作者: Mengting Wan,Tara Safavi,Sujay Kumar Jauhar等
来源: ACM SIGKDD 2024
时间: 2024.08
一、背景
1.文本挖掘是从海量非结构化文本中提取有价值信息的重要技术,核心任务包括标签体系构建与文本分类。然而现有主流方法依赖人工构建标签体系与人工标注数据,不仅成本高、效率低,而且在面对大规模语料或开放领域场景时难以扩展。
2.另一类无监督聚类方法虽然可扩展性更好,但面临标签可解释性差、结果不稳定等问题,难以满足高质量结构化需求。如何兼顾可扩展性与可解释性,成为当前文本挖掘的关键挑战。
3.大语言模型(LLMs)在自然语言理解与生成方面展现出强大的能力,为自动化标签体系构建与文本分类提供了新可能。通过合理设计提示词(prompt),可在无监督或少监督的条件下引导模型完成复杂语义任务,极大降低人工干预成本。
二、核心创新
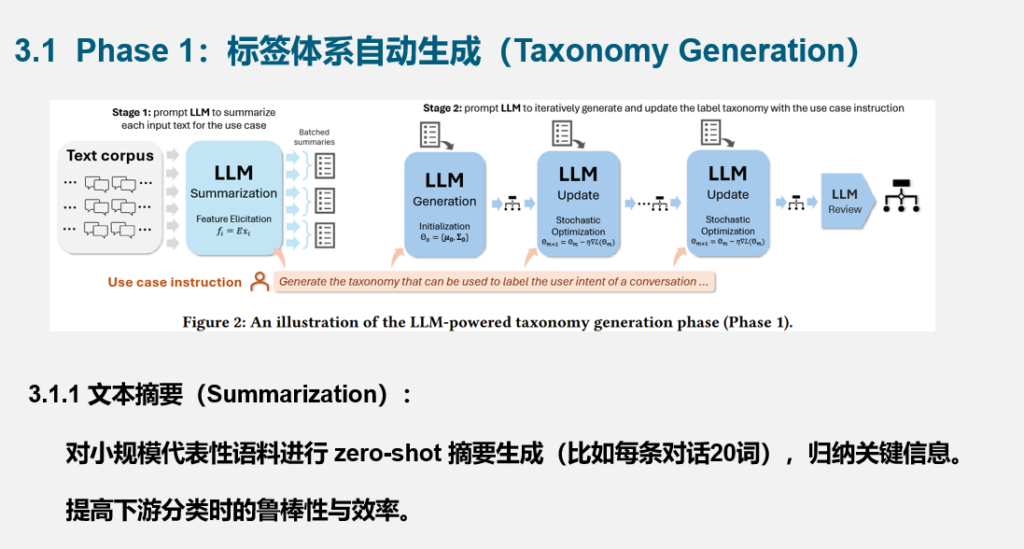
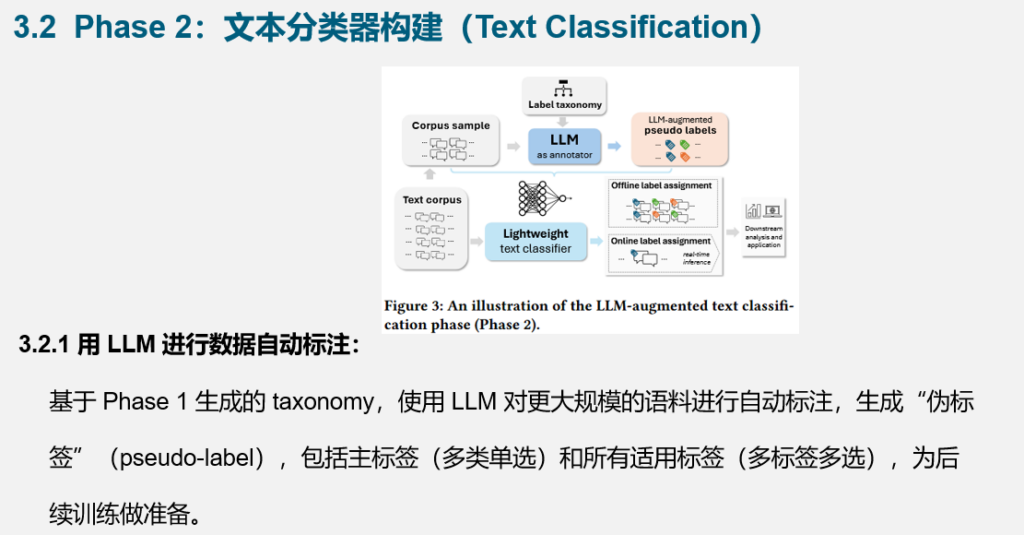
1. 本文提出了一个名为 TnT-LLM 的文本挖掘框架,全称为 Taxonomy and Text classification with LLMs,是一个端到端、低人力成本的两阶段系统架构。第一阶段利用LLM对少量语料进行摘要,并基于多轮推理生成标签体系;第二阶段再利用该标签体系对大规模语料进行伪标签标注,从而训练高效轻量的传统分类器,完成大规模部署。
2. 该框架的设计借鉴了混合模型和随机梯度下降的思想,将“标签体系”看作参数向量,通过小批量更新、误差反馈与优化实现迭代优化。与传统聚类相比,该方法具备更高的语义理解能力和更强的结构表达能力。
3. TnT-LLM 不仅能够生成高质量、可解释的标签体系,还可将LLM强大的理解能力“蒸馏”进可部署的模型中,兼顾了性能、成本和可维护性。整个流程高度模块化,可灵活适配不同语料、任务和模型。
三、方法


四、实验



五、总结与思考
1.提出 TnT-LLM 框架,实现可扩展、可解释的 taxonomy + text classification;
2. 将 LLM 视为“标签生成器”而非“分类器”,提升效率;
3. 设计综合评估方法,结合人类与 LLM 打分;
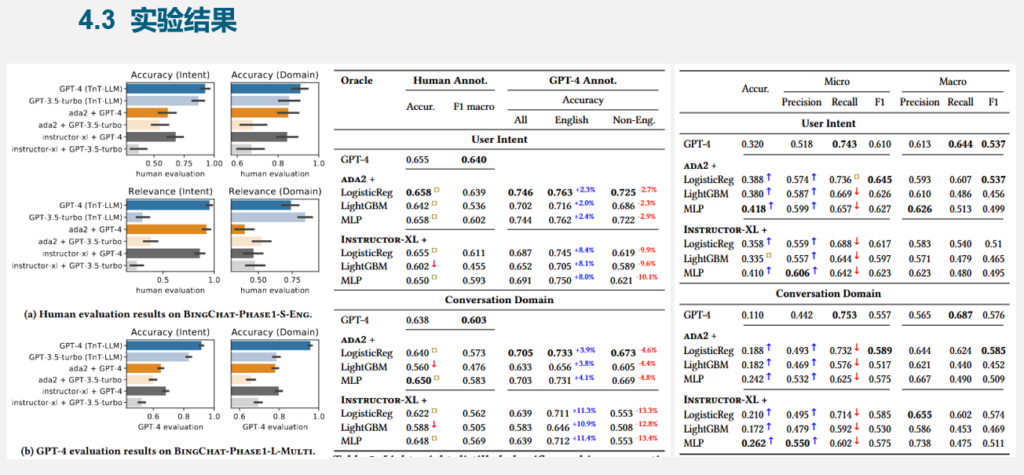
4.实验表明:TnT-LLM 在准确率、解释性和成本上均优于主流方法。