作者:Xinru Wang, Hannah Kim, Sajjadur Rahman等
来源:ACM
单位:Purdue University、Megagon 实验室
发表日期:2024.5
一、背景动机
论文背景
1.大语言模型(LLMs)具备强大的语义理解和生成能力,已经被广泛应用于数据标注,极大地降低了标注成本。
2.然而,LLMs 在处理复杂或特定领域任务时仍然容易出错,且其输出可能带有偏见,无法完全替代人工标注。
3.为了保证标注质量与可信度,有必要设计能够有效结合人类和 LLM 优势的协同标注框架。
研究目标
本研究旨在提出一种人机协同的标注框架,结合大语言模型的生成能力与人类的判断力,提升数据标注的效率与准确性。通过引入验证机制和合理利用模型生成的解释信息,确保标注结果的可靠性,减少人工成本,并促进人机协作的有效配合。
二、核心方法
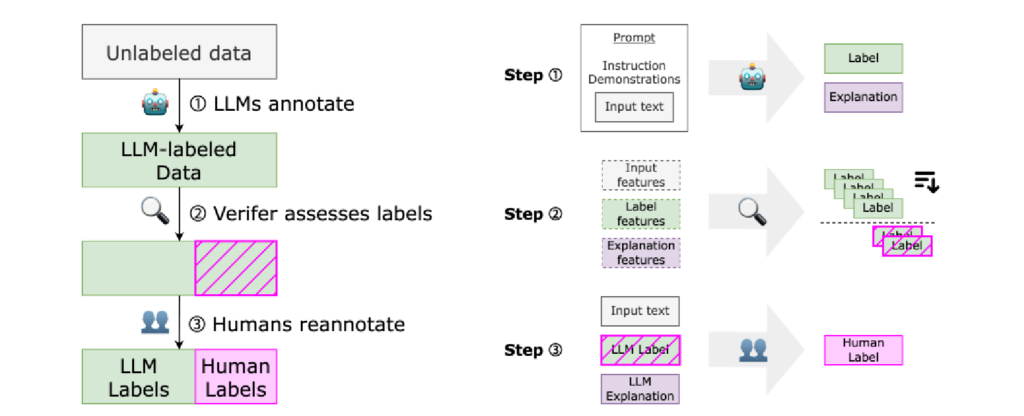


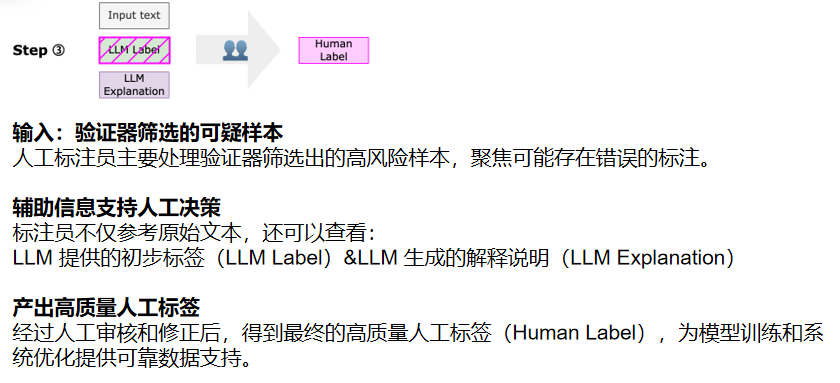
三、实验评估
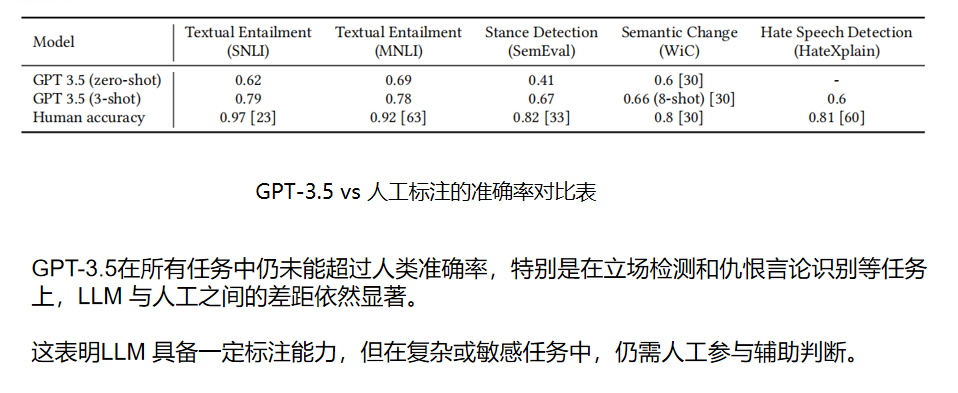
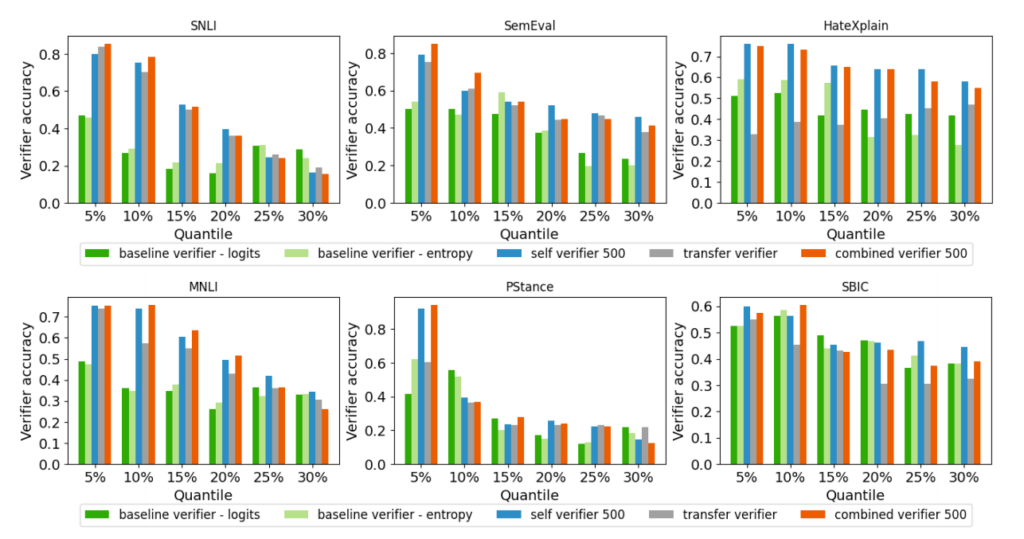
相比 baseline,准确率大幅提升,尤其是在 SNLI、PStance 等任务中提升显著。
说明验证器能准确识别最可能错误的标签,为人工标注节省大量成本。
四、总结思考
论文总结
核心方法:
提出人机协同标注框架 Lapras,依次由 LLM 生成标签与解释、验证器筛选错误标签、人工复审修正,结合模型效率与人工判断力,提升标注质量与可控性。
实验结果:
实验结果表明,Lapras 在多个任务中表现优于纯 LLM 或纯人工标注。验证器能有效识别错误标签,且提供 LLM 标签与解释可显著提升人工标注的准确性与一致性。
优势总结:
Lapras 降低人工成本的同时提升标注性能与可解释性。验证器精准筛选错误,LLM 解释增强人工信任,实现高效、人机互补的协同标注流程。
启发思考
1.LLM 的解释能力不仅用于人类理解,也能作为数据质量评估的信号输入验证器,这为我在 RAG 场景下设计“可解释的预标注数据流”提供了新思路。
2.验证器利用少量人工标签实现高效筛错,说明在预标注中也可以引入轻量级质量控制模块,避免低质量数据进入知识库,降低后期推理难度。
3.本文提出的“人机协同标注”框架体现了LLM 与人工的优势互补,为我构建“自动预标注 + 人工审查 + 可追踪解释”的高质量知识构建流程提供了参考。