法;
- 在极少的标注数据中实现最佳性能。
(二)、综合对齐思考:
- 将唇读任务的重点从以视觉预测内容转变成语言建模任务。
- 对中文唇读任务,以及结合唇读的唇语到语音合成任务有参考价值。