作者:Zhendong Wang, Wengang Zhou
单位:中国科学技术大学
来源:arXiv
时间:2025.03
一、研究背景
视觉文本生成的现有工作通常在给定区域内生成文本,这种方法不但限制生成图像的创意广度,并且可能导致渲染的文本与图像中呈现的视觉元素缺乏一致性。为了解决这个问题,本文提出了DesignDiffusion框架,直接综合用户提示中的文本和视觉设计元素,生成准确且风格一致的文本和视觉内容。
二、研究思路及框架
(1)本文贡献
①提出DesignDiffusion框架,用于文本到设计图像的生成,同时生成图像和视觉文本元素,无需预定义的文本区域或传统的两阶段分离的文本和图像创建过程。
②探索了CLIP文本编码器的提示增强(单词的字符级分解)和字符定位损失,提高了文本放置的准确性和文本渲染的保真度。
③引入自播放直接偏好优化(SP-DPO)的新训练策略,用于微调模型以增强其生成准确和高保真文本的能力。
(2)框架
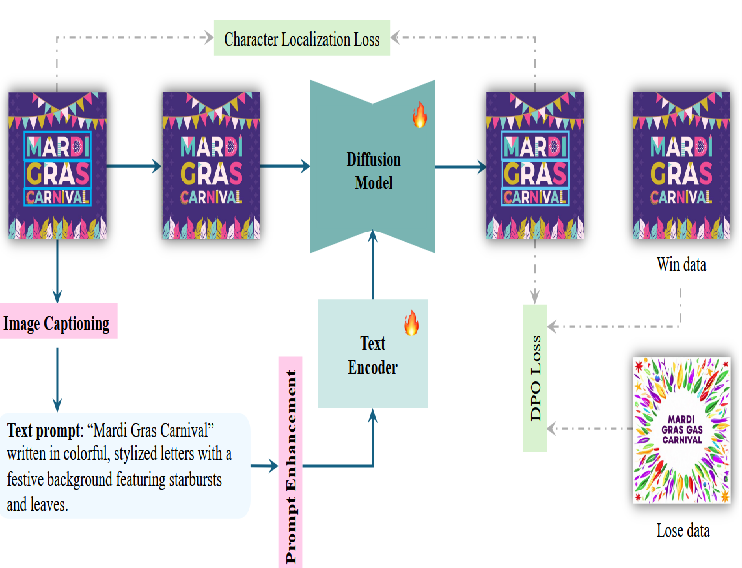
①CLIP文本编码器的提示增强功能
CLIP文本编码器的输入提示通过向原始提示附加额外的文本描述来增强。共引入了 97 个新标记,包括 26 个大写字母、26 个小写字母、10 个数字、32 个标点符号、一个空格、一个开始标志和一个结束标志。
②使用字符分割掩码定位交叉注意力图
为使UNet关注新引入的字符嵌入,提出字符定位损失,每个字符 Token 关注相应的字符区域。
③自播放 DPO 微调可实现更准确的文本渲染
为增强模型处理设计图像的能力,应用了自播放 DPO 微调,将训练的真实图像作为获胜数据,将生成图像中渲染质量最差的作为丢失数据。
三、研究结论及分析
(1)与最先进方法的比较
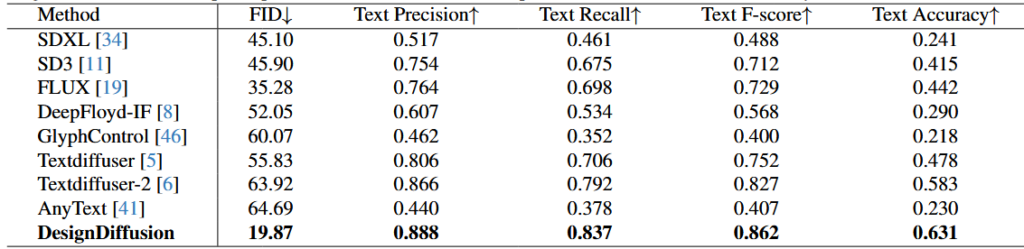
①定量结果
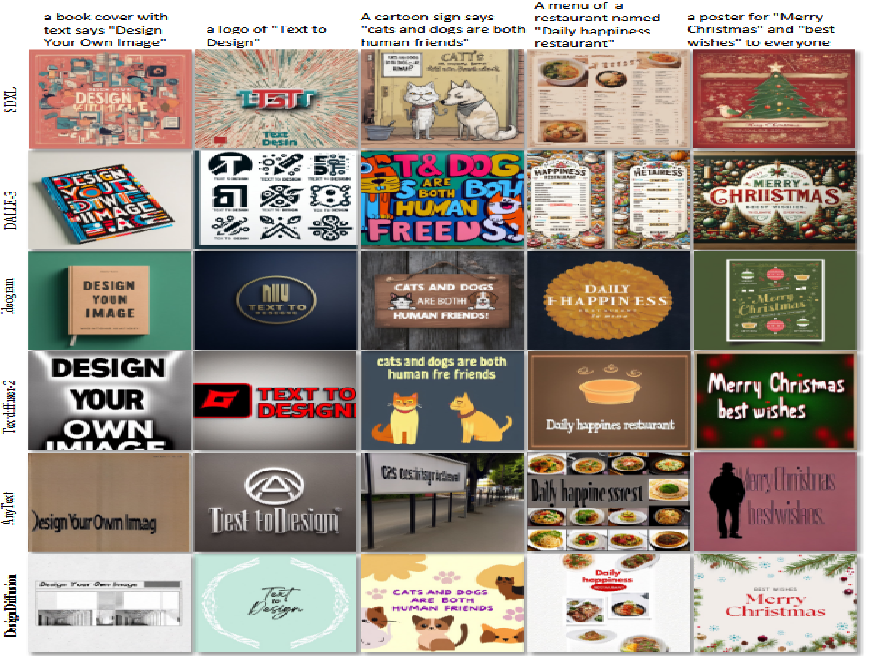
②定性结果
视觉比较表明,DesignDiffusion 能生成更优雅、和谐的集成视觉和文本设计图像。
(2)消融研究

四、总结与思考
(1)总结
本文提出了DesignDiffusion微调框架,旨在从文本描述中合成设计图像。探索了包括独特的字符嵌入和字符定位损失,以增强视觉文本学习。此外,采用 SP-DPO 微调策略提高生成质量。
(2)思考
对于从文本生成设计图像的任务,常见方法为:首先从文本输入生成图像,然后在图像中确定合适的位置以插入文本。而DesignDiffusion框架直接综合了用户提示中的文本和视觉设计元素,且可以生成更优雅、更和谐的集成视觉和文本设计图像。