作者:Jihan Yang,Shusheng Yang,Li Fei-Fei
单位:纽约大学、耶鲁大学、斯坦福大学
来源:arxiv
时间:2024.12.18
一、研究背景
人类拥有视觉空间智能,可以通过连续的视觉观察记忆空间。然而,在百万规模的视频数据集上训练的多模态大语言模型(MLLMs)也能从视频中进行 “空间思维 ”吗?视觉空间智能需要感知空间关系并对空间关系进行思维操作;它需要多种能力,包括关系推理以及在自我中心视角和分配中心视角之间进行转换的能力。大型语言模型(LLMs)推动了语言智能的发展,而视觉空间智能尽管与机器人、自动驾驶和AR/VR相关,但仍未得到充分探索。 多模态大语言模型(MLLMs)整合了语言和视觉,在开放式对话和网络代理等实际任务中表现出强大的思考和推理能力。

二、核心内容
- 作者提出了一个新颖的基于视频的视觉空间智能基准(VSI-Bench),其中包含 5,000 多对问答
- 作者对模型进行了探究,以表达它们是如何在语言和视觉上进行空间思维的,结果发现,虽然空间推理能力仍然是MLLMs达到更高基准性能的主要瓶颈,但在这些模型中确实出现了局部世界模型和空间意识
- 目前流行的语言推理技术(如思维链、自洽性、思维树)无法提高成绩,而在回答问题时明确生成认知地图却能增强 MLLM 的空间距离能力
三、核心框架贡献
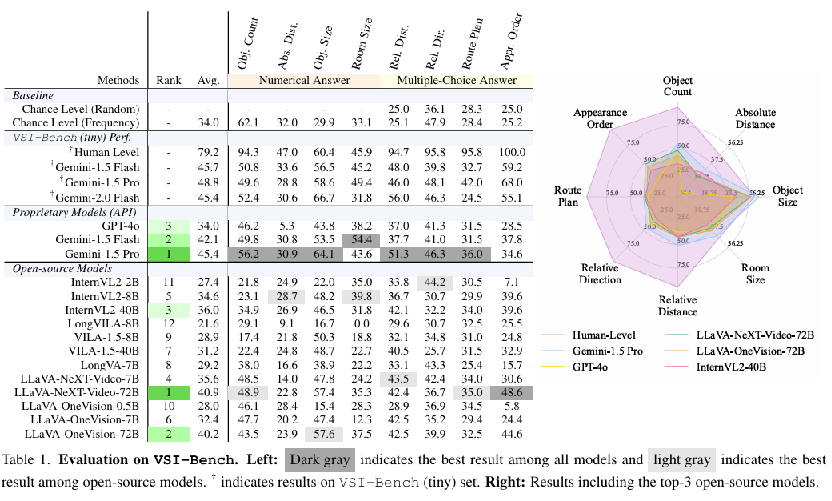
作者引入 VSI-Bench 来定量评估来自自我中心视频的 MLLM 的视觉空间智能。VSI-Bench 包含来自 288 个真实视频的 5000 多个问题对。这些视频来自公共室内三维场景重建数据集 ScanNet 、ScanNet++ 和 ARKitScenes的验证集,代表了不同的环境–包括住宅空间、专业环境(如办公室、实验室)和工业空间(如工厂)–以及多个地理区域。

重新利用这些现有的三维重建和理解数据集可提供准确的对象级注释,作者将其用于问题生成,并可在未来研究 MLLM 与三维重建之间的联系。 VSI-Bench 的质量很高,经过反复审查,最大限度地减少了问题的模糊性,并删除了源数据集传播的错误注释。

四、实验部分
下表显示了模型在 VSI-Bench 上的总体性能。 主要观察结果如下:
- 人类水平性能。毫不奇怪,人类评估者在我们的基准上达到了 79% 的平均准确率,比最佳模型高出 33%。值得注意的是,人类在配置和时空任务上的表现非常出色,从 94% 到 100% 不等,这表明了人类的直觉能力。相比之下,在需要精确估计绝对距离或大小的三个测量任务上,人类与最佳 MLLM 的性能差距要小得多,这表明 MLLM 在需要定量估计的任务中可能具有相对优势。
- 专有 MLLM。尽管与人类的性能差距很大,但领先的专有模型 Gemini1.5 Pro 还是取得了具有竞争力的结果。它在绝对距离和房间大小估算等任务中的表现远远超过了机会水平基线,并设法接近人类水平。值得注意的是,人类评估员在理解物理世界的空间方面拥有多年的经验,而 MLLM 只能在二维数字数据(如网络视频)上进行训练。
- 开源 MLLM。LLaVA-NeXT-Video-72B 和 LLaVA-OneVision-72B 等顶级开源模型的性能与闭源模型相比极具竞争力,仅落后于领先的 Gemini-1.5 Pro 4% 到 5%。然而,大多数开源模型(7/12)的性能都低于机会水平基线

五、总结
作者通过构建 VSI-Bench 并研究 MLLM 在该平台上的表现和行为,来研究模型是如何看到、记住和回忆空间的。同时对 MLLM 如何通过语言和视觉进行空间思维进行了分析,发现了视觉空间智能的现有优势(如突出的感知、时间和语言能力)和瓶颈(如自我中心-全中心转换和关系推理)。虽然目前流行的语言提示方法无法提高空间推理能力,但建立明确的认知地图确实能提高 MLLMs 的空间距离推理能力。未来的改进途径包括针对特定任务的微调、开发空间推理的自我监督学习目标或针对 MLLM 的视觉空间定制提示技术等等