作者: Derong XU, Wei CHEN, Chao ZHANG et al.
来源: Frontiers of Computer Science(CCF-B)
时间: 2024.10
一、背景
1. 信息抽取(IE)是自然语言处理(NLP)中的一个关键领域,它将纯文本转换为结构化知识,如实体、关系和事件,为知识图谱构建、知识推理和问答等下游任务提供基础支持。
2. 传统IE任务面临诸多挑战,如需要从不同来源提取信息、处理复杂且不断变化的领域需求,以及需要为每个特定任务单独训练模型,导致资源消耗大。
3. 大型语言模型(LLMs)如 GPT-4的兴起,显著推动了NLP领域的发展,它们在文本理解和生成方面表现出色,能够进行零样本和少样本学习,为IE任务提供了新的解决方案。
二、核心内容
1. 文章总结了当前基于LLMs的生成式IE方法,其利用LLMs来生成结构化信息,而不是从纯文本中直接抽取结构化信息,对比传统IE具有极大的优势。
2. 文章探索了利用LLMs构建同时处理多个IE任务的两种通用框架,NL-LLMS和Code-LLMS,并分析了两种框架各自的优缺点。
3. 针对低资源场景,文章总结了多种生成式IE的辅助技术,如数据增强、提示设计、零样本学习、约束解码生成、少样本学习和监督式微调等,以更好地适应LLMs在IE任务中的应用,尤其是在训练数据有限的情况下,这些技术能够有效提升模型的性能和泛化能力。
三、技术路线
3.1生成式IE总体框架
当前的生成式IE框架主要就是使用提示工程、微调以及数据增强技术,在任务特性框架或者通用框架下让大模型完成指定的IE任务的子任务,其中包括命名实体抽取NER(Named Entity Recognition)、关系抽取RE( Relation Extraction )和事件抽取EE( Event Extraction )三种主要类型的子任务
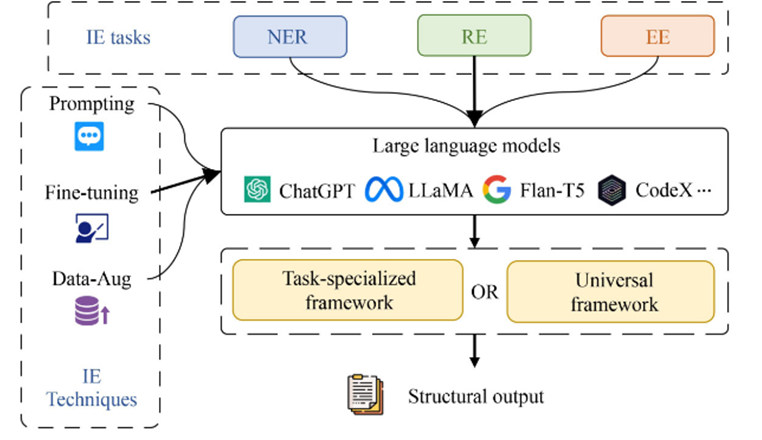
3.2 两种统一的IE生成框架
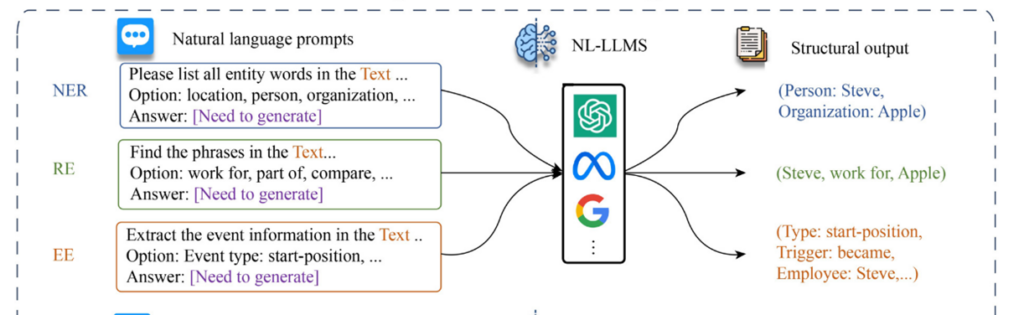
NL-LLMS,基于自然语言的通用IE框架。 NL-LLMs在广泛的文本上进行训练,能够理解和生成人类语言,这使得提示和指令可以更简洁、更容易设计。然而,NL-LLMs可能会产生不自然的输出,因为IE任务的语法和结构与训练数据不同。
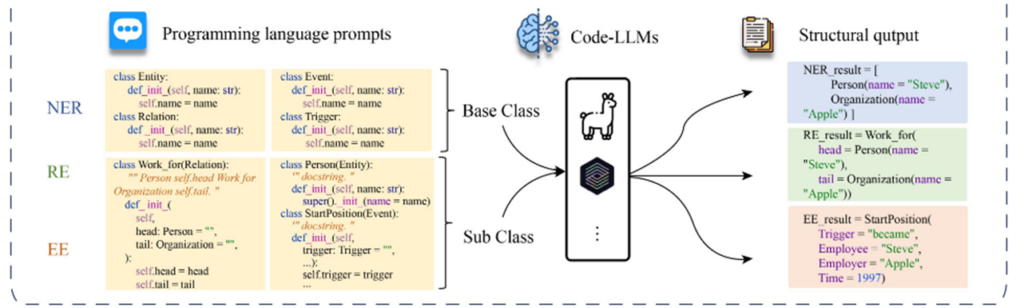
Code-LLMS,基于代码的方法的通用IE框架。代码作为一种形式化语言,具有准确表示不同模式知识的固有能力,这使其更适合于结构化预测。但是,基于代码的方法通常需要大量文本来定义Python类,这反过来又限制了上下文样本的大小。
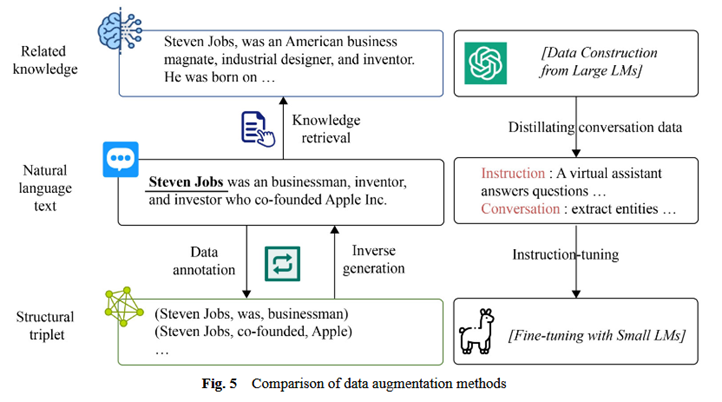
3.3 低资源场景下生成式IE的相关辅助技术
数据增强:利用LLMs生成有意义且多样化的数据来增强训练样本,包括数据标注、知识检索、逆向生成和为微调生成合成数据集等策略。
提示设计:通过使用特定于任务的指令或提示来指导模型行为,如问答(QA)、链式思考(CoT)和自我改进等方法,以提升LLMs在IE任务上的性能。
零样本学习:确保模型能够有效泛化到未训练过的任务和领域,同时使预训练范式与新任务对齐,如通过引入通用框架和创新训练提示来学习和捕捉已知任务间的依赖关系,并将其泛化到未见任务和领域。
约束解码生成:在自回归LLMs中,生成文本时遵循特定的约束或规则,如使用语法约束解码来控制LM的输出,确保其遵循给定结构。少样本学习:在只有少量标记示例的情况下进行学习,面临过拟合和难以捕捉复杂关系等挑战,LLMs通过参数扩展获得出色的泛化能力,如GPT-NER引入自验证策略,GPT-RE增强任务感知表示等。
少样本学习:在只有少量标记示例的情况下进行学习,面临过拟合和难以捕捉复杂关系等挑战,LLMs通过参数扩展获得出色的泛化能力,如GPT-NER引入自验证策略,GPT-RE增强任务感知表示等。
监督式微调:使用所有训练数据对LLMs进行微调,是最常见且有前景的方法,允许模型捕捉数据中的底层结构模式,并对未见样本进行良好泛化。
四、实验
4.1 命名实体识别任务(NER)对比实验
通过对比多种模型在五个主要数据集上的表现,发现少样本和零样本设置下的模型与SFT和DA相比仍有较大性能差距;不同模型在ICL范式下的性能差异较大;SFT后不同模型性能差异较小,但参数差异可能达数百倍;通用模型在不同数据集上的性能变异性较大,尤其是跨领域数据集时;EnTDA在所有数据集上表现出色,证明了DA范式在特定任务中的鲁棒性。

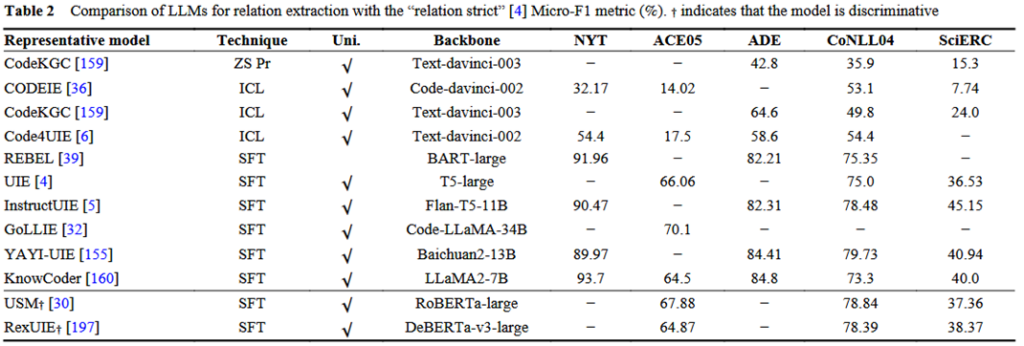
4.2 关系抽取任务(RE)对比实验

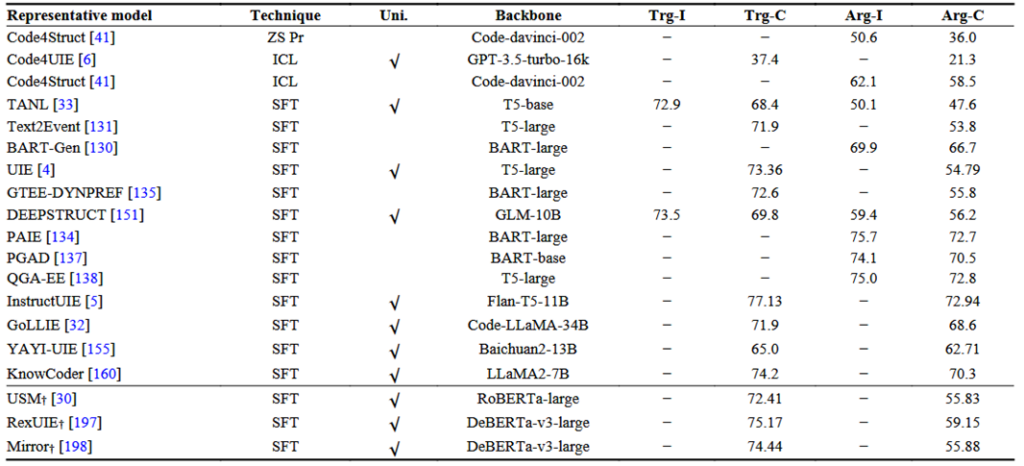
4.3 事件抽取任务(EE)对比实验
大多数方法基于SFT范式,少样本和零样本学习的方法较少;生成式方法在论元分类任务上的性能远超判别式方法,表明生成式LLMs在EE领域具有巨大潜力。
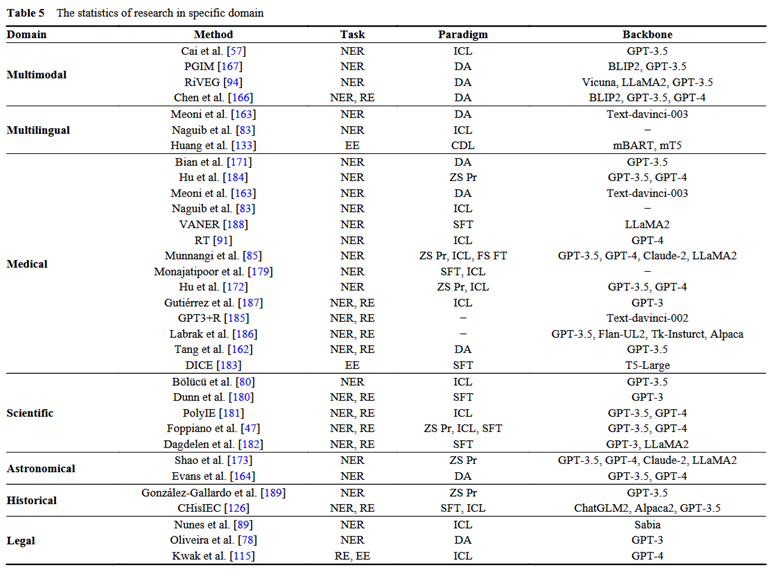
4.4 特定领域应用的实验
LLMs在多模态、多语言、医疗、科学、天文、历史和法律等特定领域展现出了巨大的信息抽取潜力,如Chen等通过结合文本图像对和LLMs的链式思考知识,显著提升了多模态NER和多模态RE的性能;Tang等探索了LLMs在临床文本挖掘中的潜力,并提出了利用合成数据提升性能并解决隐私问题的新训练方法等。
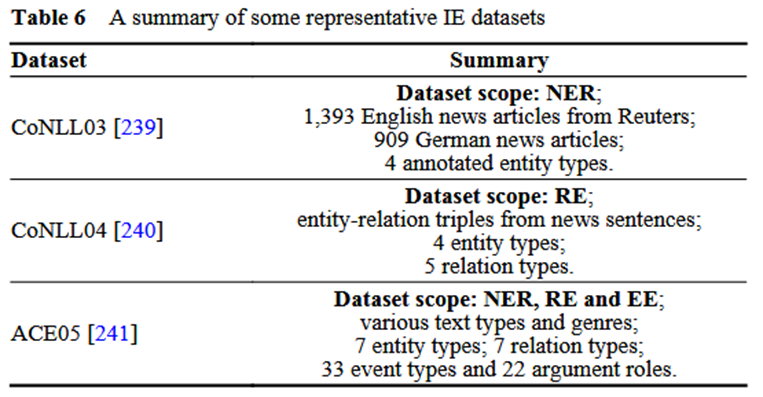
4.5 一些具有代表性的IE数据集
文章还整理了一些具有代表性的IE数据集,可供未来进行实验时参考使用。
五、总结与思考
1.文章全面系统地回顾和探索了LLMs在生成式IE任务中的应用,通过将现有方法分为不同的IE子任务和IE技术两大类进行分类,并对最先进的方法进行实证分析,发现了IE任务中LLMs的新兴趋势。研究识别出了在技术上的一些见解以及未来研究中值得进一步探索的有前景的方向。
2. LLMs在IE领域仍面临一些挑战,如自然语言输出与结构化形式之间的不一致性、LLMs的幻觉问题、上下文依赖性、高计算资源需求以及内部知识更新困难等。
3. 未来的研究方向是进一步发展能够灵活适应不同领域和任务的通用IE框架、探索低资源IE场景下的LLMs应用、设计更有效的IE提示以及在开放IE设置下提升LLMs的性能等。