来源:IEEE Transactions on Neural Networks and Learning Systems
作者:YuanHeng Zhu, Dongbin Zhao
单位:中国科学院自动化研究所
时间:2020
一、背景
马尔可夫决策过程(MDP)是描述智能体与环境之间交互过程的常用工具。近年来,基于MDP的强化学习(RL)在解决单智能体最优决策问题方面得到了充分发展。然而,在许多现实场景中,同一环境中存在多个智能体并共同影响系统的演化。
马尔可夫博弈 (MG)被视为 MDP 对博弈场景的扩展。在 MG 中,多个代理做出一系列决策以最大化共同或个人利益。两人零和博弈(TZMG)是其中一种特殊情况,其包括两个利益完全相反的参与者。
TZMG可描述为一个六元组:
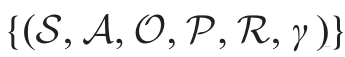
其中,S是游戏状态集,A是动作集,P是状态转移函数,R是奖励函数,γ是折扣因子,此外,相较于传统的马尔可夫五元组,TZMG增加了另外一个玩家的动作集O。在每一步,两名玩家在博弈中同时决定并执行他们的动作,新状态满足分布:
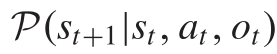
它们共享相同的奖励函数,但一个的目标是最大化未来奖励的总和,而另一个则最小化它。
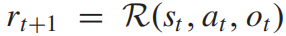
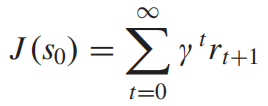
现有的研究对回合制游戏给予了较多关注,并取得了较大进展。在这些游戏中,玩家一个接一个地做出决定,因此玩家总是知道另一方的行动。而与回合制游戏相比,同步游戏需要双方同时做出决定。 玩家不知道对手的即时决策,因此决策策略可能会更加棘手和不可预测。文章即通过研究这种类型的 TZMG,给出了极小极大Q网络算法。
二、贡献
提出了极小极大 Q 网络(M2QN)算法,以无模型的方式在线学习纳什均衡。 特点如下:
- 该算法源于广义策略迭代(GPI),并与DRL技术相结合,以改善学习过程。
2. Q函数与神经网络(NN)相结合,以解决大规模状态空间问题,并用博弈数据训练可学习的权重。
3. 引入经验回放以提高数据效率并加快学习过程。
与self-play算法相比,M2QN的优点是收敛到纳什均衡的理论基础以及对对称和非对称博弈的适用性。
三、方法
- 纳什均衡
在MGs中,没有一个参与者的策略总是最优的,因为其回报取决于其他行为。衡量一个玩家相对于其他玩家表现的两个著名概念是最佳应对和纳什均衡。给定己方策略π,对方策略μ,则纳什均衡对应于一对(π∗,μ∗)这两者都是对彼此最好的回应:
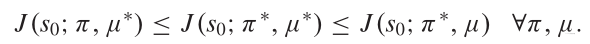
在TZMGs中,总是存在纳什均衡,它等价于极大极小解:
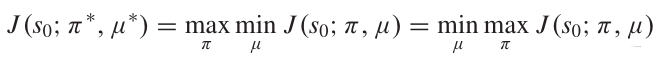
纳什均衡规定了玩家在最差的对手面前可以获得的最大回报,当我们不知道对手或对手是一个可学习的主体并根据我们的策略更新其行为时,纳什均衡是有意义的。
2. 极大极小值方程
状态价值-贝尔曼极大极小方程:
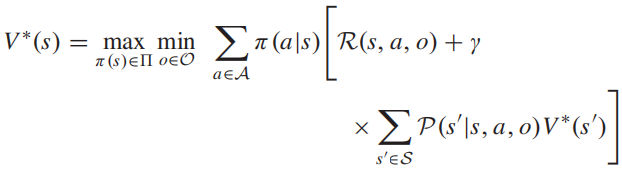
动作价值-贝尔曼极大极小方程:
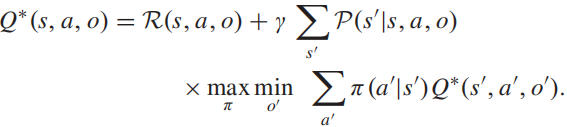
3. 线性规划求解极小极大方程
在Q值确定后,纳什均衡的策略π*由下式给出:
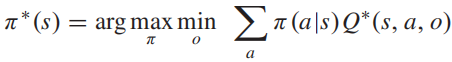
将其转化为线性规划模型,有:
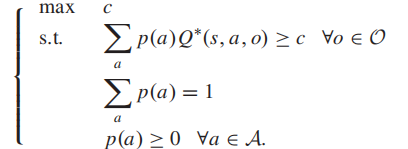
4. 动态规划求解贝尔曼你极小极大方程:
预先定义两个操作符:
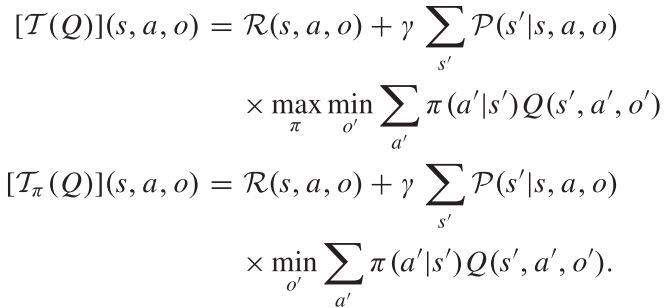
第一个式子T通过极大极小计算下一步的值。第二个Tπ遵循给定的自己的策略π,使对手动作集的下一步值最小化,因此可以将其看作具有二人Q值的最小化Bellman最优方程。两个式子具有相同性质:
(1)单调和γ-收缩算子
(2)具有唯一的固定点
5.价值迭代与策略迭代
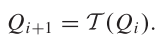
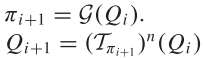
6. 极大极小Q网络学习
收到DQN的启发,作者引入神经网络来近似TZMG中的复杂Q函数

四、实验
文章中共有三种实验场景,这里列举其中一种:
非对称TZMG上基于nn的M2QN:保卫领土
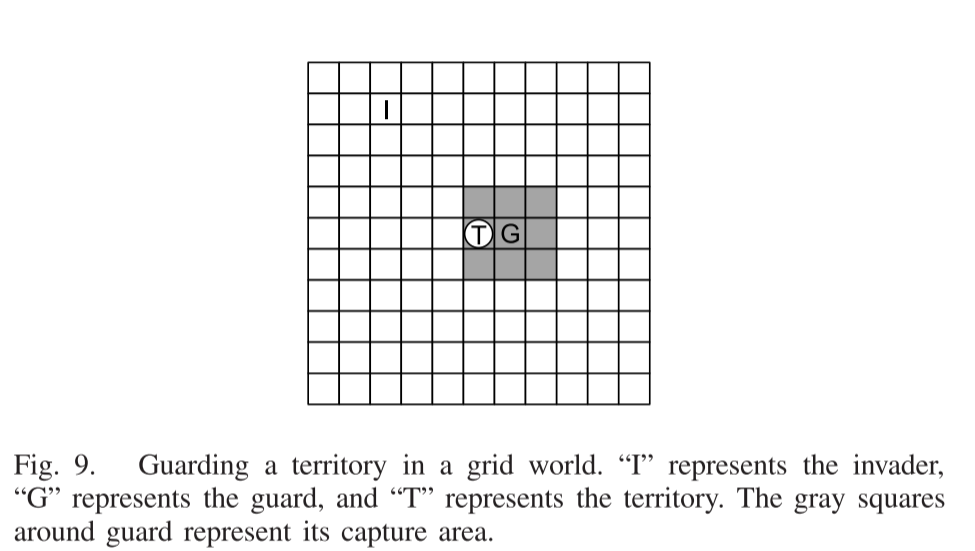
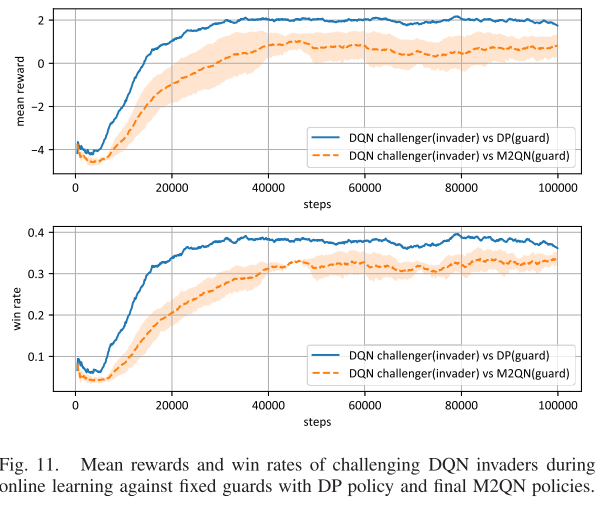
网格中有一个入侵者和一个守卫,在每一步中,他们选择做出一个动作:左、上、右、下和停留。入侵者的目标是一个标记为领土的网格。如果入侵者在被捕获之前到达领土,或者捕获刚好发生在领土上,则入侵成功。警卫的目标是在尽可能远的地方拦截入侵者。以警卫为中心的九个牢房构成了其抓捕区域。当成功入侵或捕获发生时,游戏结束。然后,在下一轮中,警卫和入侵者的位置被随机重置。这场比赛是不对称的,因为双方球员需要完全不同的策略。
守卫的奖励函数:
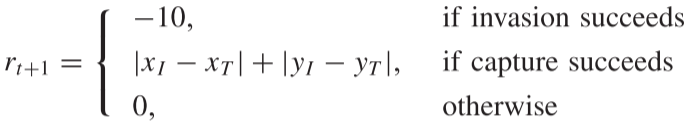
其中第一个条件选择负值作为入侵奖励,第二个条件使用入侵者和领土之间的曼哈顿距离作为捕获奖励,即当捕获时,入侵者距离领土越远奖励越大。
五、结论与启发
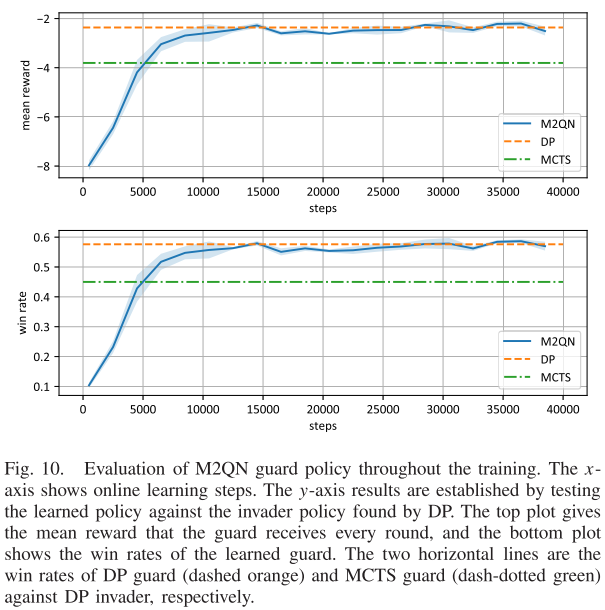
文章中,作者将博弈论与最新的DQN技术相结合,来处理需要双方同时决策的TZMG。所提出的M2QN算法从GPI发展而来,与神经网络相结合,用于大规模问题。它基于无模型的方式以博弈数据学习纳什均衡,适用于对称和非对称博弈。实验示例验证了M2QN适用于各种TZMG问题。
当前算法的一个局限性是它只考虑具有有限动作集的游戏。MDP的一些DRL算法,如DDPG、PPO和TRPO,为大规模动作集或连续动作空间定义了一个策略网络。它们的策略参数根据返回值或评估值沿策略梯度进行调整。然而,当将这些算法扩展到TZMG时,最大的困难是估计准确的策略梯度。在MG中,一个玩家策略的值或回报取决于其他行为,使得策略梯度嘈杂且不一致。
启发:该算法对传统的Minimax Q算法进行了改进,对于非对称性博弈具有适用性,在对抗双方具有不同的动作集时,具有参考意义。