作者:Enshen Zhou等人
发表期刊:Arxiv
时间:2024年3月
一、研究背景
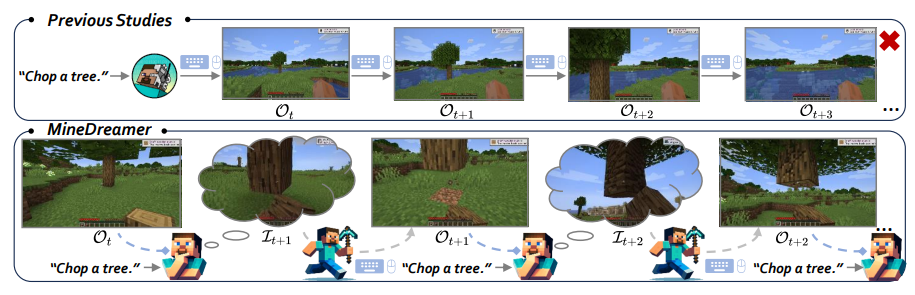
当前具身智能的核心目标之一是开发一种通用的低级控制代理,它可以遵循不同的指令来解决无尽的开放世界具身任务。最近的研究成功完全释放了基础模型的指令跟踪能力,但这些方法很难使代理稳定地遵从文本指令。有两点原因:许多文本指令对于底层控制来说是抽象的,模型难以有效理解,简单的文本指令无法精确演示所需的行为; 许多文本指令都是顺序性的,执行这些指令可能需要考虑当前状态,并将任务分解成多个阶段逐步完成,由单一文本指令驱动的稳定动作生成往往会失败。
二、核心内容
- 作者引入了想象链(CoI)方法,该方法将“自我多轮交互”引入到顺序决策领域,使智能体能够在动作生成中稳定地遵循人类指令。
- 作者提出了Goal Drift Collection方法和 MLLM 增强的扩散融合模型,可以产生符合物理规则和环境理解的想象力,提供与当前状态和指令相关的更精确的视觉提示。
- 作者利用这些方法,在 Minecraft 中创建了一个名为 MineDreamer 的具体代理,在稳定执行单步和多步指令方面,其性能几乎是最佳通才代理基线的两倍。
三、核心方法框架
MineDreamer 包括三个模块,即 Imaginator、Prompt Generator 和 PolicyNet。它的目标是使代理,尤其是顺序决策领域的基础模型,能够稳定地遵循人类指令并采取相应行动。Imaginator 是一种针对 Minecraft 的参数高效微调扩散模型,它利用了多模态大语言模型(MLLM)的视觉推理能力。Prompt Generator 可从当前观察、未来想象和指令中重建潜在的视觉提示。PolicyNet 是现有的视频预训练模型,在 7 万小时的 Minecraft 游戏中进行了训练。
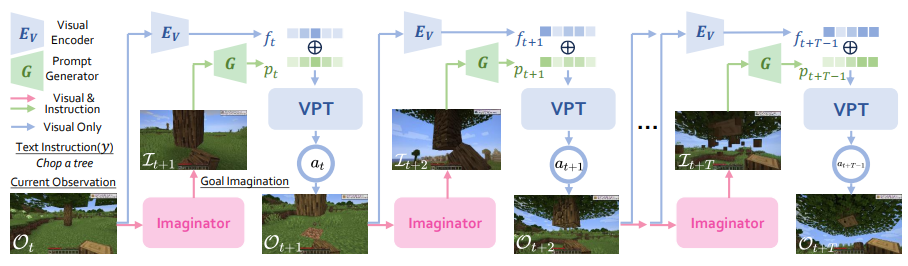
其中Imaginator将其转换为精确的视觉提示,考虑到指令和观察到的图像。Visual Encoder对当前状态场景进行观察,将其与此提示集成在一起,然后将其输入到VPT中。VPT确定了代理的下一个动作,从而生成了新的观察,迭代继续。
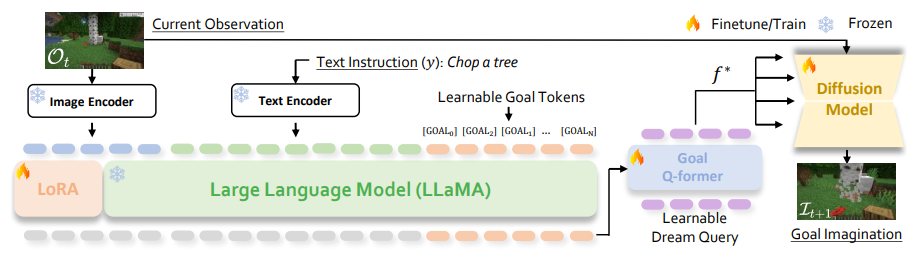
下图是Imaginator 的整体框架。为了理解目标,作者在指令 y 的末尾添加 k 个 [GOAL] 标记,并将其与当前观测值 Ot 一起输入 LLaVA 。然后,LLaVA为 [GOAL] 标记生成隐藏状态,Q-Former 对其进行处理,生成特征 f∗ 。随后,图像编码器 Ev 将其输出与扩散模型中的 f ∗ 结合起来,生成基于指令的未来目标想象力。
四、实验部分
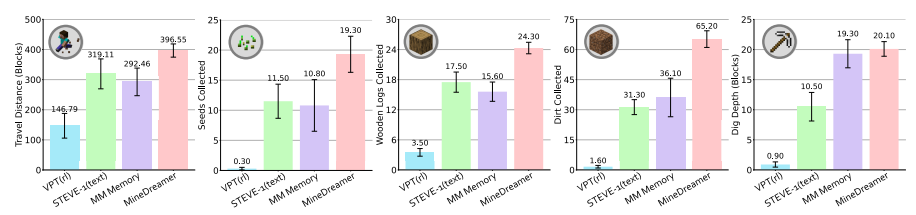
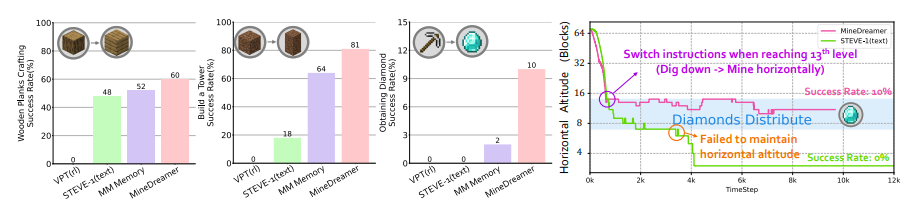
程序评估的性能。 MinedReamer超过了无条件的VPT ,文本条件的Steve-1 ,忽略了当前状态以及使用COI机制的当前状态的多模式内存。
作者利用 STEVE-1 的早期游戏评估套件,其中包括两项评估:(1) 程序评估,这是一项定量评估,用于评估代理稳定执行单步指令的能力。(2) 指令切换评估,这是一项定量评估,旨在评估代理是否能成功地依次执行多步指令,以完成远期任务(如获取钻石)。
指令切换评估性能。(左图)MineDreamer 能迅速适应指令并稳步执行,成功率高于无条件 VPT 、文本条件 STEVE-1 和带 CoI 机制的多模态内存。(右图)MineDreamer 可以挖到 13 米深,并稳定地水平挖矿以获得钻石,平均成功率为 10%,而 STEVE-1 则难以保持稳定的高度
目标想象力生成的定性比较。与在goal drift数据集上经过进一步微调的 InstructPix2Pix 相比,作者的方法在具体场景 ios 中展示了卓越的目标想象能力

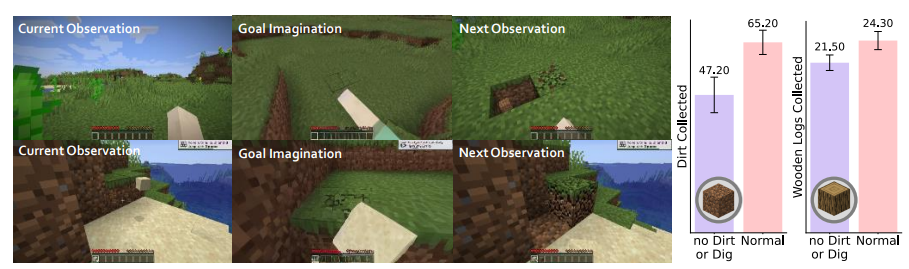
MineDreamer 的通用性。(左图)尽管从目标漂移数据集中排除了涉及 “Dirt ”或 “Dig ”的数据并进行了再训练,Imaginator 仍能生成与指令概念一致的相对高质量的想象。(右图)经过重新训练的 Imaginator 仍可与 CoI 机制一起运行,并能处理未见过的指令,同时在很大程度上保持了之前的性能。
五、总结
在本文中,作者介绍了一种创新范例,用于增强模拟世界控制中代理的指令遵循能力。通过采用想象链机制来设想执行指令的逐步过程,并将想象转化为针对当前状态和指令量身定制的精确视觉提示,可以显着帮助基础模型在动作生成中稳步遵循指示。《我的世界》中的 MineDreamer 展示了其强大的指令跟踪能力。此外,作者还展示了其在具有挑战性的“获取钻石”任务中作为高级规划者的下游控制器的潜力。相信这种新颖的范式将激发未来的研究并推广到其他领域和开放世界环境。