作者:Aishwarya, Vijayan
单位:Department of Computer Science, University of Illinois Chicago
发表日期:2023.12
来源: ACM
一、论文介绍
背景动机:
1.非结构化文本的挑战:大量电子邮件、社交媒体和文档缺乏统一格式,难以存储和查询。
2.大语言模型(LLM)提供的新机遇:LLMs 具备强大的信息提取能力,结合 Prompt Engineering 可提高准确性。
3.信息结构化的价值:将非结构化文本转换为结构化数据,提升信息管理和查询分析的效率。
研究目标:
提出一种基于Prompt Engineering的LLM方法,用于从非结构化文本(如电子邮件)中提取旅行信息(如旅行者、出发地、目的地、时间等),并存入关系数据库以支持SQL查询。
二、核心内容
信息提取模型架构:
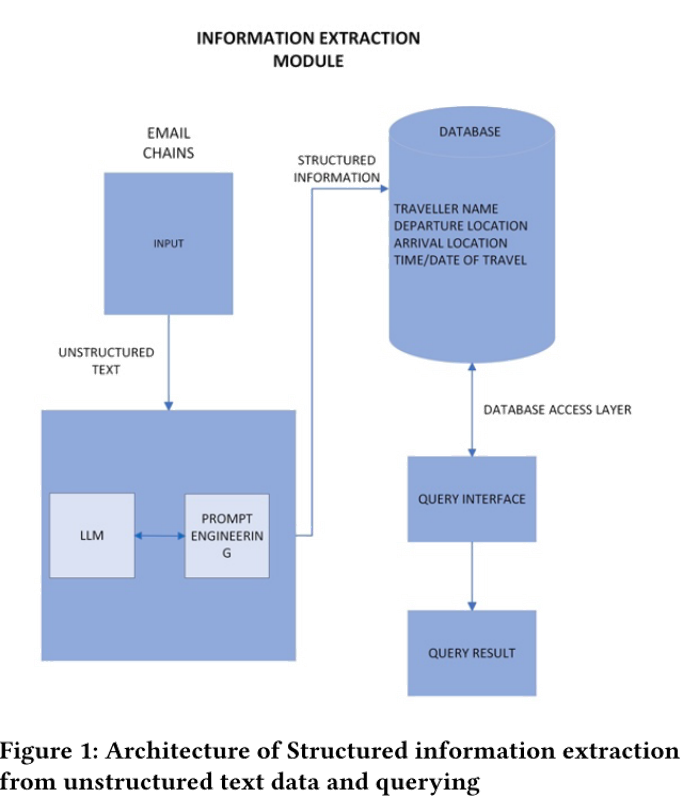

1.标准prompt
直接输入完整邮件 + 预设指令,让 LLM 提取旅行信息。
问题:
容易遗漏关键信息,ChatGPT 甚至生成幻觉数据。
提取出的数据中,缺少出发时间、到达时间等多个字段,仅部分信息正确。

2.迭代优化 Prompt
通过 多轮交互优化 Prompt,逐步改善提取结果,减少遗漏信息。
相比标准 Prompt:
标准 Prompt 只能进行单次提取,可能遗漏关键信息,而迭代优化 Prompt 不断调整指令,直到提取完整。

3.思维链 Prompt
采用逐步推理方式,引导 LLM 按逻辑拆解问题,减少遗漏信息。
优势:
比标准 Prompt 提取更完整的信息,但仍可能遗漏部分字段。

4.Persona Prompt(角色设定提示)
让 LLM 按照特定身份进行信息提取,提高输出的上下文相关性和一致性。适用于需要专业判断的任务,如医疗、法律、财务等领域的信息提取。
优势:
能更好地理解上下文,减少误提取

三、实验评估
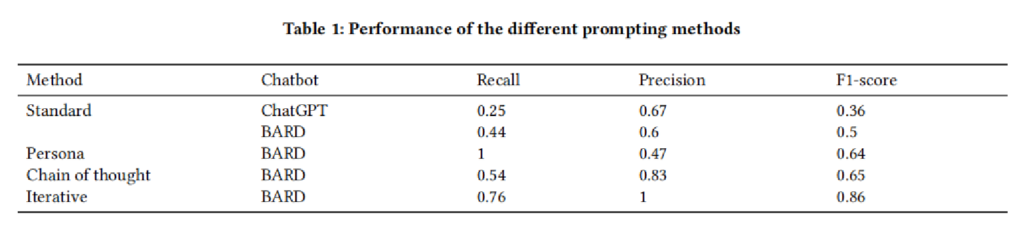
不同 Prompt 方法对信息提取效果的影响
迭代优化 Prompt 取得最高 F1-score(0.86),在 Recall 和 Precision 之间实现最佳平衡。
四、总结思考
论文总结:
1.研究探索了不同 Prompt 方法对 LLM 进行结构化信息提取的影响。
2.标准 Prompt 易遗漏关键信息,Persona Prompt 召回率高但误提取多,思维链 Prompt 提升了精准度,但 Recall 仍不足。
3.迭代优化 Prompt(Iterative)通过多轮交互优化,F1-score 最高(0.86),是最优方法。
启发思考:
1.Prompt 设计对数据预处理质量至关重要:
在 RAG 预处理中,合理的 Prompt 设计可以优化知识库数据提取,提高数据质量,从而减少后续深 度思考和推理的计算成本。
2.迭代优化 Prompt 适用于知识库数据清洗与格式化:
可以采用动态 Prompt 迭代优化机制,逐步修正数据提取结果,确保知识库中的数据更加完整、精准,进而提升 RAG 的检索效果。
3.思维链 Prompt 适用于知识库的分层提取策略:
思维链(Chain of Thought)Prompt 采用逐步推理, RAG 知识库构建中可用于先提取关键信息,再进行上下文关联,最终生成结构化数据,以提高知识库质量。