来源:ICML 2024
作者:Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, Siyuan Huang
单位:北京通用人工智能研究院,北京大学,卡内基梅隆大学
一、背景
在人工智能和神经科学领域,构建一个能够处理各种综合任务的通用模型一直是研究者们长期追求的目标。而现有的通用模型在二维领域的成就虽然显著,但它们在三维空间的理解上却显得力不从心,这成为了它们在解决现实世界任务和接近人类智能水平时的一大障碍。为了克服这一限制,文章提出了一个核心问题:如何使智能体不仅能够全面理解真实的三维世界,还能与之进行有效的交互?在探索这一问题的过程中,文章发现智能体的发展面临三个主要的挑战:
- 学习策略的不足:在视觉语言学习(VLA)的潜力和大型语言模型(LLM)对三维任务的适应性方面,还有很多未被充分探索的问题。
- 数据集的缺乏:与二维数据相比,三维数据的收集成本更高,这限制了模型训练和验证的广度和深度。
- 统一模型的缺失:以往的三维视觉语言(3D VL)模型并没有经过大规模的统一预训练,也没有有效的微调策略,这些模型通常基于强先验设计,而缺乏灵活性和泛化能力。
二、贡献
为此,文章引入了多模态通用智能体LEO,它能以自我视角的2D图像、3D点云、文本作为任务输入,在3D环境中处理综合性任务。
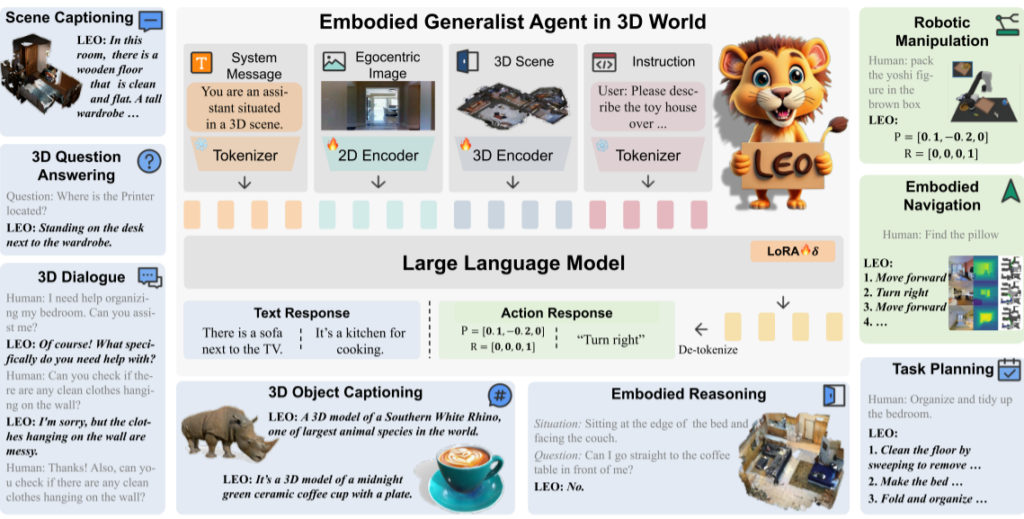
具体贡献如下:
- 提出 LEO——首个 具身通用智能体,能够遵循人类指令,在三维世界中执行 感知、定位、推理、规划和行动 等任务。
- 设计了一种简单而高效的框架,通过 对象中心的三维表示 连接 大语言模型,高效地弥合视觉、语言和具身行动之间的鸿沟。
- 构建了大规模综合数据集,用于两阶段通用智能体训练方案,并特别设计了一条 LLM 辅助的数据生成流程,以 生成高质量的三维视觉-语言(3D VL)数据。
- 进行了广泛的实验,验证了 LEO 在多个任务上的卓越能力,并提供了深入分析,揭示有价值的研究见解。
三、核心设计
LEO 采用一个统一的任务接口、模型架构和目标函数,将 3D 视觉、语言和行动任务统一到一个序列预测框架中。
- 多模态编码器:
- 2D 图像编码器:用于处理具身视角的 2D 图像信息。
- 3D 点云编码器:用于处理三维场景和对象信息。
- 文本编码器:用于理解指令和任务描述。
- 统一解码器
- 采用 LLM 作为核心解码器,使用 LoRA 技术进行微调。
- LLM 生成文本响应或具身行动指令,实现多任务处理
- 任务序列化
- 采用 GPT 风格的自回归语言建模
- 所有任务都被转换为序列预测问题
四、数据集
为了LEO能够接收多模态输入并遵循指令,文章采用两阶段训练方法,并将数据分成两组:
- LEO-align(3D 视觉-语言对齐):用于3D场景表示与自然语言之间的对齐,弥合3D场景表示与自然语言之间的差距
- LEO-instruct(3D 任务指令学习):针对 3D 视觉-语言-动作(3D VLA) 指令调优,赋予LEO各种泛化能力。
产生大量LEO-align和LEO – instruct数据集的核心是用LLM辅助生成3D文本配对数据:
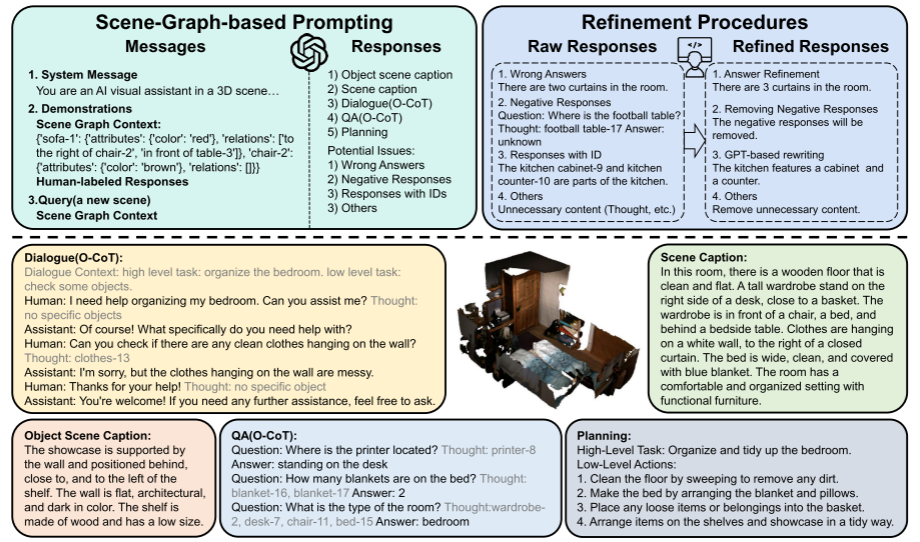
五、实验
- 3D视觉语言理解和推理:
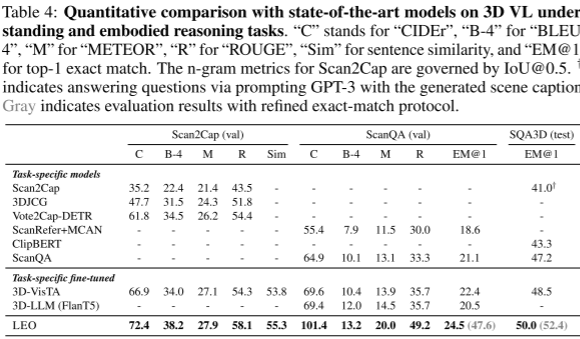
- 实验:量化对比 LEO 与SOTA级 3D VL 模型的性能,验证其 3D 视觉语言(VL)理解和推理能力。文章考虑了三个著名的3D任务:Scan2Cap上的3D字幕描述,Scan-QA上的3D问答,以及SQA3D上的3D具体化推理。
- 结果:LEO在3D密集字幕描述和3D QA任务上明显优于最先进的单任务和特定任务微调模型。与使用特定任务头部的专家模型相比,文章基于LLM的方法不仅提供了生成开放式回复的灵活性,而且还展示了出色的定量结果。
- 情景对话和规划:
- 实验:为了验证LEO的3D视觉语言的理解和推理能力,文章对3D对话和规划任务进行定性研究,并从LEO – instruction的测试集中使用模型未见过的场景测试。
- 结果:LEO能够生成高质量的回复,它具有两个特点:1)精确对应到3D场景:LEO提出的任务规划涉及与3D场景相关的具体对象,以及这些对象相关的合理动作。2)丰富的信息性空间关系。LEO的回答中的实体通常伴随着详细的描述。

- 三维世界中的具身动作:
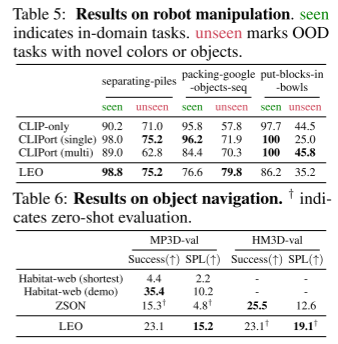
- 实验:文章选择了两个典型的具身化AI任务:AI Habitat上的对象导航和CLIPort上的机器人操作。
- 结果:1)在机器人操作方面,LEO的性能可与最先进的性能相媲美,在一些具有挑战性的未知任务上甚至更胜一筹。2)在对象导航中,LEO实现了与基线相当的成功率,并且在MP3D-val上具有更好的SPL,这表明LEO可以利用以物体为中心的3D场景输入并采取更短的路径到达目标。
六、总结
文章提出的智能体LEO将当前LLM的通用能力从文本扩展到三维世界和具身化任务,结果表明:
(1) 通过对统一的模型进行与任务无关的指令调优,LEO在大多数任务上达到了最先进的性能,特别是超过了以前的特定任务模型;
(2) LEO精通情景对话和规划,能够产生灵活和连贯的反应;
(3) LEO在导航和操作任务上的性能可与当前最先进的特定任务模型相媲美,具有显著的泛化能力;
(4) LEO的强大性能源于数据和模型两个方面,包括对齐阶段、数据多样性、通用的指令调优和以对象为中心的表征;
(5) LEO表现出的规模效应规律印证了先前的研究结果。文章还展示了定性结果,以说明LEO的多功能性和熟练程度接地3D场景的理解。
七、启发
文章中通过对二维图像数据,三维点云数据和文本信息进行多模态编码,用LLM进行统一解码生成文本响应或具身行动指令的这一过程可以借鉴:
在临场对抗决策的推理中,可以考虑使用这种序列化的编码和解码方式,去掉三维点云数据,使用二维图像数据和文本信息进行编码,通过LLM解码生成文本响应和行动指令,其中重点放在行动指令的生成,即对抗性决策的生成,而文本响应可以作为语言描述的中间体,对整体信息进行反馈和调整。