作者:Ahmad Salimi, Tristan Aumentado-Armstrong, Marcus A. Brubaker
来源:CVPR
单位:York University
时间:2024
一、研究背景
在3D场景的多视角修复中,主要的挑战在于生成合理完整的图像,这些图像完成在各个视图上几乎是一致的。最新的工作通过将生成模型与3D辐射场相结合,以融合相对密集的视点信息来应对这一挑战。但是,这些方法的主要缺点是,由于不一致的跨视图图像融合,它们通常会产生模糊的图像。为了避免模糊的图像,本文避免完全使用显式或隐式辐射场,而是在学习空间中融合了跨视图的信息。此外,我们引入了一个几何形式的条件生成模型,该模型能够使用基于参考的几何和外观提示进行多视图一致性修复。
二、研究思路及方法
现有的使用NERF进行多视角编辑的一些缺陷
①多视角的图像修复很难在场景上以及空间达到一致性。
①倾向于模糊的趋势,部分是由于像素空间中发生的融合
②依赖辐射场,这需要具有足够视图覆盖范围的准确的摄像机参数。
提出的方法
①本文通过扩散生成过程中融合跨视角信息,并在一个学习到的空间中进行处理。
②避免对3D辐射场的依赖。
③设计了一种几何感知的条件扩散模型,能够基于参考图像中的几何和外观线索,生成多视图一致的修复图像。
本文贡献
①基于NeRF的修复方法在外观空间中融合不一致性,从而导致模糊,而本文的方法通过生成模型融合跨视图信息,即使将NeRF拟合到本文最终的修复结果上,也能产生更清晰的输出。
②本文针对三项主要的修复任务:窄基线目标移除、宽基线场景补全以及少视图修复。大多数以往的工作集中在第一项任务上,第二项任务是近期的新增研究方向,而第三项任务在最近的进展中尚未得到充分探索。

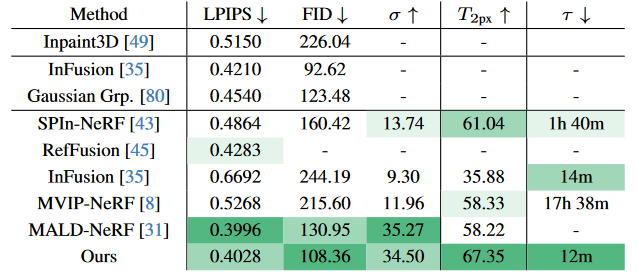
上图展示了我们每个目标任务的可视化效果。我们在两个数据集上评估了我们的多视图修复器:SPInNeRF和 NeRFiller,这两个数据集分别包含窄基线和宽基线数据,并在这两个数据集上均实现了最先进的3D修复性能。
本文对目标修复任务的可视化。我们关注三项任务:(i) 窄基线物体移除,(ii) 宽基线场景补全,以及 (iii) 少视图修复。在此,我们展示了每项任务的输出示例,并在每张图像的左上角显示了对应的掩码输入。
模型架构
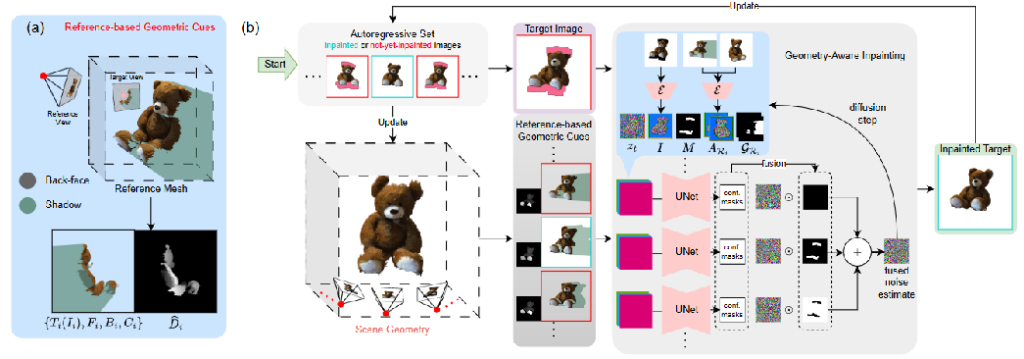
本文的方法包括两个模型:一个场景几何估计器和一个几何感知修复模型。对于前者,本文使用高性能的DUSt3R,它能够高效地提供密集深度信息,无论是否存在相机位姿,都可以直接利用视图。对于后者,本文对基于潜在2D扩散的修复器进行了微调,使其能够根据其他视图进行条件化处理。
基于这两个模型,本文设计了一种简单的自回归场景修复算法。在每次迭代中,本文根据其他视图(无论是否已修复)的条件,对一组尚未修复的视图进行修复,然后更新估计的几何信息。
三、结果

四、总结与思考
总结
在本文中,提出了一种新颖的3D场景修复方法,无需依赖3D辐射场。虽然这种方法避免了在像素空间中进行融合(这会导致模糊),但它需要一种基于估计场景几何信息的新方式来跨视图融合信息。为此,本文通过训练一个基于扩散模型的修复器来实现这一目标,该修复器以参考视图集中的外观和几何线索为条件,从而能够在生成模型的学习空间中进行融合,从而保留清晰度。由此得到的多视图修复算法具有高度的通用性,能够处理其他方法难以应对的稀疏视图修复任务,并且无需相机位姿信息即可运行。本文在两个近期的基准数据集上测试了该方法的有效性,这些数据集涵盖了窄基线和宽基线3D场景以及少视图场景,结果表明,无论是在图像质量还是多视图一致性方面,该方法在所有情况下均达到了当前最优性能。
思考
3D辐射场进行多视角图像编辑的效果存在一些不理想的问题,通过本文的几何感知以及摆脱对3D辐射场的依赖,更好地实现在空间中进行多视角相关的图像编辑。