作者:Runyu Ding; Jihan Yang; Chuhui Xue;
单位:香港大学
来源: IEEE Transactions on Pattern Analysis and Machine Intelligence
时间:2024.06.06
一、研究背景
三维场景认知涉及定位三维物体并理解其语义,是虚拟现实(VR)、机器人操纵和人机交互等现实世界应用的重要感知组件。深度学习在这一领域取得了显著成就,然而,在人类标注数据集上训练的深度模型只能理解数据集中存在的语义类别,而无法识别训练数据中未出现的新类别,这严重限制了它们在现实世界场景中的适用性,且三维数据集的注释成本很高。
这促使作者团队研究开放世界三维实例级场景理解,它允许模型识别和定位未包含在注释数据集标签空间中的开放集类别。
二、核心内容
- 超经验的语义识别和实例定位两个方面深入分析了开放世界三维场景理解所面临的挑战,有助于更好地理解和解决这一任务。
- 提出了一种轻量级提案分组模块,通过结合伪偏移监督信号,有效减少了对基础类的偏差,这大大提高了实例定位对新类别的适应性。
- 在三个大规模场景理解数据集上进行了广泛的实验,这些数据集涵盖了室内和室外场景,在实例级理解方面大大超过了 PLA ;在三维全景分割任务上进一步尝试 Lowis3D,在 nuScenes 数据集上取得了显著改进。
总之,这些改进为开放世界三维场景理解提供了一个更全面、更有效的框架,在各种现实世界场景中具有很高的潜力和适用性。
三、核心框架贡献
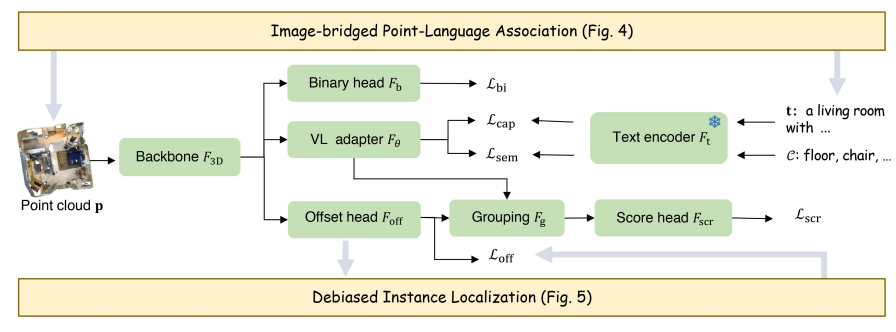
上面是Lowis3d的培训框架插图。Lowis3D 以图像桥接点语言关联模块为起点,该模块可跨层级生成配对点云 p 和标题 t,从而使模型能够通过对比训练 Lcap 学习丰富的语义。 此外,为了校准模型对基础语义的偏向,作者加入了一个二元头 Fb,通过 Lbi 预测属于已见或未见类别的点,详见第 V-B 节。此外,对于新实例定位,去偏实例定位模块通过 Loff 对新类别生成可信的伪偏移监督,以增强开放世界对象性学习
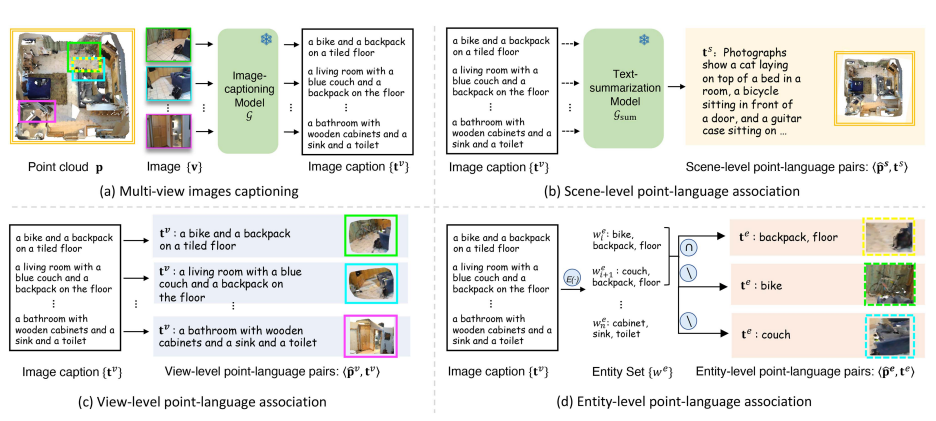
上图显示的是图像桥接点语言关联。作者团队提出了场景级、视图级和实体级的分层点语言关联方法,通过视觉语言基础模型和多视图 RGB 图像,在标题监督下分配从粗到细的点集。
四、实验部分
- 数据集: 为了全面验证Lowis3D的有效性,作者在两个室内数据集上进行了语义和实例分割任务的实验,这两个数据集分别是ScanNet (注释为20个类别)和S3DIS (注释为13个类别)。此外还在室外数据集 nuScenes 上对 Lowis3D 进行了评估,该数据集包含 16 个全景分割类别。
- 网络架构: 作者采用流行的高性能稀疏卷积 UNet 作为三维编码器 F3D,采用 CLIP 的文本编码器作为 Ft,采用批量归一化的全连接层 和 ReLU 作为 VL 适配器 Fθ,采用 UNet 解码器作为二进制头 Fb。此外还采用了最先进的实例分割网络 SoftGroup ,用于提案分组 Foff 和评分 Fscr。
- 基准方法: 对于实例和全景分割,作者采用 OV-Softgroup 作为基准方法。鉴于实例级开放世界三维场景理解仍处于起步阶段,目前还没有其他合适的方法可供直接比较。
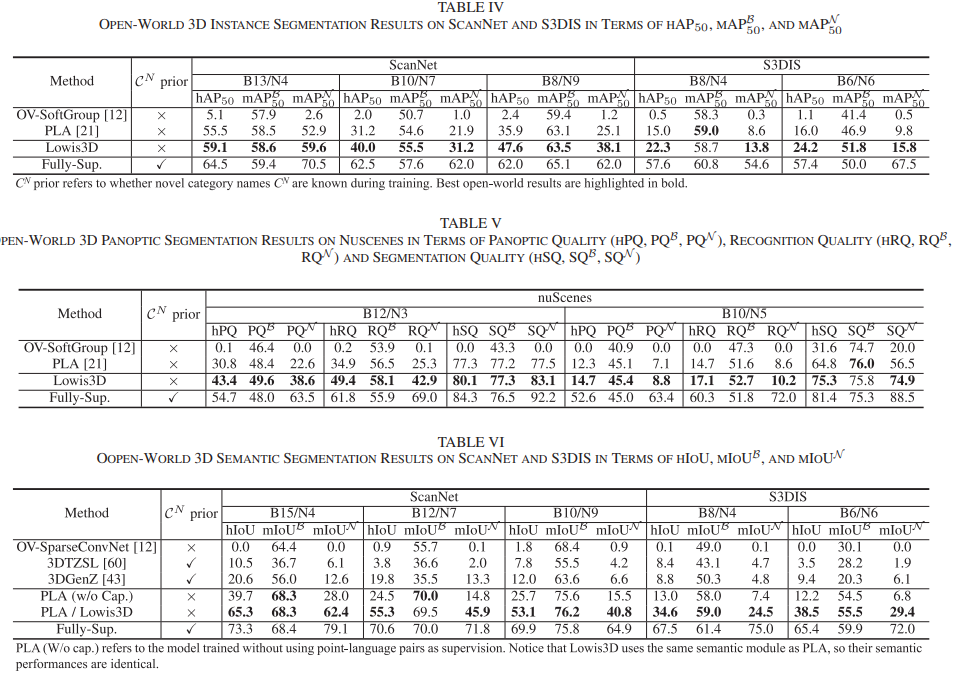
下面是对应不同数据集上各个模型的表现,数据记录如下
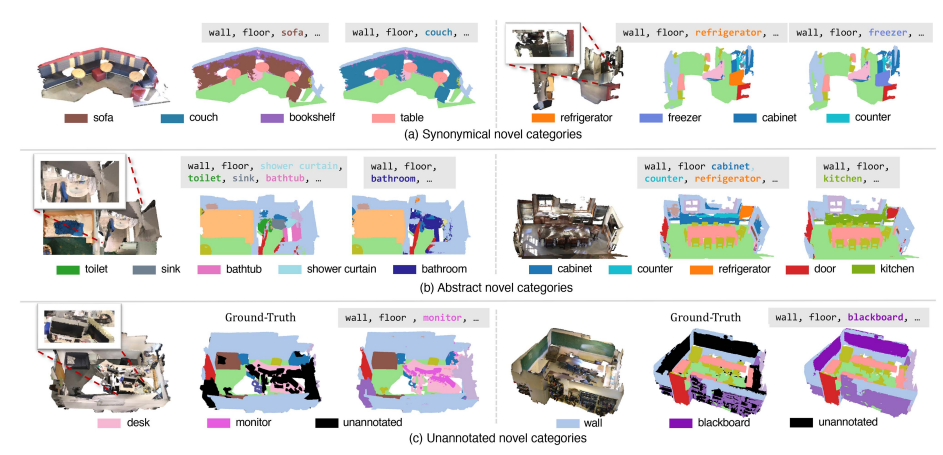
下图是识别词汇外类别的定性示例。(a) 显示同义词类别的识别结果。(b) 展示抽象概念的分类结果。(c) 展示未注释类别的分类结果。
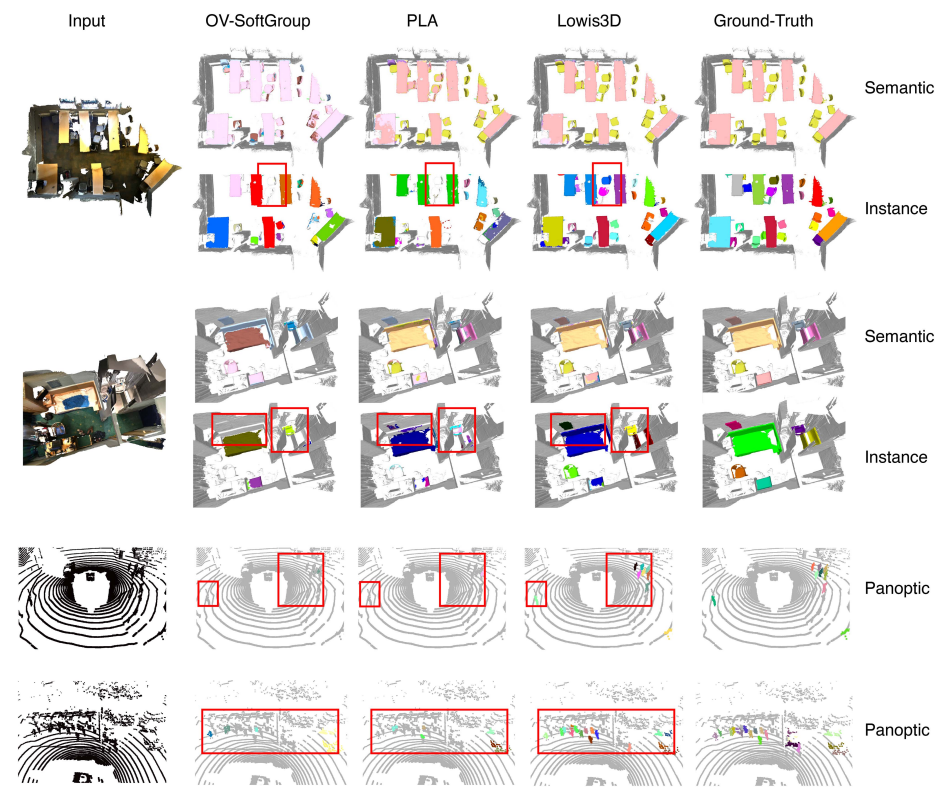
下图是开放世界实例和泛视分割的定性结果。新类别用彩色标注,基础类别用灰色标注,以便清晰区分。值得注意的比较在红色边界框内突出显示。
五、总结
作者提出的 Lowis3D 是一个全面而高效的框架,用于解决开放世界实例级三维场景理解问题。方法是利用图像作为桥梁,建立分层的点-字幕对,利用二维视觉语言(VL)基础模型的力量以及三维场景和二维图像之间的几何关系。对比学习被用来增强这些关联对中的特征对齐,从而为三维网络注入了丰富的语义概念。此外还提出了偏离实例定位的方法,以减轻对象分组对基本模式的偏差,从而提高对象性学习的泛化能力。大量实验证明了作者的方法在开放世界实例级场景理解任务中的有效性。