作者:Akari Asai 等人
发表期刊:Arxiv
单位:华盛顿大学、艾伦人工智能研究所等
时间:2024年11月
一、背景
随着科学文献的爆炸式增长,研究人员在查找、整合和分析最新研究时面临着巨大的挑战。在这一背景下,开发高效的文献检索和综述工具变得尤为重要。现有的大语言模型(LLMs),如 GPT 系列,尽管在自然语言生成方面展现了出色的能力,但在处理科学文献时却面临多种限制。它们常因引用不准确、信息覆盖不足以及无法捕捉学术领域的复杂逻辑而受到批评。此外,现有文献综述工具往往缺乏对动态更新数据的支持,也难以提供可靠的引文,导致研究人员很难直接将这些工具用于学术写作或综述分析。因此,迫切需要一种能够准确引用、深度理解领域知识的工具,以提高科学研究的效率和可靠性。
二、提出的模型框架:OpenScholar
为了解决现有工具的不足,作者提出了 OpenScholar,这是一种基于检索增强型语言模型的系统。OpenScholar 的设计目标是生成高质量、引用准确且内容全面的回答,其核心架构由三个主要模块组成:OpenScholar 数据存储系统 (OSDS)、检索与重排序模块,以及基于语言模型的生成器。OSDS 包含超过 4500 万篇开放获取的科学论文,通过嵌入技术对文献内容进行高效组织,确保检索的全面性和准确性。检索模块利用双编码器对问题和文献进行匹配,而重排序模块则通过交叉编码器筛选最相关的文献。生成器模型在引用这些文献时,结合自反馈机制优化生成的回答质量。通过这种架构,OpenScholar 实现了对科学文献的深度理解和引用支持,为科研人员提供了强大的文献分析和综述工具。
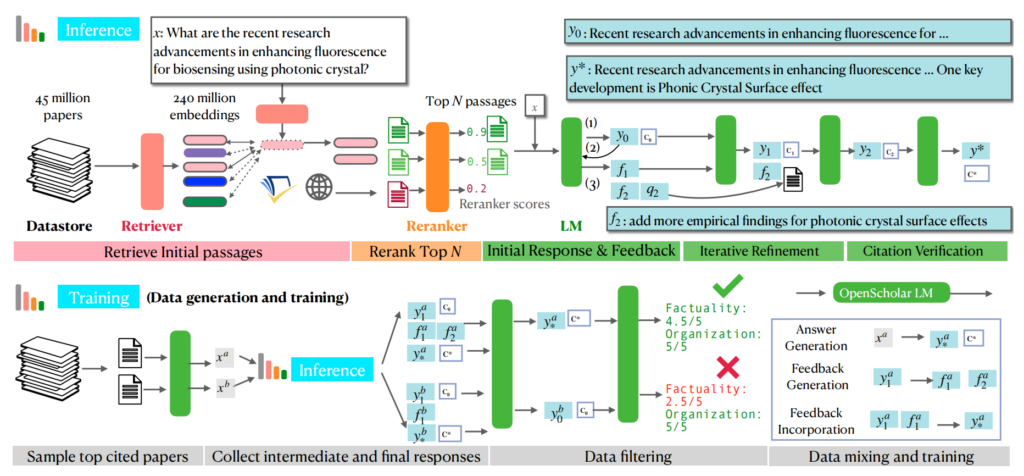

三、评估基准:ScholarQABench
为了科学地评估 OpenScholar 的性能,作者构建了 ScholarQABench,一个跨领域的大规模科学文献检索评估基准。该基准数据集包含 2967 个由领域专家编写的问题和 208 个高质量长文档答案,覆盖了计算机科学、生物医学、物理学和神经科学四大领域。数据集中的问题经过严格筛选,具有很强的多样性和挑战性,涵盖了从简单事实查询到复杂推理的多种类型。评估方法不仅关注引用的准确性,还考虑回答的内容覆盖性和结构的逻辑性。这种多维度的评估方式能够全面反映检索增强型语言模型在处理学术问题时的能力,为未来的研究提供了可靠的基准和参考。

四、实验与成果
在实验中,OpenScholar 在 ScholarQABench 上展现出了优异的性能。相较于现有的 GPT-4o 和其他基线模型,OpenScholar 不仅在引用准确性上达到了与领域专家相当的水平,还在内容覆盖性和回答结构上表现突出。在具体结果上,OpenScholar 提高了 12% 的正确率,并在超过一半的问题上赢得了专家的偏好。此外,OpenScholar 的模型设计和开源性质大幅降低了应用成本,同时增强了系统的可复现性。这种创新的检索增强型语言模型为科学研究提供了全新的工具,并为未来类似系统的开发和优化提供了清晰的方向。
单篇论文任务:在单篇论文任务中,OPENSCHOLAR的OS-8B和OS-70B在最终正确率和引用准确率方面均优于其他模型。例如,OS-70B在PubMedQA和QASA任务上的表现与GPT-4o相当甚至更好。
多篇论文任务:在多篇论文任务中,OPENSCHOLAR-8B、70B和GPT4o(OS-8B、OS-70B和OS-GPT4o)表现出强大的性能。OS-GPT4o在SCHOLAR-CS任务上的正确率比GPT4o提高了12.7个百分点,比标准RAG提高了5.3个百分点。
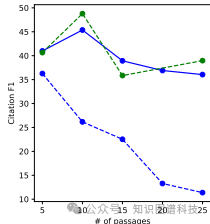
自动评估:在自动评估中,OPENSCHOLAR在引用准确率、内容质量和组织等方面均优于其他模型。例如,OS-8B在SCHOLAR-CS任务上的引用准确率为47.9%,而GPT4o仅为31.1%。
五、总结
OpenScholar 是一种创新的检索增强型语言模型,旨在解决现有文献综述工具在引用准确性、内容深度和动态更新能力上的不足。通过整合大规模开放科学文献库、高效的检索与重排序模块,以及生成器模型的自反馈优化机制,OpenScholar 实现了对科学文献的深度理解和高效引用支持。在 ScholarQABench 基准上的优异表现进一步验证了其在学术领域应用的潜力。作为一个开源系统,OpenScholar 不仅降低了科学文献分析工具的使用门槛,还为未来检索增强型语言模型的研究提供了重要的启发。它为科研人员高效获取和组织学术知识提供了强大支持,并在推动学术研究信息化、智能化方面迈出了关键一步。