作者:Yujia Zhou,Qiannan Zhu
单位:中国人民大学信息学院
来源:Arxiv
时间:2024年2月
背景
传统搜索引擎为所有用户提供相同结果,忽略用户个性化需求。例如,不同用户对同一关键词可能有不同的兴趣点,但传统搜索无法区分。
深度学习方法虽在个性化搜索中表现出色,但依赖大量训练数据,数据稀疏时性能大幅下降。
用户的历史交互记录随时间积累,数据量庞大且复杂,直接处理这些数据不仅计算成本高,还可能超出LLMs的输入长度限制。
个性化搜索需要处理大量用户数据,如何在模型训练和使用过程中保护用户隐私是一个亟待解决的问题。
研究内容
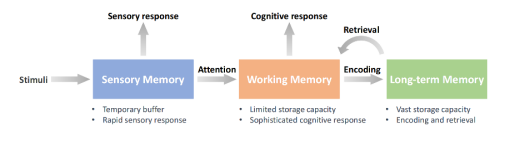
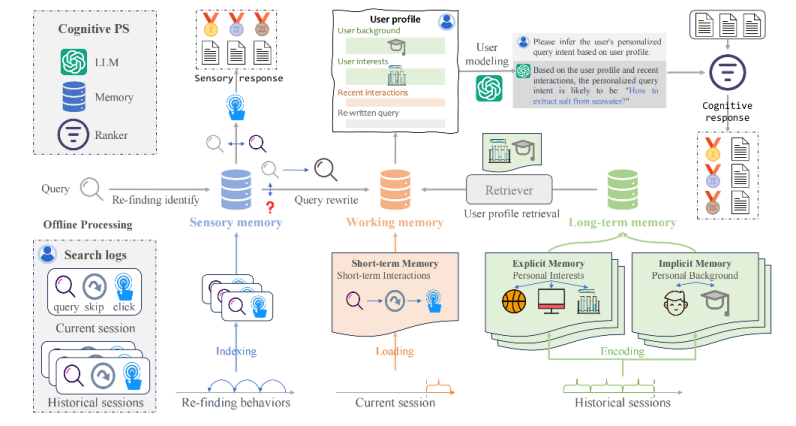
感觉记忆用于快速识别用户重复查找行为,通过记录用户历史数据中的查询和点击文档配对,实现对重复查找的即时响应。
工作记忆负责临时存储和整合与当前任务相关的信息,通过分析相关交互、上下文交互和重写查询,捕捉用户的个性化查询意图。
长期记忆存储用户的长期兴趣和习惯,通过分段和编码用户历史,保留最突出的个性化信号,显式记忆和隐式记忆分别捕捉用户的特定兴趣和背景信息。
实验设置与数据集
选择AOL搜索日志数据集和商业数据集进行实验,使用前85%的交互数据作为用户历史,后15%的查询用于测试。
使用MAP、MRR、P@1和P- improve等指标评估模型性能,选择多种基线模型进行对比。
实验结果与讨论
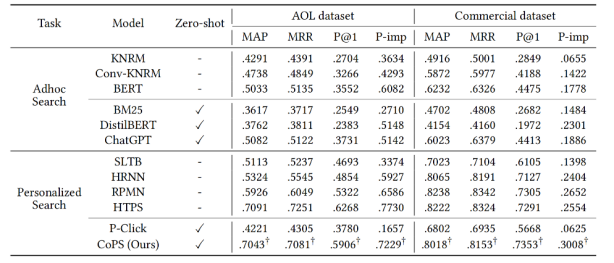
CoPS在零样本场景下优于现有方法,与微调模型相当,证明了其在个性化搜索中的有效性。
例如,在AOL数据集上,CoPS的MAP指标比零样本基线P- Click提高了66.8%。
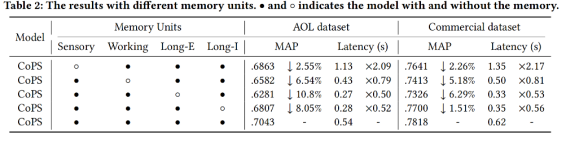
记忆单元的贡献分析
不同查询类型的表现
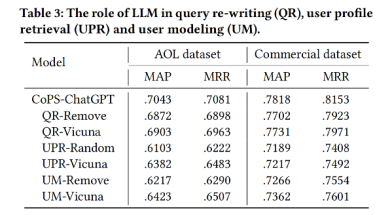
结论
CoPS模型通过模仿人类认知记忆机制,有效解决了个性化搜索中的数据稀疏和复杂性问题,为未来的研究提供了新的方向
尽管CoPS取得了显著成果,但在模型效率和隐私保护等方面仍有待进一步优化,以满足实际应用中的需求。