作者:Zhang Jingxuan,Mao Tingzhi等
单位:陕西师范大学,科大讯飞
来源:Expert Systems With Applications 2025
一、主要内容
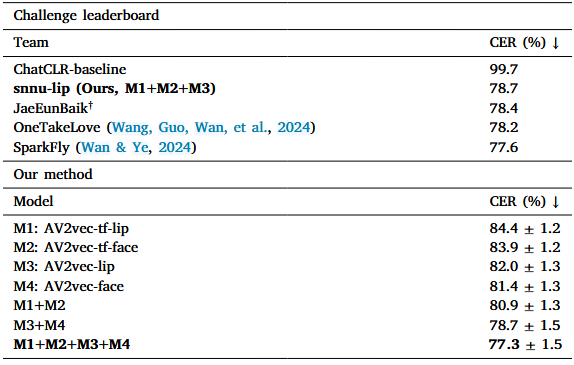
自监督预训练模型在除英语外的其他语言中面临缺乏视听数据的挑战,大多数研究集中在说话人无关的唇读模型上,对此提出跨语种迁移学习,通过说话人适应策略提高针对特定目标说话人的唇读准确性,引入模型集成策略,结合唇读的唇部区域和面部输入的互补性能,在ChatCLR上达到77.3%的字错率的性能。
二、方法
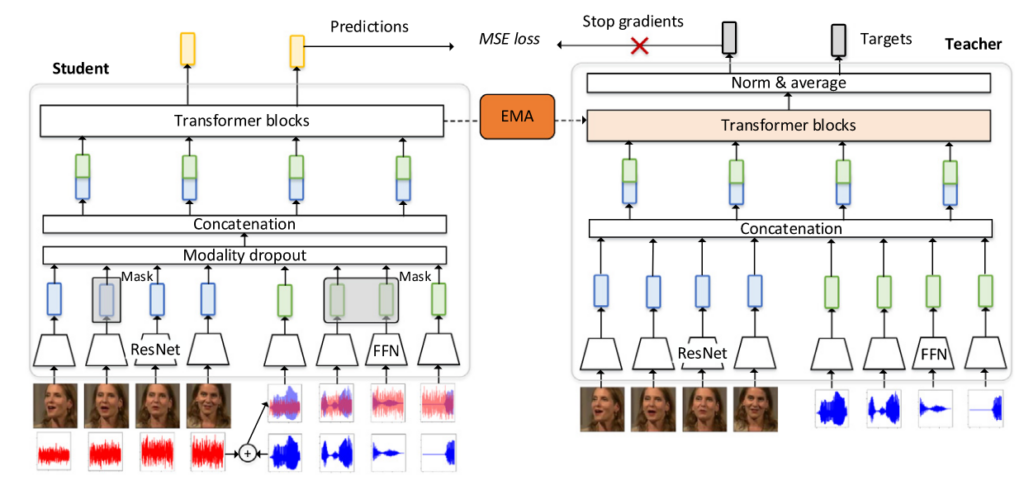
AV2vec视听自监督模型
AV2vec通过多模态自蒸馏来学习通用的视听表示,由一个学生模块和一个教师模块组成,学生模块通过掩蔽潜在特征回归任务记性训练,由教师模块在线生成目标。
提出的方法
包括三个阶段,第一阶段在视听数据上自蒸馏预训练,第二阶段在多说话人视听数据进行唇读微调,第三阶段对目标说话人微调。
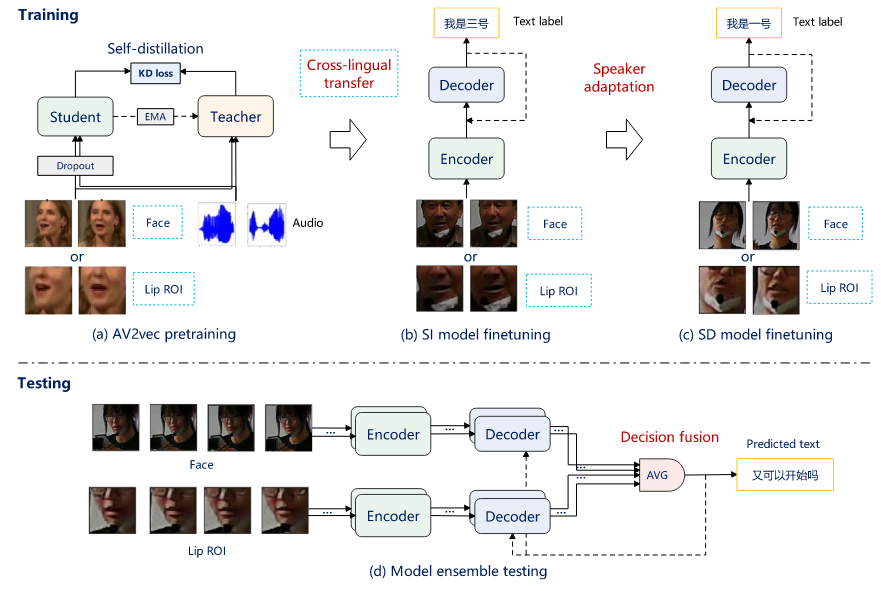
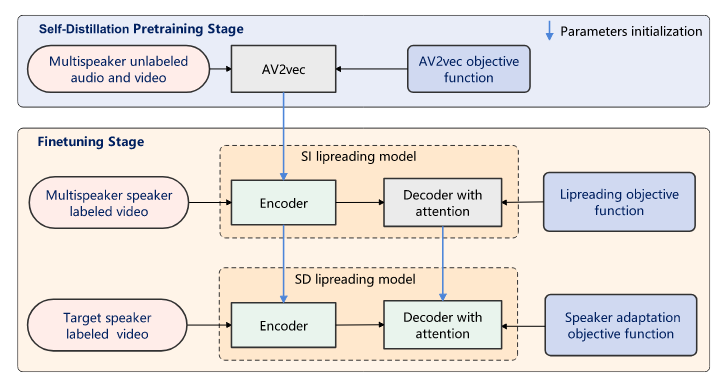
第二阶段,AV2vec作为编码器省略音频分支,使用联合CTC/注意力框架,使用CE损失和CTC损失优化网络。

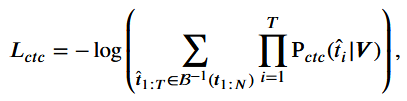
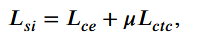
根据源语言预训练的AV2vec模型对目标语言进行混合CTC/注意力损失微调,AV2vec学习跨语言共享的视觉表示。这种策略可以减轻视听自监督预训练的高计算成本,微调过程中,将编码器模型参数冻结k个步骤,随后和解码器共同优化,但对于AV2vec的迁移学习,编码器参数不冻结,和解码器一起优化。
第三阶段,对于说话人适应的目标说话人视频数据,以较小的学习率更新,由于目标说话人的训练数据少,可能会过拟合,引入额外的KL散度损失:
说话人适应的总损失是交叉熵损失,CTC损失和KL散度损失的加权和:
集成学习通过汇总多个模型的预测来提高整体模型的性能。通过平均面部和唇部区域的唇读概率分布来采用这种方法。
三、实验
数据集
测试集:ChatCLR挑战的任务2。训练数据集为LRS3、CNCVS和CHATCLR2。预处理:随机裁剪88×88,0.5概率随机翻转,测试时中心裁剪88×88,不水平翻转。官方验证集标签保密,使用内部验证集验证。
实验结果
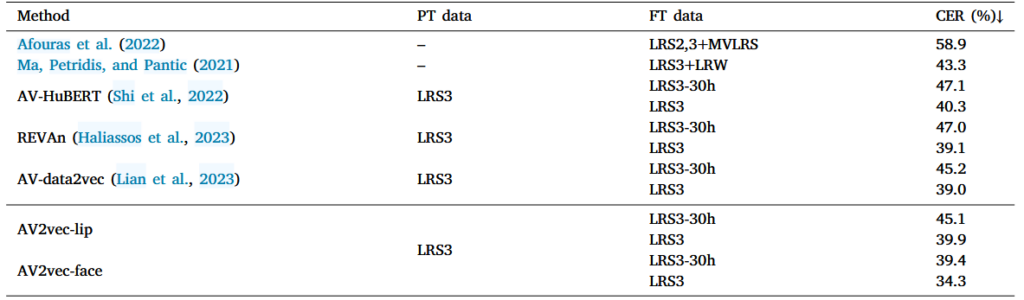
在LRS3上的唇读结果:
在ChatCLR2验证集上的结果:
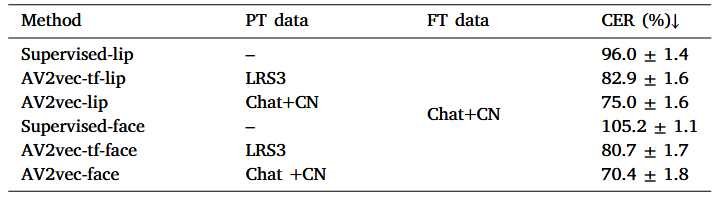
有监督脸部区域和有监督唇部区域相比表现更差,表明在没有自监督学习的情况下,面部信息可能会损害唇读精度。跨语种迁移学习结果比随机初始化模型好,证明了提出的跨语种迁移学习对中文唇读的有效性,但比直接用中文数据预训练的模型性能差。AV2vec模型会受益于全面部输入。
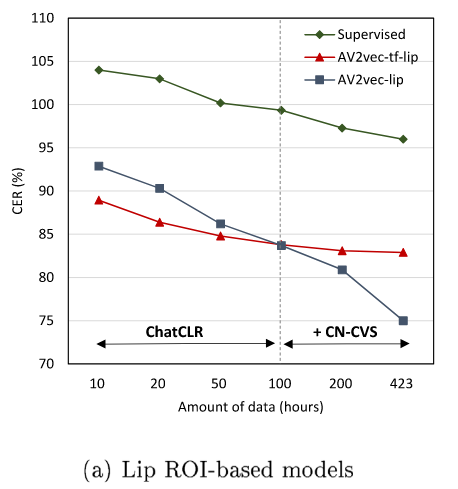
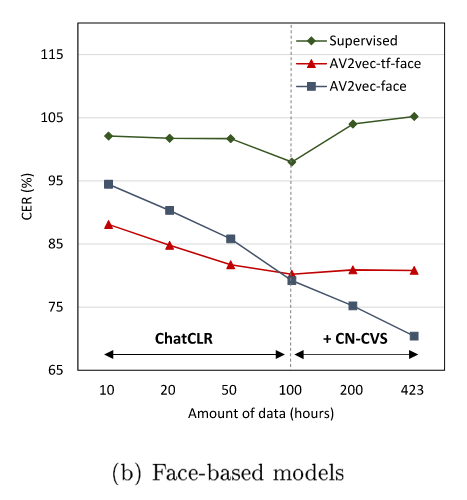
模拟目标语言数据限制的情况,随着可用中文视频数据的减少,迁移学习和用中文预训练之间的性能差距减小。只用10h标记数据可用时,迁移学习由于预训练,说明了跨语种迁移学习在低资源语言上的有效性。
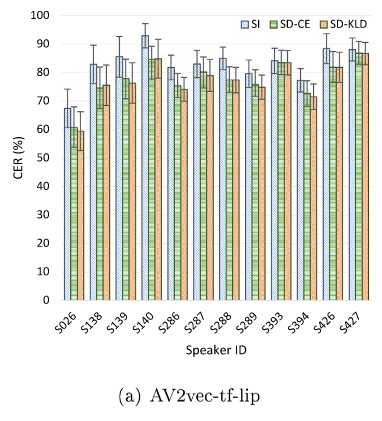
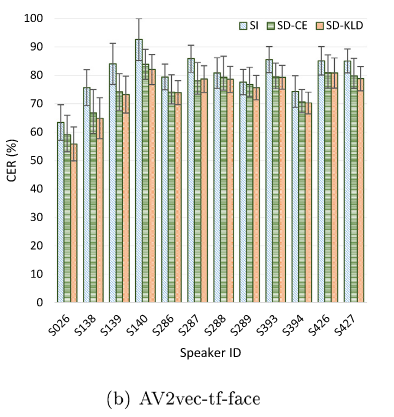
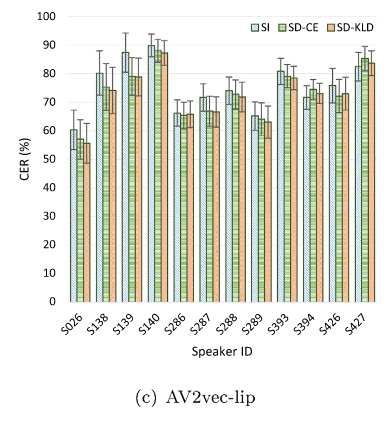
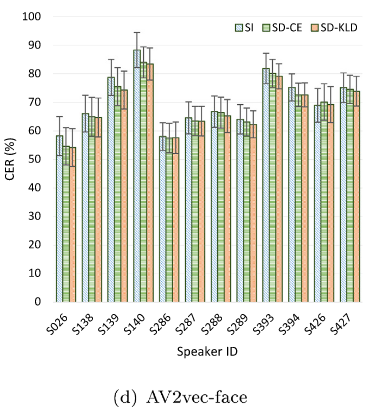
说话人独立模型显示出较高的错误率,说话人适应技术有效降低了字错率。KL散度正则化模型在大多数说话人上的表现优于非正则化模型。
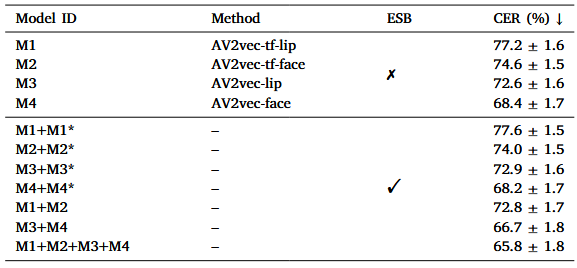
结合基于面部的模型和基于唇部的模型可以实现对单个模型的实质性改进。
全脸和相应的唇部视频帧的示例,以及唇语识别结果。

四、总结
中文唇读任务的固有难度,唇读方法易受语言、说话风格和数据质量的变化的影响。进一步提高此任务的唇读性能的一种关键方法是收集或综合中文的更多视听数据,从其他语言中迁移学习也是一种有效的方法。
跨语种迁移学习不仅节省了训练成本,而且在目标语言中的数据有限时会表现出更好的唇读结果。验证了说话者适应的有效性以及将模型与唇彩和面部输入相结合的策略。