来源:T-PAMI 2024
作者:Zihao Wang,Shaofei Cai,Anji Liu,Yonggang Jin,Jinbing Hou,Bowei Zhang
单位:北京大学
一、背景
实现具有人类般规划与控制能力的通用智能体,在开放世界中基于多模态观测进行任务完成,是迈向更强大通用智能体的关键里程碑。现有方法虽然可以应对某些具有长时序的开放世界任务,但在面对可能无限多的开放世界任务时仍然存在困难,并且缺乏随着游戏时间推移逐步提升任务完成能力的机制。
此外,文章还提出当前的智能体面临三大主要挑战:
- 感知多模态的环境输入,例如图像、视频,以及自然语言指令和反馈,用于任务规划。这主要由于现有基于LLM的规划器在处理多模态数据方面能力有限。
- 具备终身学习与进化的能力,即能够自发提出新任务并自我提升。这是实现通用智能体的关键特征。
- 执行一致且准确的长期规划,这需要多轮的知识密集型、逻辑推理型对话,而这对当前的LLM来说仍是巨大挑战。
二、贡献
文章提出了 JARVIS-1,一个全新的智能体,能够稳定地从用户和环境的多模态输入中生成长期任务的计划,并将这些计划转化为 Minecraft 游戏中的具身动作控制。(Minecraft 是一个流行但极具挑战性的开放世界环境,广泛用于测试通用智能体的能力)
具体贡献如下:
- 从LLM到MLM:将多模态基础模型 MineCLIP 与LLM组合,构建出了一个多模态语言模型(MLM)。使得智能体不再“盲目”规划,而是能够感知当前情境并作出相应计划。此外,借助多模态感知,智能体还能获得丰富的环境反馈,从而更容易实现自我检查与解释,修复计划中的潜在错误,提升交互式规划能力。
- 多模态记忆机制:引入了多模态记忆模块,用来存储以往成功的规划经验及相关场景。通过检索相关记忆条目,智能体可以在上下文中利用自身的游戏经验,从而增强规划能力。与传统的强化学习或规划方法相比,JARVIS-1 无需模型更新,因为 MLM 可以通过上下文直接利用这些经验。
- 自我指令与自我进化:通过自我指令主动提出新任务,并将获得的经验存入多模态记忆中,从而推动更强的推理和规划能力。
三、核心设计
JARVIS-1是一个多模态智能体架构,其中包括交互式规划器、目标条件控制器和由多模态经验构成的多模态记忆系统。
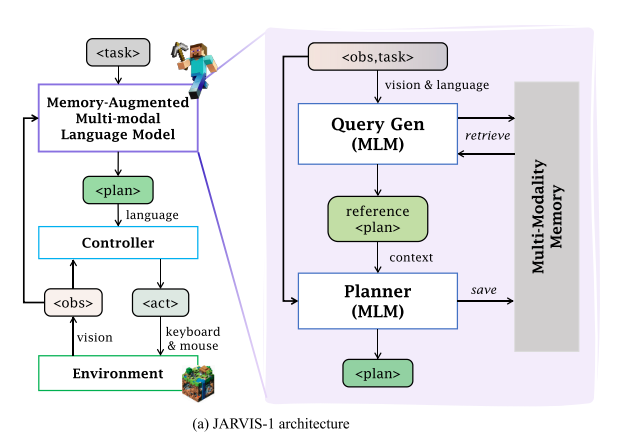
在接收到任务和当前观测后,JARVIS-1 首先利用多模态语言模型(MLM)生成一个多模态查询,从记忆中检索相关的规划经验。随后,这些经验连同任务指令一起用于提示基于 MLM 的规划器。该规划器结合自身的预训练知识与检索到的参考计划,最终生成一系列 K 个短时目标 g1, …, gK,交由控制器执行。当计划成功执行后,将连同任务指令和当时的智能体状态一起存入记忆中。
1. 基于 MLM 的交互式规划
采用零样本的多模态语言模型(MLM)作为规划器,并结合交互式规划框架来解决动态观测执行长时任务的挑战。
- 利用 MLM 进行情境感知规划:将视觉输入转化为文本描述。
- 使用自我检验进行规划验证:模拟执行流程,预判是否达成目标,提前修改。
- 利用环境反馈进行交互式规划:结合失败原因与当前状态重新生成计划。
2.引入多模态记忆的规划机制
- 采用检索增强生成(RAG)来增强 JARVIS-1 的长期规划能力。与以往 RAG 方法使用外部知识库不同,我们将收集到的多模态记忆作为知识库,并从中检索交互式经验作为示范提示,从而增强规划效果。
- 多模态记忆结构:键值对记忆库,其中键是多模态的,包括任务和该记忆条目被记录时的观测(即情境);值是当时成功执行的计划。
- 基于推理的查询生成:当接收到一个任务指令时,通过语言模型的推理能力将其分解为子任务或相关任务,并将其作为文本查询,用于检索参考计划。
3.智能体的自我提升机制
- 探索阶段:JARVIS-1 依据当前能力选择任务 → 执行 → 存储经验。
- 终身学习:随着记忆积累,能力提升(无需梯度更新),在后续游戏中成功率持续上升。
四、实验
环境设置:文章在《Minecraft》中评估 JARVIS-1,所选任务来自 Minecraft Universe Benchmark。选择使用《Minecraft》原生的人类界面,这适用于观察空间和动作空间。模型以 20 帧每秒的速度运行,并在交互时需使用鼠标和键盘界面。
任务设置:在《Minecraft》中,玩家可以获取上千种物品,每种物品有特定的获取条件或合成配方,在生存模式中,玩家必须从环境中获得物品,或通过合成/冶炼得到目标物品。文章在 Minecraft Universe Benchmark 中选择了超过 200 个任务进行评估,这些任务涉及可以在主世界中获得的物品。为便于统计,根据 Minecraft 的推荐分类将任务划分为 11 个组。由于任务复杂度不同,为每个任务设置了不同的最大游戏步数,该限制根据人类完成该任务的平均时间设定。
评估指标:默认情况下,智能体总是在生存模式下开始,且初始背包为空。当在规定时间内获得目标物品,即视为任务成功。
1.与其他基于大语言模型的多任务指令跟随智能体的比较,JARVIS-1 在所有元任务上都取得了最佳表现。
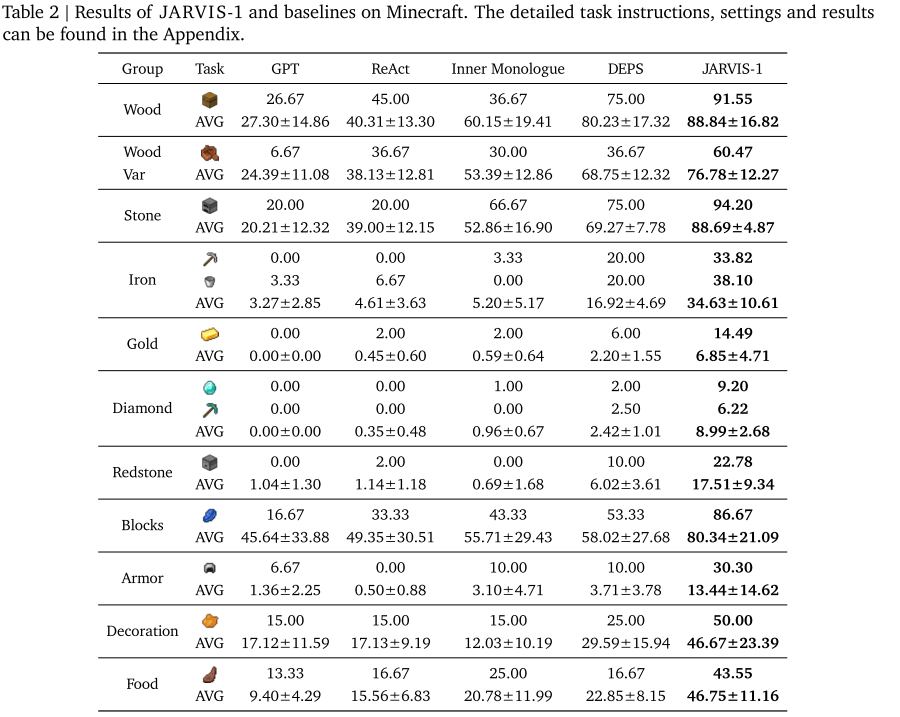
在 11 个任务组中(木头、石头、铁、钻石、食物等),JARVIS-1 表现显著优于现有方法,如 DEPS、ReAct、Inner Monologue 等,尤其在钻石组任务中提升显著。
2.基于不同语言模型的 JARVIS-1
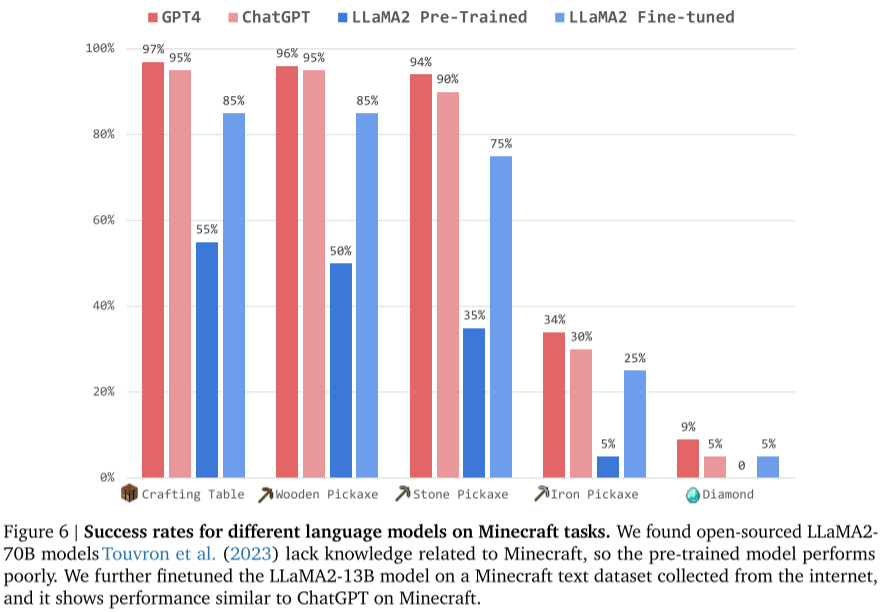
使用 GPT-4、ChatGPT、开源 LLaMA2(原始和微调版)对比,结果显示:
- ChatGPT 已接近 GPT-4 表现;
- 微调后的 LLaMA2-13B 表现大幅提升;
- LLaMA2-70B 原始模型缺乏 Minecraft 知识,表现较差。
五、总结
JARVIS-1 在以下方面实现了突破:
- 对多模态输入具备感知与理解能力;
- 支持长期任务的稳定规划与执行;
- 具有自我生成任务、自我改进的能力;
- 无需梯度更新即可实现终身学习。
这一工作为构建通用智能体迈出了重要一步,特别是在复杂、开放的环境中具备可持续进化能力。
六、启发
JARVIS-1通过建造一个视觉+语言能力的记忆库,使用历史成功的任务经验作为参考,在上下文中引导当前的任务规划,以及自我指导与自我改善机制,从而实现无需再度训练而持续进步的效果。在对抗性临时决策中,此类记忆功能更具可行性,通过对已有成功记忆库的检索,使得获取新策略的速度加快,临场效果实现具备可行性。