来源:KDD ’24, August 25–29, 2024
作者:Yunfei Liu, Jintang Li, Yuehe Chen….
单位:蚂蚁集团
一、论文主要工作及贡献
(1)建立了模块化最大化和图对比学习之间的联系。 本文的研究结果表明,模块化最大化可以被视为利用图中的潜在社区信息进行对比学习。
(2)Magi 通过利用底层社区结构来避免语义漂移,并消除了图增强的需要。 Magi 采用两阶段随机游走方法,以小批量形式执行模块化最大化任务,从而实现良好的可扩展性。
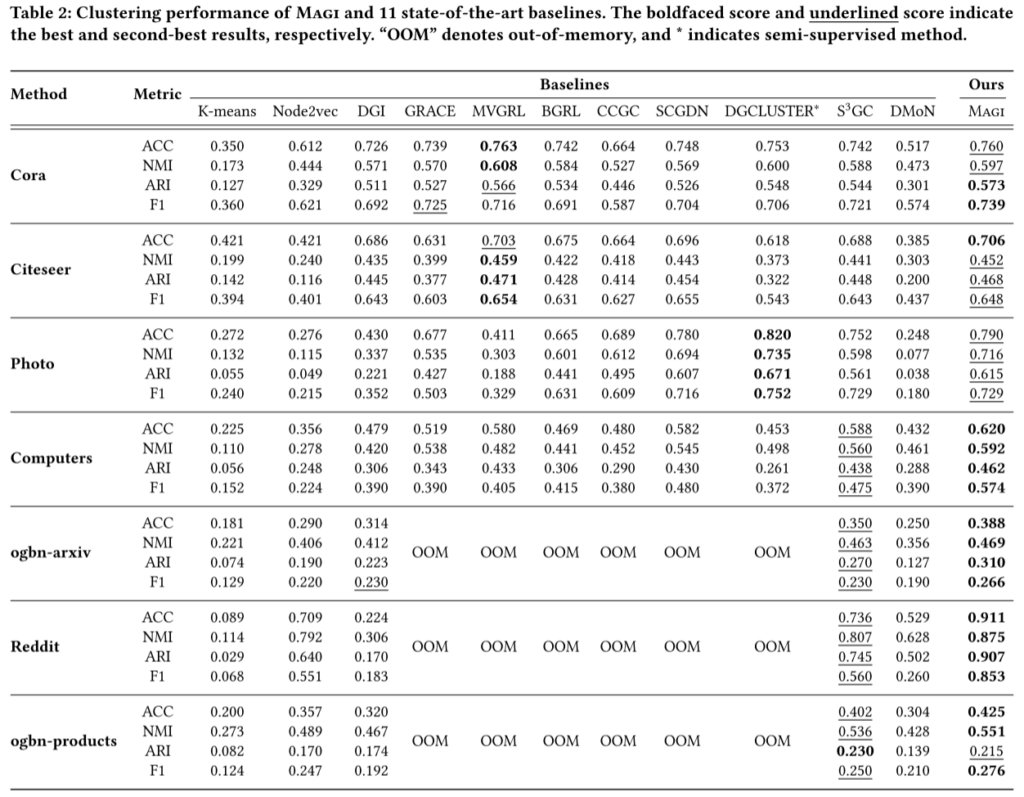
(3)作者对 8 个不同尺度的真实世界图数据集进行了广泛的实验。 Magi 在图聚类任务中始终优于多项最先进的技术。 值得注意的是,Magi 可以轻松扩展到具有 100M 节点的工业规模图,展示了其在大规模场景中的可扩展性和有效性。
二、模型框架
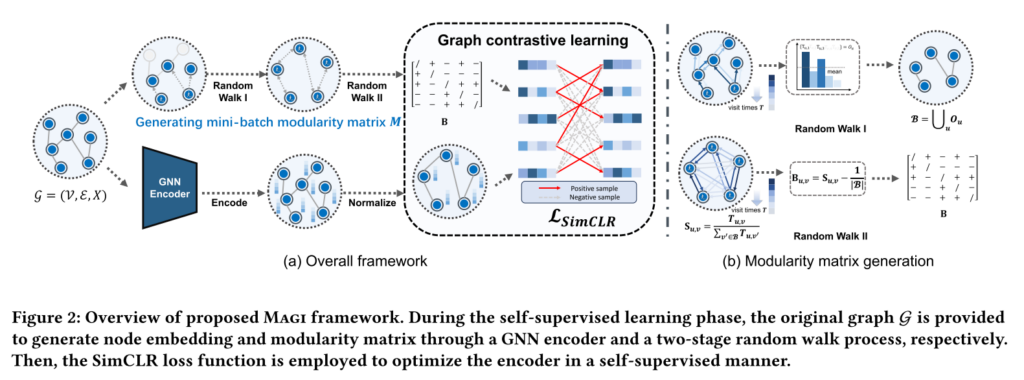
2.1 Modularity maximization pretext task
为了适应小批量训练以获得良好的可扩展性,一个直观的想法是随机采样图中的𝑛节点,并从其相应的子模块矩阵中获得对比对。但是这样会产生一些问题:
结构偏差:所采样的结构不能代表完整的图结构;
缺乏高阶邻近性:两个节点通常由于高阶邻近性而属于同一社区,例如具有许多共同的邻居。
作者提出了一种基于两阶段随机游走的采样方法来解决上述挑战,通过调整随机游走的深度,可以有效地捕获网络内的高阶邻近度。
采用第一阶段随机游走对多个子社区进行采样,并将它们合并到训练批次中,确保该批次内的相应子图包含有效社区。
执行第二阶段随机游走以生成批次内节点之间的相似度矩阵,并利用配置模型的概念以小批量形式计算相应的模块度矩阵。
2.2 Contrastive loss formulation
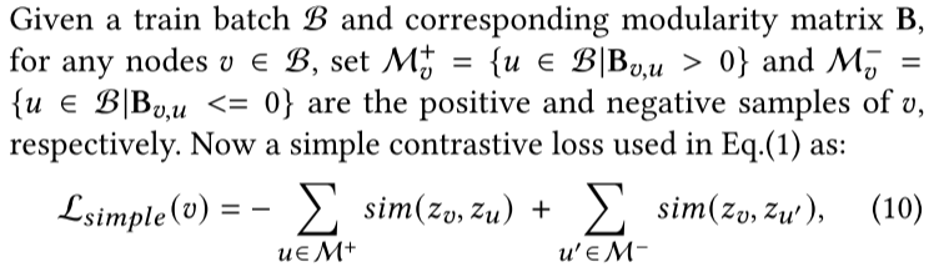
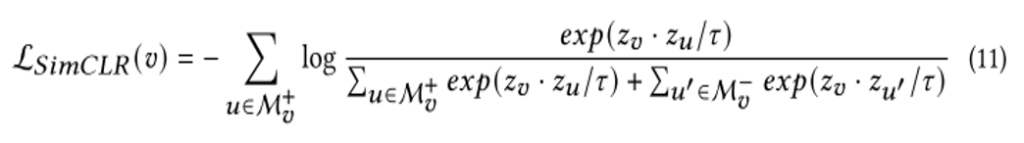
三、实验结果
四、总结与思考
(一)、论文的核心内容:
1.通过神经模块性最大化探索图聚类问题。 建立了神经模块性最大化和图对比学习之间的联系,避免了潜在的语义漂移和可扩展性问题。
2.为了确保更好的可扩展性,Magi 采用两阶段随机游走以小批量方式逼近模块化矩阵,然后采用原则性对比损失来优化模块化最大化的目标(二)、综合对齐思考:
(二)、综合对齐思考:
1.文章中的小批量模块化矩阵在一定程度上可以缓解超大数据集的资源消耗问题,但无法从根本上解决小批量中的结构偏差问题。
2.MAGI方法可以作为对比方法来进行效果比对。