作者: Yuan Sui, Shi Han, Mengyu Zhou, Mingjie Zhou, Dongmei Zhang
来源: International Conference on Web Search and Data Mining(ACM)
时间: 2024.04
一、背景
1.结构化数据的重要性:表格广泛应用于问答、事实验证等任务,但其复杂结构(如合并单元格、行列关系)对模型理解能力提出挑战。
2.现有工作缺乏系统性评估大语言模型(LLMs)对表格结构理解的深度,且输入设计(如序列化方法)缺乏统一标准。
二、核心创新
1.SUC基准测试:首个系统性评估LLMs表格结构理解能力的基准,涵盖7项任务(表分区、表大小检测、合并单元格检测、单元格查找、行列检索等),覆盖结构解析与信息检索能力。
2.自我增强提示方法:通过两阶段提示(首先生成中间结构知识,再结合下游任务)提升了模型性能,无需额外训练,适配多种表格格式(HTML、JSON等)
三、方法
3.1 SUC基准设计
衡量表格结构理解能力的两个方面:
1.结构解析能力(Partition & Parsing)
2.信息检索能力(Search & Retrieval)

1.衡量结构解析能力的任务设计:
1).表分区(Table Partition):要求模型识别输入文本中表格的边界(起始和结束标记),区分表格与其他补充信息(如描述、上下文)。输入设计包含混合文本,模型需输出表格的起始和结束标记(如HTML中的<table>和</table>)。
2).表大小检测(Size Detection):统计表格的行数和列数(例如输入“表格有多少行和列?”),验证模型对基本结构特征的提取能力。
3).合并单元格检测(Merged Cell Detection):定位表格中合并单元格的位置(如“检测跨越多行的单元格”),测试模型对复杂结构的理解。
2.衡量信息检索能力的任务设计:
1).单元格查找(Cell Lookup):根据内容定位单元格的行列索引(如“查找‘Antoine’的位置”)。
2).反向查找(Reverse Lookup):根据行列索引返回单元格内容(如“第3行第2列的值是什么?”)。
3).行列检索(Column/Row Retrieval):按列名或行号提取整列或整行数据(如“列出‘Year’列的所有值”)
3.2 自我增强提示(Self-Augmented Prompting)
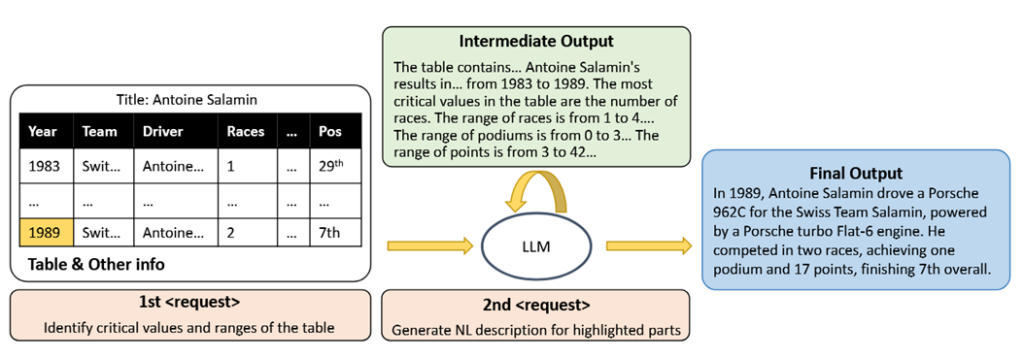
第一阶段:中间知识生成
关键值范围识别:要求模型生成表格中的关键数值范围(如“识别‘Races’列的最小值和最大值”)。格式自解释:模型自动生成表格格式描述(如“表格使用HTML标签,每行由<tr>包裹”)。结构特征提取:输出合并单元格位置、表头类型等(如“第2行第1列跨2行”)。
第二阶段:下游任务优化
结合中间知识:将生成的中间知识作为附加提示输入,优化问答或事实验证任务。
优势:
模型无关性:无需微调,适配GPT-3.5、GPT-4等不同模型。
动态知识注入:通过中间步骤引导模型关注结构特征,减少对显式标注的依赖。
灵活适配多任务:适用于表格问答(HybridQA)、事实验证(TabFact)、文本生成(ToTTo)等场景。
四、实验
4.1数据准备
1.采用五个公开数据集:TabFact、HybridQA、SQA、Feverous、ToTTo,来评估LLM在表格推理和事实验证等任务上的表现。
2.采用不同格式的数据集,包括CSV、JSON、XML、markdown、HTML和XLSX。确定LLM是否有能力正确解析不同的格式源,并确定哪种类型的输入设计最适合LLM。
4.2 SUC基准评估实验结果
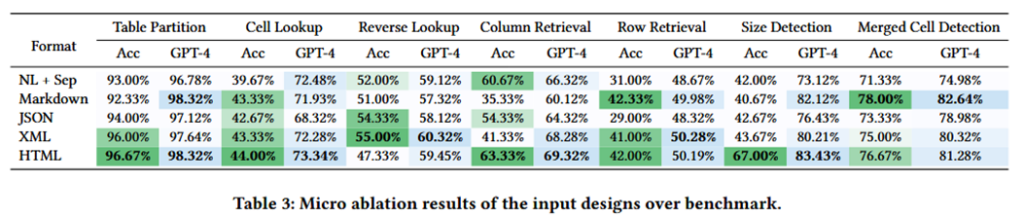

1.HTML格式最优,在表格解析任务上比NL+Sep格式高出6.76%。
2.零样本学习效果较差,系统在零样本条件下的准确率下降约30%。
3.输入顺序影响性能,将外部信息(如问题描述)置于表格前,有助于LLM更好地理解表格结构。
4.格式说明和分区标记的作用:格式说明提高了结构解析任务的准确性,但可能降低检索任务的表现。分区标记在合并单元格检测任务中提升了准确率,但对其他任务影响较小。
4.3 自我增强提示实验
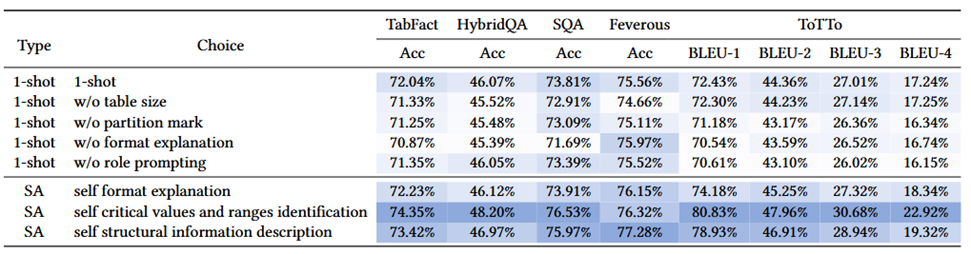
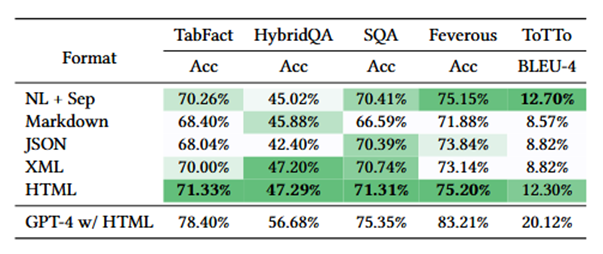
1.自我增强提示(Self-augmented Prompting)显著提升LLM性能:关键数值范围识别方法在HybridQA任务上提高了2.13%,在SQA任务上提高了2.72%。结构化信息描述方法在Feverous任务上提升了1.72%。
2.GPT-4在所有任务上优于GPT-3.5,其在TabFact任务上的准确率提高了6.36%。
五、总结与思考
1. 论文提出了SUC基准测试来评估LLMs的结构理解能力,同时通过实验验证了选择合适的输入设计组合可以显著提高LLMs对结构化数据的理解。
2. 论文同时提出了自增强提示方法,并验证了其在多个表格推理数据集上的有效性。
3. LLMs具有基本的结构理解能力,但远未完美,特别是在一些看似简单的任务上(如表格大小检测)。如何在此论文的基础上更进一步的提升大模型对表格数据的理解能力,是未来探索的关键。