来源:Engineering Applications of Artificial Intelligence, 2024
作者: Wenhao Wu, Weiwei Wang, Xixi Jia, Xiangchu Feng
单位:西电大学数学与统计学院
一、论文主要工作及贡献
为了优化特征学习和K-Means聚类,这篇论文提出了一个新的深层聚类网络,称为TAKE,用于K-Means的有效聚类。
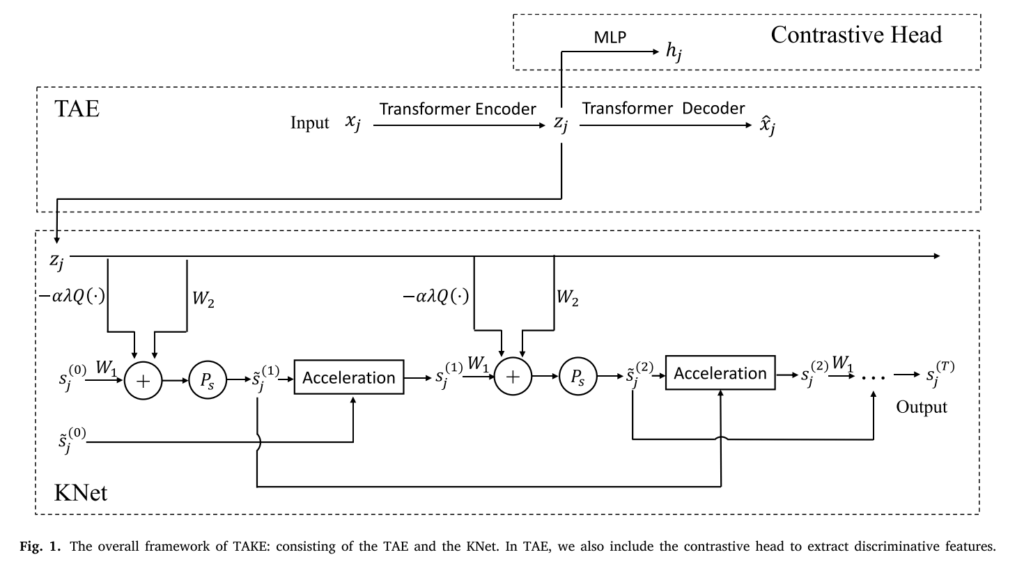
它由两个模块组成:用于特征学习的Transformer自动编码器(TAE)和用于聚类的KNet。 TAE结合了Transformer结构,以学习全局特征和对比度学习机制以增强特征歧视。KNet是通过对K-Means模型的加速投影梯度下降迭代来构建的。
该网络分为两个阶段:预处理和聚类。 在训练训练中,通过最大程度地减少基于余弦相似性的重建损失,对比度损失(CL)和凸组合损失(CCL)来优化TAE。 CCL鼓励增强邻居数据的功能。 在聚类阶段,通过最大程度地减少重建损失和K-Means聚类损失。
二、模型框架
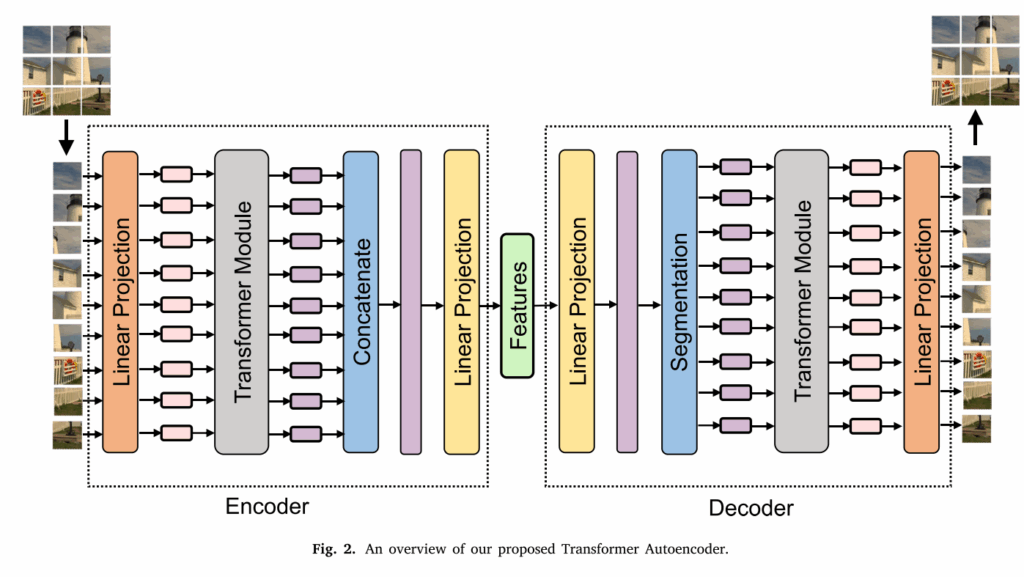
2.1. Pretraining loss of TAE

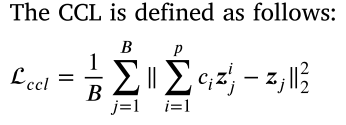
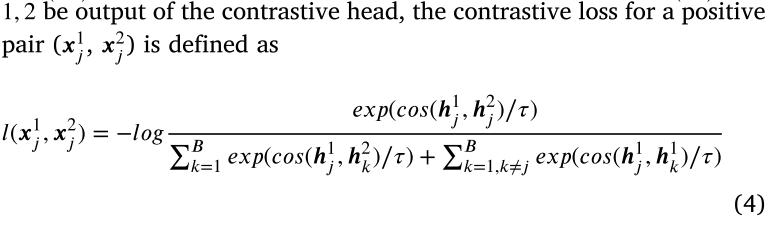
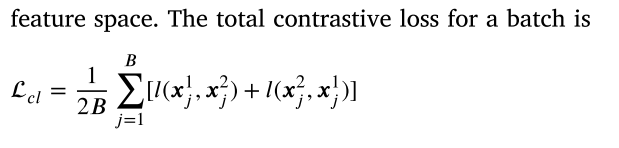

2.2. Training strategy
整个网络采用分为两个阶段:预处理和聚类。 训练阶段的主要目的是通过借助对比度损失训练TAE来良好的初始化,以学习判别特征。 聚类阶段端到端训练整个采集,以获得输入数据的群集分配。
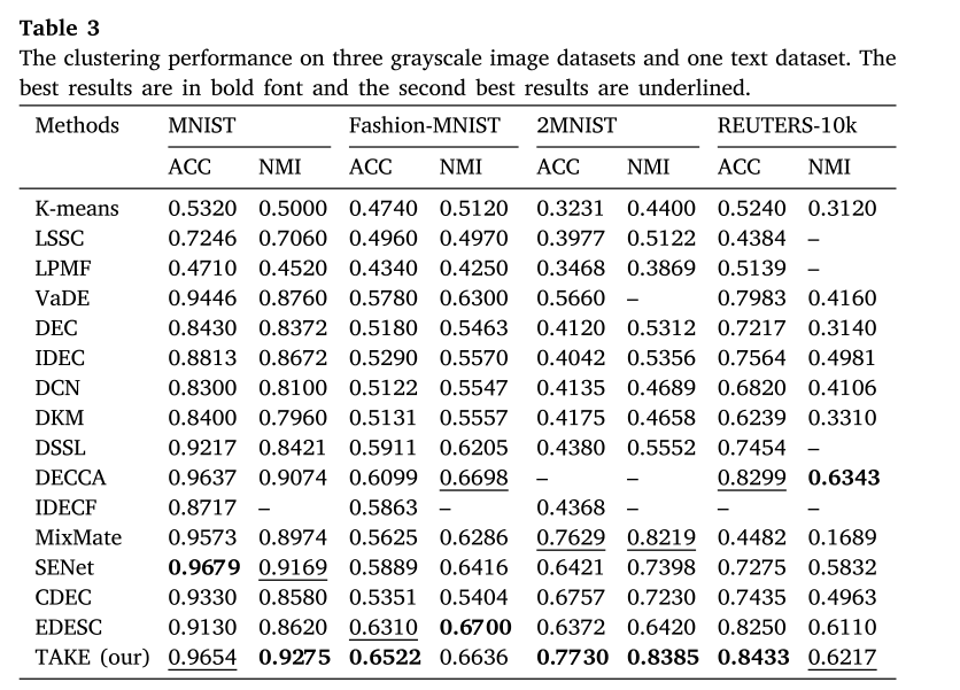
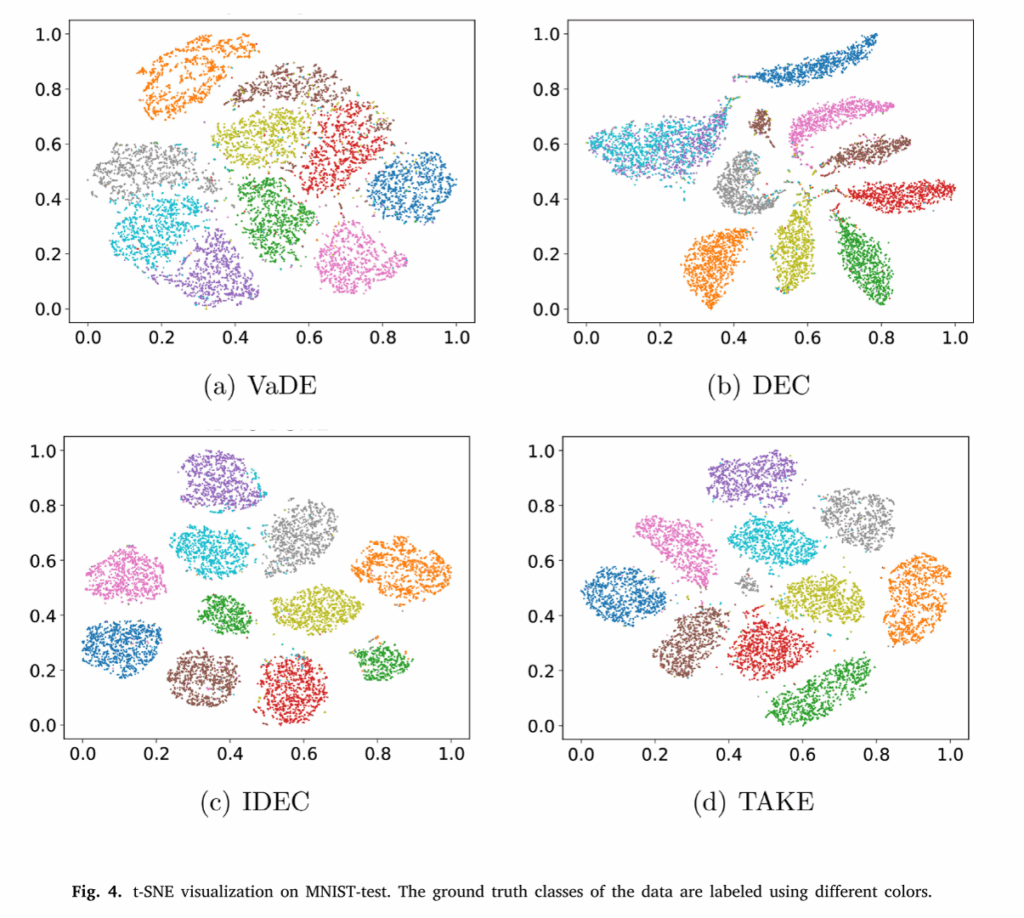
三、实验结果
四、总结与思考
(一)、论文的核心内容:
这篇文章提出了一个端到端的深群集网络。 它由两个模块组成:变压器自动编码器(TAE)和KNET。 为了提取适合K-均值聚类的区分特征,通过使用建议的重建损失,凸组合损失和对比度损失,可以预先训练TAE。
(二)、综合对齐思考:
1.这篇论文在聚类方面还是根植于K-Means,无法摆脱预定义簇数的局限性。
2.文章只是对transformer结构的简单应用,并且多针对于图像数据。