来源:Bioinformatics
作者:Karthik Soman、Rabia E. Akbas、Braian Peetoom、Gabriel Cerono等
单位: University of California、Institute for Systems Biology
发表时间:2024年09月
一、论文介绍
背景:当前,尽管LLM在通用任务中表现优异,但开源模型在医疗领域面临知识局限性、幻觉风险和隐私担忧三大挑战。尽管有预训练和特定领域微调等解决方案,但这些方法增加了计算开销和领域专业知识的需求。
核心:基于上述背景,本研究提出了一个名为KG-RAG的框架,通过结合知识图谱和LLM,显著提高了LLM在生物医学领域问答任务中的性能。该框架利用SPOKE知识图谱提供丰富的生物医学背景知识,通过优化的检索和生成机制,减少了token使用量,提高了模型的效率和鲁棒性。
二、整体框架
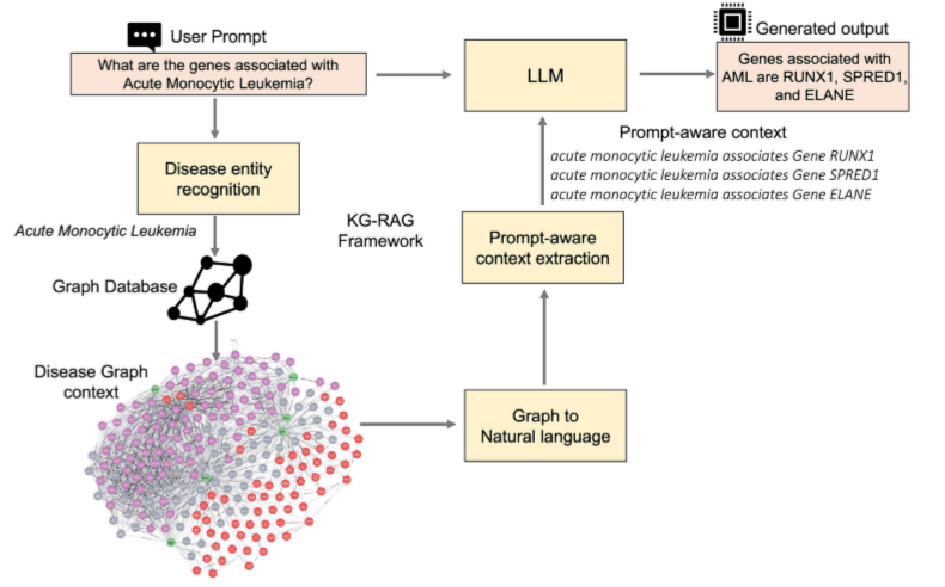
- KG-RAG框架:展示了KG-RAG框架的架构,包括疾病实体识别、疾病上下文检索、上下文修剪、大型语言模型等步骤。在医疗问答系统中,用户输入的提示首先被传递到疾病实体识别模块,以识别出特定的疾病实体。接着,系统利用这个疾病实体在图数据库中进行查询,提取与该疾病相关的上下文信息。然后,这些信息被转换为自然语言文本,并根据用户提示进行上下文修剪,以确保只有最相关的信息被用于生成回答。最后,修剪后的上下文信息被输入到大型语言模型中,生成最终的输出结果。整个流程展示了如何从用户提示出发,通过疾病实体识别、图数据库查询、上下文提取和转换,最终利用大型语言模型生成准确的回答。
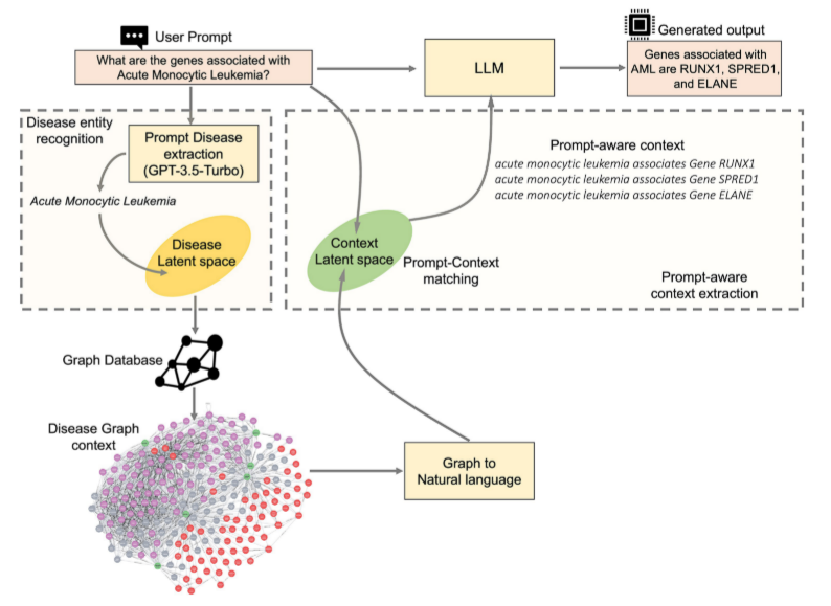
2. KG-RAG详细图:展示了KG-RAG框架中疾病实体识别和即时感知上下文提取的细节,包括实体提取、实体匹配、上下文提取、谓词到自然语言的转换等步骤。
疾病实体识别
用户提示输入:用户输入一个关于“与急性单核细胞白血病相关的基因”的问题。
实体提取:系统使用一个预训练的语言模型(如GPT-3.5-Turbo)从用户提示中识别和提取出特定的疾病实体,在这个例子中是“急性单核细胞白血病”。
疾病潜在空间:提取出的疾病实体被映射到一个潜在空间,这个空间可能包含了疾病的多种特征和相关信息,用于后续的匹配和检索。
上下文修剪:根据用户提示,系统使用提示-上下文匹配技术从转换后的自然语言文本中提取与问题最相关的上下文信息。这一步骤确保了只有最相关的信息被用于生成回答。
三、实验内容
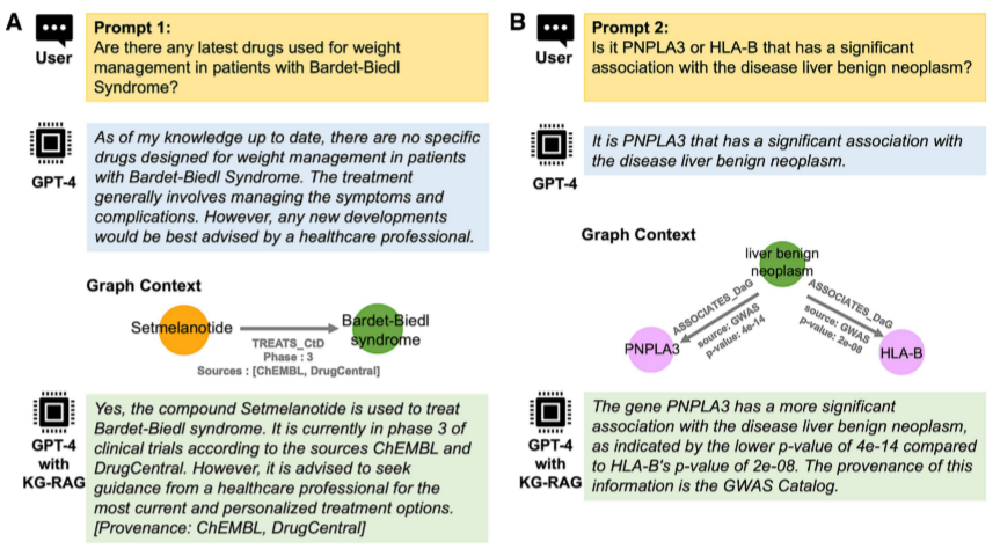
验证KG-RAG框架优势:比较GPT-4在没有知识图谱支持的情况下与使用KG-RAG框架时的回答差异,突出KG-RAG在提供更准确和详细回答方面的优势
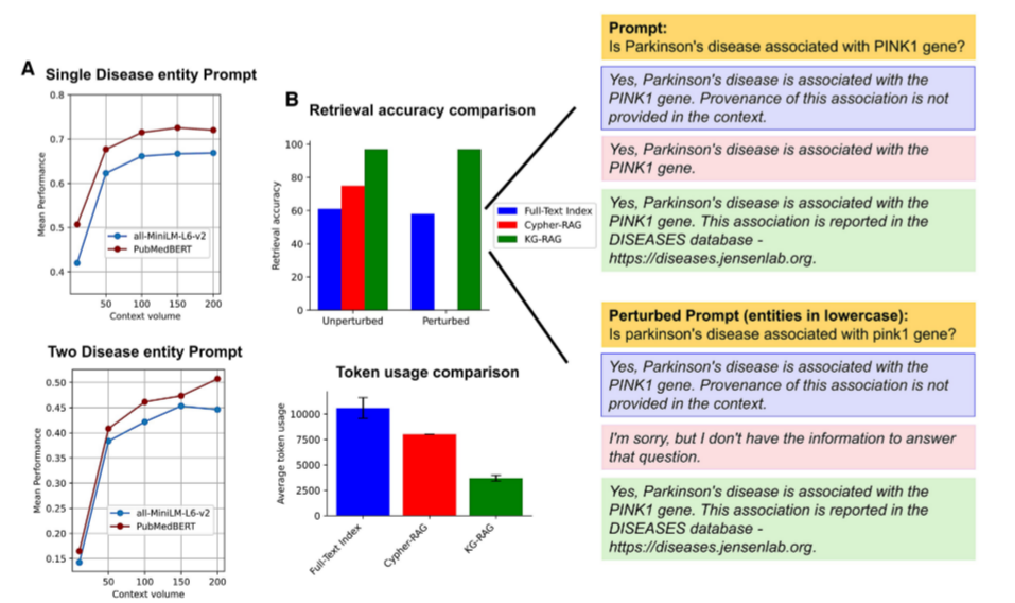
超参数分析与RAG比较:A部分是使用提示符的超参数分析性能曲线,B部分是KG-RAG、Cypher-RAG和使用Apache Lucene的全文索引在检索精度和令牌使用方面的对比分析
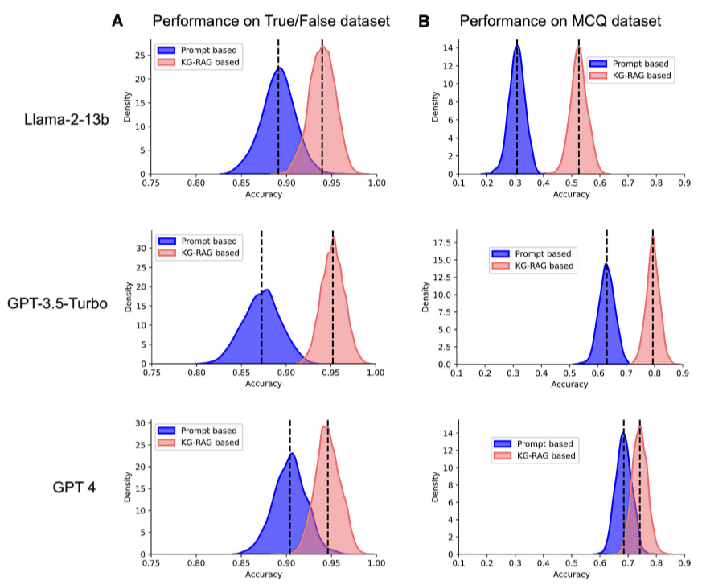
三个LLM在True/False和MCQ数据集上的性能:在KG-RAG框架下,LLM模型在True/False和MCQ数据集上的性能都有一致的提高
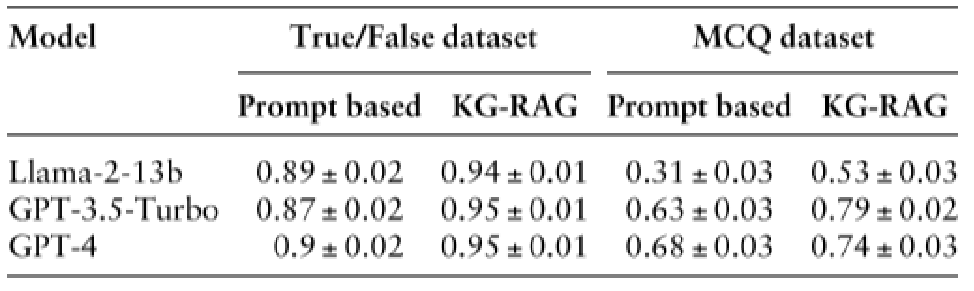
比较基于提示的方法和基于KG-RAG的方法在不同LLM上的性能表现:有图可知,基于KG-RAG的方法在大多数情况下表现更好,尤其是在True/False数据集上。这表明KG-RAG在处理需要精确知识检索的任务时具有优势。
四、论文总结
这篇论文提出了,一个知识图谱增强检索生成框架KG-RAG,其中KG-RAG的贡献和缺点可总结为三点:
1. 标记高效优化: 嵌入驱动的上下文剪裁与最小图谱提取,可节省超50%令牌开销,显著优化RAG在生物医学场景的部署成本。
2. 解决 LLM 幻觉问题并提高性能:KG-RAG 将 SPOKE KG 知识融入 LLM,避免幻觉信息,生成带出处和统计证据的可靠生物医学文本;
3. 领域与更新局限 :依赖于LLM模型选择和更新,对知识图谱质量和更新有较高要求,且决策过程可解释性不足。
五、对齐思考
KG-RAG框架的研究为中西医结合慢病调理的知识问答系统提供了关键技术启示:
1.知识融合优化:借鉴最小图模式与嵌入剪裁策略,跨域整合中医症候、西医病理等异构实体,降低50%以上知识检索冗余,支持高效知识融合。
2.可信来源锚定:结合SPOKE式的溯源机制,融合古籍文献与现代循证证据,增强答案的可解释性,实现中西医理论的源头互证。
3.知识图谱更新:建立知识图谱更新机制,定期从最新文献、数据库等来源获取信息,确保知识的时效性和可靠性。