来源:南开大学、字节跳动
一、论文主要工作
这篇文章提出了一种新的自我注意力计算方法,称为 Consistent Self-Attention,它显着提高了生成图像之间的一致性,并以零镜头的方式增强了流行的基于预训练的基于扩散的文本到图像模型。为了将方法扩展到远程视频生成,进一步引入了一个新的语义空间时间运动预测模块,名为 Semantic Motion Predictor。它经过训练,可以估计语义空间中两个提供的图像之间的运动条件。该模块将生成的图像序列转换为具有平滑过渡和一致主题的视频,这些视频比仅基于潜在空间的模块要稳定得多,尤其是在长视频生成的上下文中。通过合并这两个新颖的组件,提出一个框架(称为 StoryDiffusion)可以描述一个基于文本的故事,其中包含包含丰富内容的一致图像或视频。
二、论文贡献
1.一致性自注意力(Consistent Self-Attention):提出了一种新的自注意力计算方法,能够在不需要训练的情况下增强生成图像之间的一致性,并以零样本的方式增强现有的预训练扩散模型。
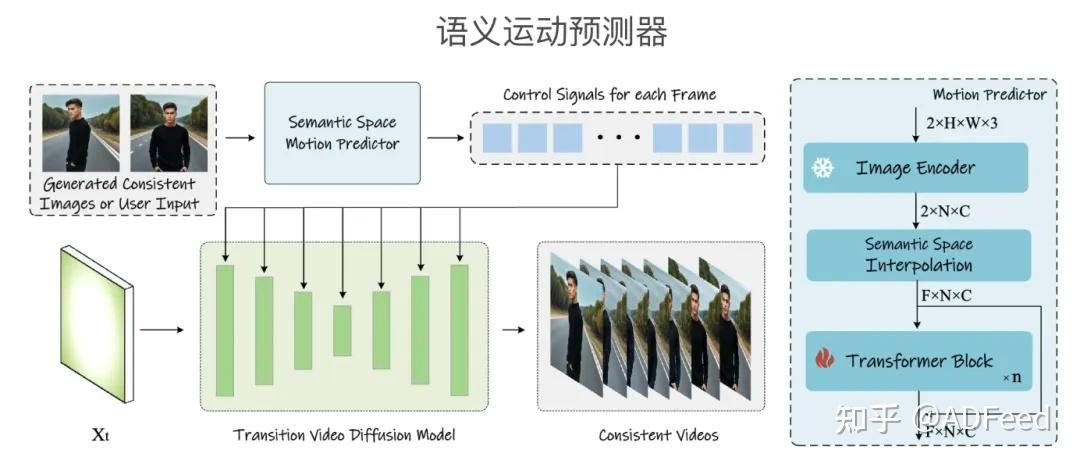
2.语义运动预测器(Semantic Motion Predictor):引入了一个新颖的模块,用于在语义空间中预测两个给定图像之间的运动条件,该模块能够将生成的图像序列转换成具有平滑过渡和一致主体的视频。
3.StoryDiffusion 框架:结合上述两个新组件,提出了一个框架,能够根据文本故事生成包含丰富内容的一致性图像或视频。
三、方法

StoryDiffusion 的实现方法主要为两个核心组件:
一致性自关注(Consistent Self-Attention):这是一种新的自注意力计算方式,能够在不同图像间建立联系,以增强生成图像中角色的一致性。这种方法不需要额外的训练或微调,可以作为即插即用的模块集成到现有的图像生成模型中。
语义运动预测器(Semantic Motion Predictor):这个模块用于长跨度的视频生成,它通过在语义空间中预测两个条件图像之间的运动条件,将一系列生成的图像转换成具有平滑过渡的视频。这种方法能够在保持角色和场景一致性的同时,生成具有物理意义和长距离运动的视频内容。
四、实验
实验评估了StoryDiffusion在生成主体一致图像和过渡视频方面的性能,并与当前最先进的方法进行了比较。
用户研究显示,无论是在主体一致性图像生成还是过渡视频生成方面,StoryDiffusion都显示出压倒性的优势。

五、总结
1.这篇文章提出了 SynCamMaster ,这是一种新颖的方法,可以以免训练的方式生成一致的图像来讲故事,并将这些一致的图像转换为视频。
2.Consistent Self-Attention 在多个图像之间建立联系,以有效地生成具有一致面孔和服装的图像。
3.使用语义运动预测器将这些图像转换为视频并更好地叙述故事.
4.局限性:在生成主体一致图像时,可能存在一些细节上的不一致,如领带等;尽管可以使用滑动窗口方法生成更长的视频,但该方法并非专门设计用于长视频生成,因此在生成非常长的视频时可能不完美。