来源:Arxiv2024-08
作者:Guo Tiezheng,Wang Chen等
单位:东北大学(沈阳)
核心内容
作者把当前RAG系统在多步推理问答这类任务上效果不好归咎于没有考虑到检索到的文本块之间的逻辑联系,作者提出的IIER主要就是试图解决这个问题。
IIER将文档拆解为若干个块(chunks),然后检索这些块来为LLM提供支持材料,这是RAG的一般做法。IIER的创新之处在于,他们把每个块都看作一个图顶点,并且定义了三种关系(相似度距离、语义完整性、共同关键字),这样这些块就组成了一张块交互图(Chunk-Interaction Graph, CIG)。如此,针对某一问题Q搜索一组块作为资料的过程就变成了在块交互图中检索若干条路径。
IIER会首先选取一组和Q最有关的顶点会作为种子结点,分别以它们为初始点在CIG中搜索路径,搜索得到的路径会被作为证据链直接作为LLM回答问题的参考资料。
作者使用IIER在四个问答数据集上进行了实验,和其他搜索方案进行了对比,证明了IIER的优越性。此外,作者还对检索得到的块提供给LLM的顺序、证据链长度、CIG密度对最终效果的影响,证明了创新的价值并且得出了许多有用的启示。
背景
由于缺乏可以评估和编辑大模型内部知识的手段,大模型回答知识密集型问题的效果总是不好;RAG一定程度上克服了这一缺点,但是检索又往往会漏掉许多关键信息,导致效果受限。
作者认为,挖掘块之间的关系,把明显和搜索问题有逻辑关系的块也加入进来可以解决漏掉信息的问题。因此作者将块按照之间的关系组成一张图,通过在图上搜索路径的方式来搜索出一组块,这样就保证了搜索结果在结构或者逻辑上的完整性。
方法论
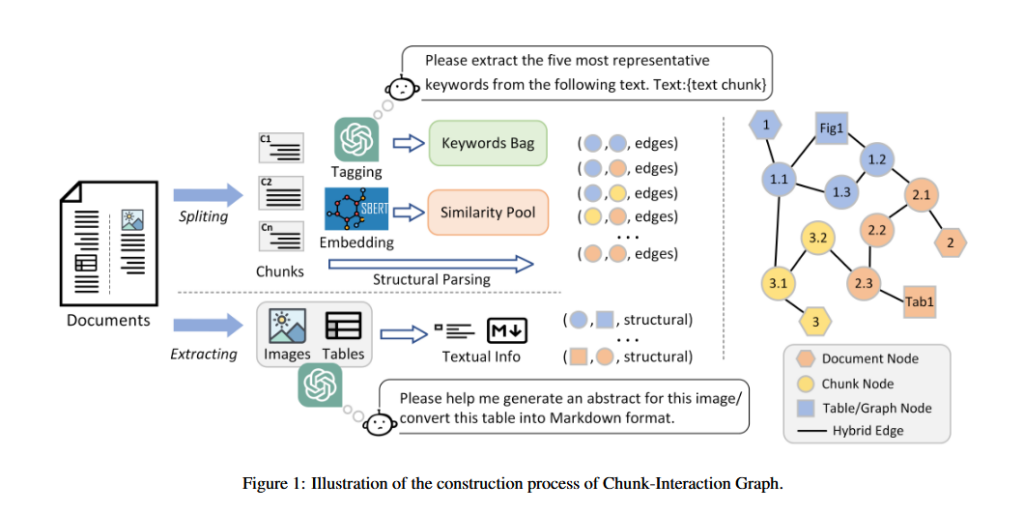
- 构建CIG:
- 检索CIG:
- 根据问题$Q$筛选种子结点:从问题Q中抽取一系列关键词$Q_{k}$并且对Q进行语义编码,然后贪心地选取一组和Q语义相似度最高的顶点,直到这组顶点包含的关键词已经完全覆盖Q的关键词,或者剩下的顶点已经完全不包含Q的关键词;设种子结点集合为$N_{s}=[s_{1},s_{2},\dots,s_{q}]$
- 从种子结点开始,每一次都从上一个被选中结点的邻居中选择最优的加入到链条中。假设当前结点是$s_{i}$,其邻居是$s_{j}$
- 词嵌入:微调一个语言模型$f_{u}$,对$Q$、从种子结点到$s_{i}$CIG路径$Path$(路径上若干个块拼接起来)、以及$s_{j}$进行语义编码,统一编码为长度为$D$的向量
- 考虑各种关系的影响,用一个2层感知机$f_{r}:\mathbb{R}^3\to\mathbb{R}^D$将$s_{i},s_{j}$的三种关系计算的权重映射到同一个空间$E_{edge}=f_{r}([W_{sim},W_{struc},W_{key}])$
- 最终打分为$Score(s_{i},s_{j})=f_{n}(f_{u}(Q),f_{u}(Path),f_{u}(s_{j}),E_{edge})$
- 选择打分最高的邻居结点加入链条,直到达到最大长度限制
- 所有检索出来的块都按照证据链顺序拼接起来,放进提示词中供大模型参考

实验
配置:
- 嵌入模型$f_{u}$:all-mpnet-base-v2,以余弦相似度作为距离
- 打分模型$f_{n}$:微调RoBERTa-base+两个双层感知机
- 证据链长度:5
- 大模型:GPT-3.5-turbo
实验结果:
IIER在大多数指标上都取得了最好的效果,并且提升明显。
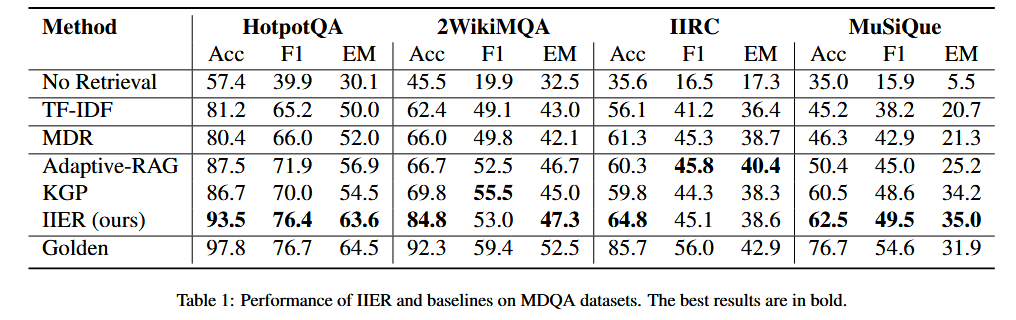

块的顺序对LLM对回答效果也有影响。
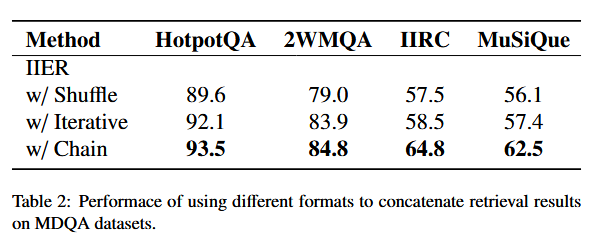
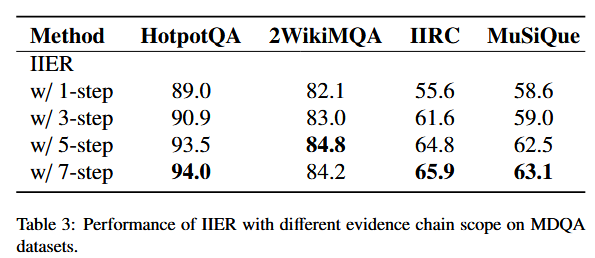
证据链长度对LLM的回答效果有巨大影响。但是这里实验太少,只体现出了「越多越好」这个特征。
结论
- 作者团队认为,检索相关信息不全会严重影响RAG的性能,尤其是在多步推理问题上的表现,因此他们决定关注文本块之间的联系,将联系足够密切却没有被检索到的文本块也加入进来以解决这个问题;
- 在这样的思路下,这篇文章提出了IIER,这是一个通过考察文本块之间的三种关系(相似度距离、语义完整性、共同关键字),将文本块构建为图,通过在图上进行检索出证据链来获取相关证据;
- 作者团队进行了充分的实验,不仅验证了IIER在多步推理问题上的效果,还验证了块的排列顺序以及证据链长度对回答效果的影响。
启发与评价
- 作者的「将文本块(chunks)按照关系组织为图」的思路是一种介于纯粹非结构化文本检索和结构化知识图谱检索之间的方案,可以有效利用非结构化数据易得和结构化数据易检索的特点,具有较好的启发性;
- 作者的实验再次表明了LLM对提示词的敏感性,搜索出的内容如果不按照一定规则精心排序,就会严重影响大模型的回答效果;这个特点某种程度上和人的认知非常相似;
- 作者虽然构造了证据链,但是证据(文本块)之间的关系却不是逻辑关系,而是静态关系;如果认为大模型的阅读方式和人相似,那么考虑到按照逻辑关系组织起来的文章最利于人理解,我们可以认为这篇文章提到的这种材料的排列方法并不是最佳的;
- 这篇文章没有公开代码,并且许多实现细节都是缺失的;其结论可能未必一定可靠。