作者:Ashwin Kumar Gururajan, Enrique Lopez-Cuena, Jordi Bayarri-Planas等.
单位:Barcelona Supercomputing Center (BSC),Universitat Politècnica de Catalunya – Barcelona Tech (UPC).
来源:arXiv
时间:2024.5
一、论文概述
•研究背景:随着大型语言模型在医疗保健和医学领域的功能不断进步,对能够保护公共利益的有竞争力的开源模型的需求也越来越大。随着竞争激烈的开源基础模型的可用性不断增加,持续预训练的作用越来越不确定。
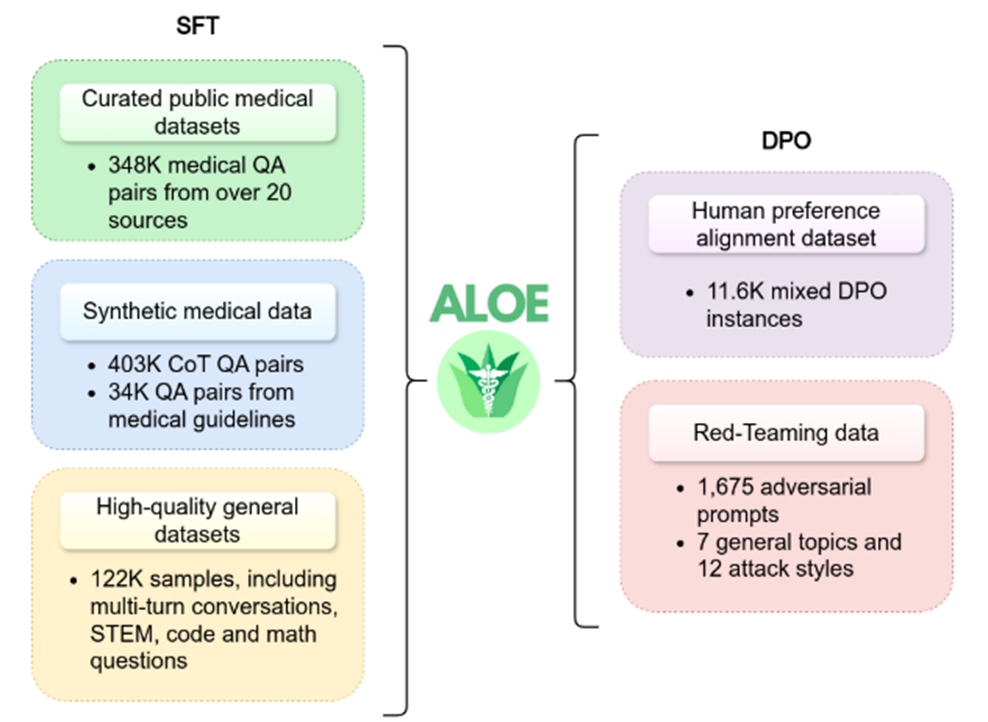
•研究目的:因此该论文提出的 Aloe 模型旨在通过指令微调、模型合并、对齐、红队测试和先进的推理方案等方法,提升现有开源模型的性能,以满足医疗保健领域对高质量、伦理性和安全性的需求。
•研究方法:Aloe 模型在当前最好的基础模型(Mistral、LLaMA 3)上进行训练,使用新的自定义数据集,该数据集集成了通过合成思维链(CoT) 改进的公共数据源。Aloe 模型经历了一个调整阶段,使用直接偏好优化(DPO),模型评估包括各种偏差和毒性数据集、红队工作以及风险评估。最后,为了探索当前模型在推理中的局限性,该文研究了几种先进的提示工程策略,以提高基准的性能。
二、主要内容
1.训练步骤:
•持续预训练:在大量特定于领域的数据源上对基础模型进行自回归训练。
•特定领域的辅助适应:监督微调(SFT)或指令微调。
•模型合并(类似于集成方法):利用不同模型实例化的性能。
•对齐阶段:在这个阶段,模型根据人类偏好进行调整,以减少它们对用户和整个社会构成的风险(例如 DPO)。
•提示策略,通过先进的上下文学习技术提高模型在推理中的性能。
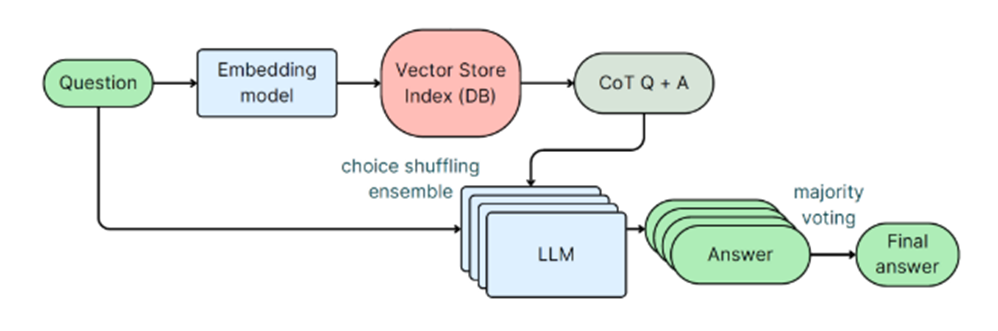
2.CoT:
为每个数据集创建自定义提示,以及手工制作的少样本。对于多项选择答案,要求模型重新表述和解释问题,然后解释与问题相关的每个选项,然后总结此解释以得出最终解决方案。在此合成数据生成过程中,还会为模型提供解决方案和参考答案。此 CoT 通过将问题分解为较小的步骤来引导模型做出更好的响应。

3.嵌入模型
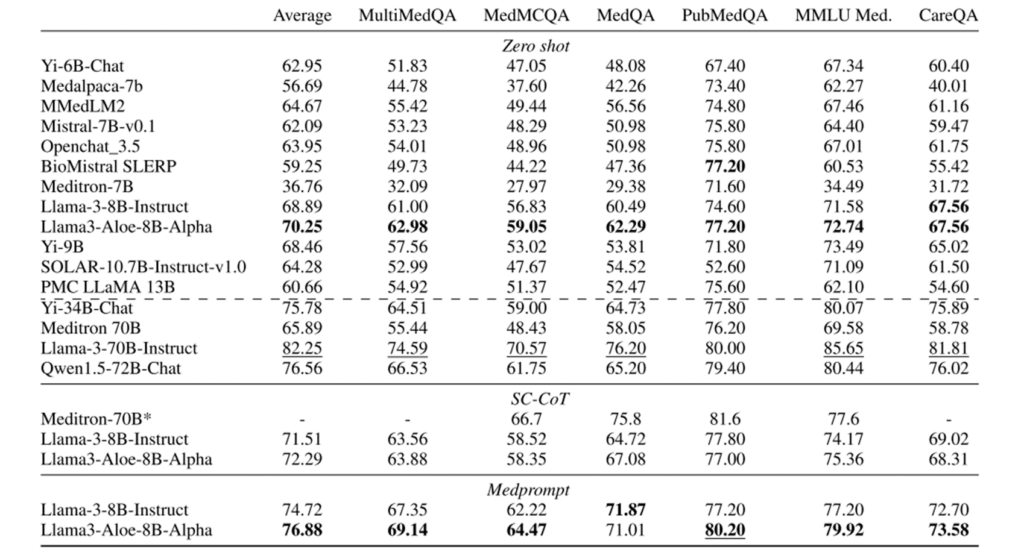
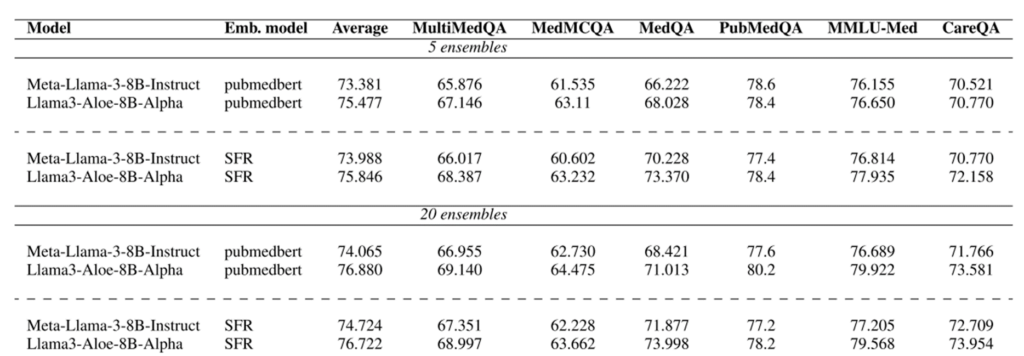
三、实验评估
四、论文总结
•推出 Aloe 系列开源医疗 LLM:该系列模型在 7B 参数规模范围内具有竞争力,通过微调、模型融合、对齐和高级推理等方法,在多个医疗基准测试中达到同等规模模型的先进水平。
•探索多种技术组合: 论文深入研究了指令调优、模型融合、偏好对齐和高级提示等技术对开源医疗 LLM 性能的影响,并找到有效结合这些技术的方法。
•该论文不仅关注模型性能,还非常重视模型的伦理和安全性,通过红队测试、偏见和毒性评估等方法,确保模型的可靠性和安全性。