作者:Jan Keim,Sophie Corallo等
单位:KASTEL – Institute of Information Security and Dependability
来源:IEEE
发表日期:2023.3
背景介绍
软件架构文档(Software Architecture Documentation, SAD)在软件开发、维护和演进过程中起着至关重要的作用。它不仅帮助开发人员理解系统的设计决策,还能提高系统的整体质量。然而,随着项目的复杂性增加,文档的维护变得愈发困难,尤其是在不同的文档形式(如自然语言文档和形式化模型)之间容易出现不一致性。这些不一致性可能导致开发过程中的错误和维护中的困难,进而影响系统的成功。
本文提出了一种基于可追溯性链接恢复(Traceability Link Recovery, TLR)的方法,用于检测自然语言软件架构文档(NLSAD)与形式化架构模型(SAM)之间的不一致性。具体来说,本文关注两类不一致性:未提及的模型元素(Unmentioned Model Elements, UMEs)和缺失的模型元素(Missing Model Elements, MMEs)。通过扩展现有的TLR方法(SWATTR),本文提出了一种新的架构文档一致性检测方法(ArDoCo),并在多个开源项目上进行了评估,结果表明该方法在检测不一致性方面表现出色。

核心方法
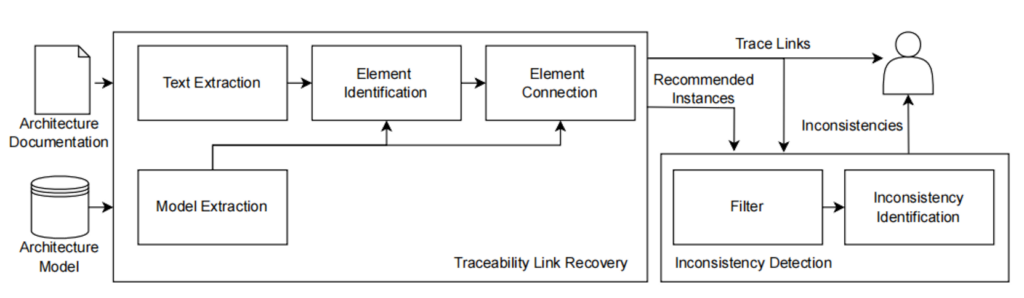
追踪连接恢复
文本提取:对文档进行预处理,提取可能的模型元素(如组件名称、类型等)
模型提取:提取架构模型中的关键元素,转化为统一的标准表示
元素识别:筛选出文档中可能的有效架构元素,生成推荐实例,为元素连接提供候选输入
元素连接:利用字符串相似性算法计算文档提取元素与模型元素之间的相似度,生成追踪链接
不一致性检测
过滤:通过过滤机制对推荐实例进行筛选,排除噪声
阈值过滤:排除置信度低于动态阈值的推荐实例
频次过滤:移除在文档中出现次数低于设定值(如 2 次)的实例
关键词过滤:基于黑名单移除通用词(如“Java”)和项目特定术语(如“MongoDB”)
UMEs 检测:
检查架构模型中的每个元素是否有追踪链接,无链接的元素被标记为未提及(UME)。
MMEs 检测:
从文档提取推荐实例,与模型匹配;无法匹配的实例被标记为缺失(MME)。
实验结果
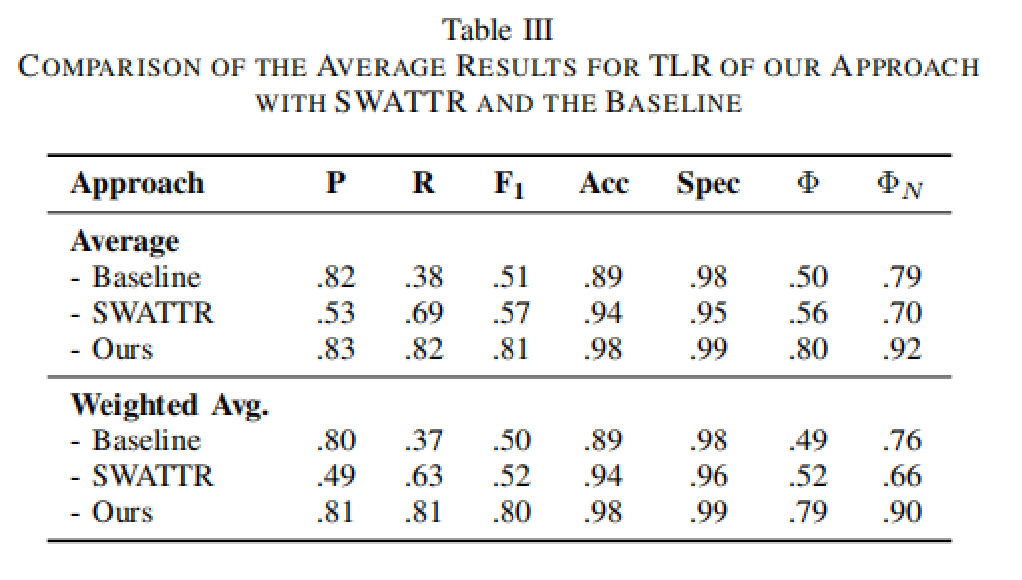
本文方法、SWATTR方法及基线方法在追踪链接恢复(Traceability Link Recovery)中的平均性能对比。可以看出该方法在各指标上表现都超过基线和SWATTR。
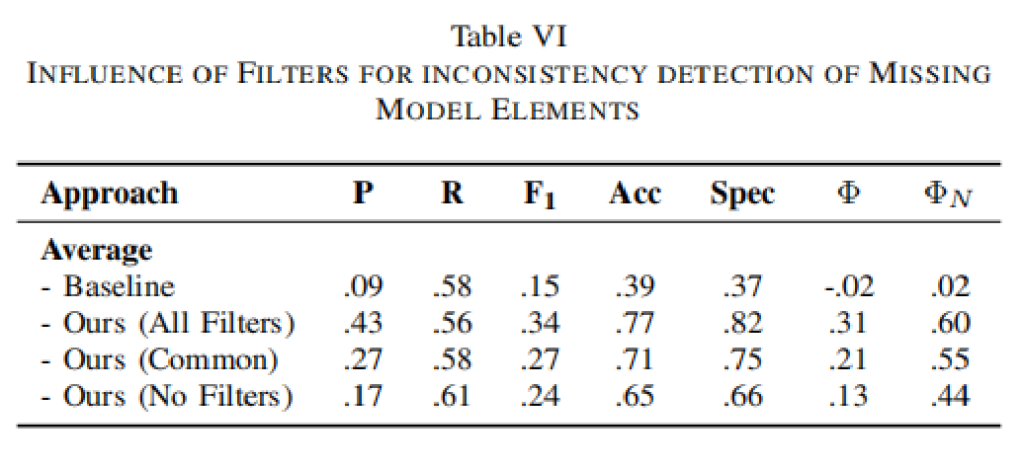
启用全部过滤器时,Precision大幅提升(43%),而Recall略有下降(56%),整体F1-Score达到34%。对比基线方法,使用过滤器后,该方法在Precision、Specificity和ΦN指标上表现出显著改进,表明过滤器对提高检测性能的关键作用。
论文总结
1.提出了一种基于追踪链接恢复(Traceability Link Recovery, TLR)的方法,用于检测架构文档与架构模型之间的不一致性。
2.通过改进SWATTR方法,实现了从文档到模型的追踪链接恢复,并提出了一系列过滤器和检测方法,用于识别未提及模型元素(UMEs)和缺失模型元素(MMEs)。
3.实验表明,本文方法在追踪链接恢复和不一致性检测中的性能显著优于基线方法和SWATTR方法,尤其在F1-Score、Precision等指标上表现突出。
启发思考
可以直接利用大模型的语言理解和上下文推理能力来识别软件架构文档中的不一致性。具体而言,对于未提及的模型元素(UMEs),通过输入架构模型元素列表和文档内容,利用大模型判断哪些元素未被文档提及;对于缺失的模型元素(MMEs),则通过从文档中提取潜在的架构元素,并与模型中的元素进行比对,识别出缺失的部分。这一方法的优势在于,它简化了传统追踪链接生成的复杂流程,同时依托大模型的强大语义理解能力,能够更灵活地适应不同格式和领域的文档。