作者单位:浙江大学、快手、清华大学
作者:白建宏, 夏梦涵
一、论文主要工作
作者通过引入即插即用模块来利用预先训练的文本到视频模型的生成功能。具体来说,给定所需相机的外部参数,通过将一个相机设置为全局坐标系进行标准化,作者首先使用相机编码器将这些参数编码到相机嵌入空间中。然后,在多视图同步模块中执行视图间特征注意力计算,该模块被集成到预训练的 Diffusion Transformer的每个 Transformer 模块中。 此外,作者还收集了一个混合训练数据集,包括多视图图像、一般单视图视频和虚幻引擎渲染的多视图视频中。虽然手动准备的 UE 数据存在特定于域的问题和数量有限,但公开可用的通用视频增强了对开放域场景的泛化,并且多视图图像促进了视点之间的几何和视觉一致性。
二、论文贡献
1.SynCamMaster 开创了多摄像机真实世界视频生成技术。
2.该文章设计了一种有效的方法,以实现跨任意视点的视图同步视频生成,并支持开放域文本提示。
3.该文章提出了一种混合数据构建和训练范式,以克服多摄像头视频的稀缺性并实现稳健泛化。
4.其将方法扩展到新颖的视图视频合成,以从新颖的视角重新渲染输入视频。广泛的实验表明,所提出的 SynCamMaster 的性能大大优于基线。
三、方法
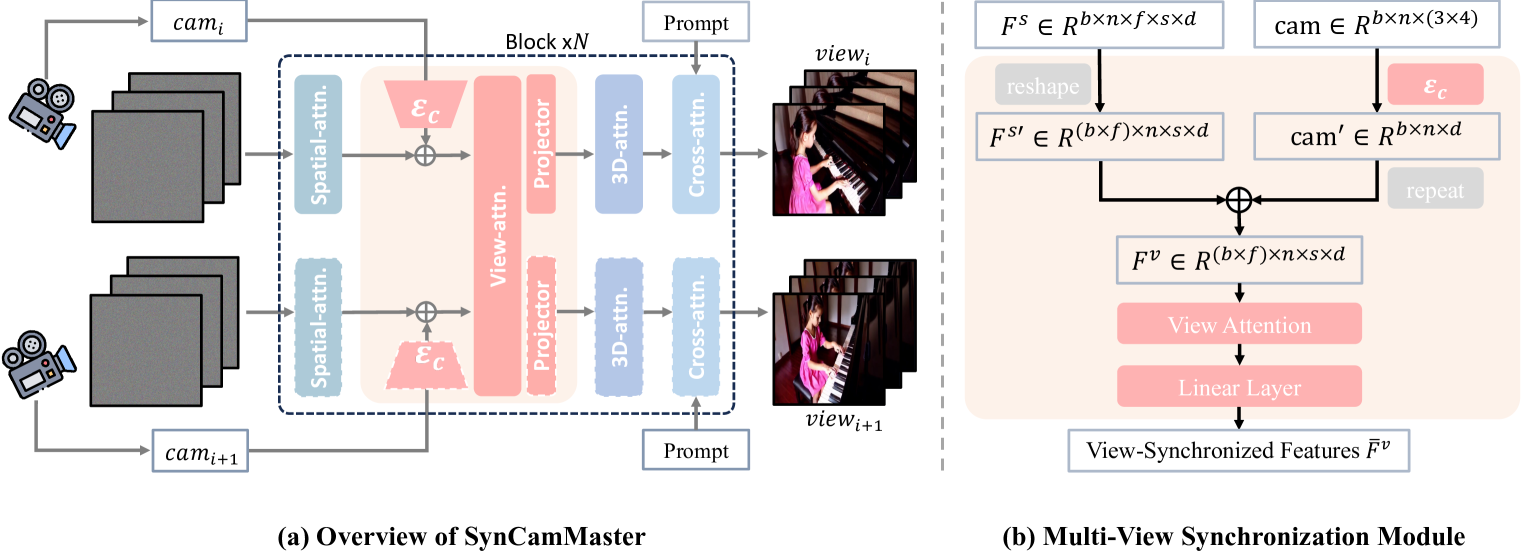
1.文本到视频基本模型
作者的研究是在内部预先训练的文本到视频基础模型上进行的。它是一个潜在视频扩散模型,由一个 3D 变分自动编码器 (VAE) 组成和基于 Transformer 的扩散模型 (DiT).通常,每个 Transformer 块都实例化为空间注意力、3D时空注意力和交叉注意力模块的序列。生成模型采用 Rectified Flow 框架用于噪声调度和降噪过程。正向过程定义为数据分布和标准正态分布之间的直线路径,即zt=(1−t)z0+tε,
2.多视图同步模块
为了实现多视角视频合成,作者在 T2V 生成模型之上训练多视角同步 (MVS) 模块,并将基础模型冻结。但由于后续跨视点是按帧执行的,因此作者为了模型的便捷省略了帧索引t。 MVS 模块采用空间特征F和相机相关参数cam作为n个视频的输入,并将其作为输出视图一致性功能添加到基本T2V模型中的后续层。
3.训练策略
1)渐进式培训。
为了有效地学习不同视点之间的几何对应关系,作者发现从提供角度差异相对较小的模型视图开始至关重要,然后在训练过程中逐渐增加差异。当输入具有较大相对角度的视点时,简单地从同一场景中的不同相机执行随机采样将导致视点跟随功能的性能显著下降
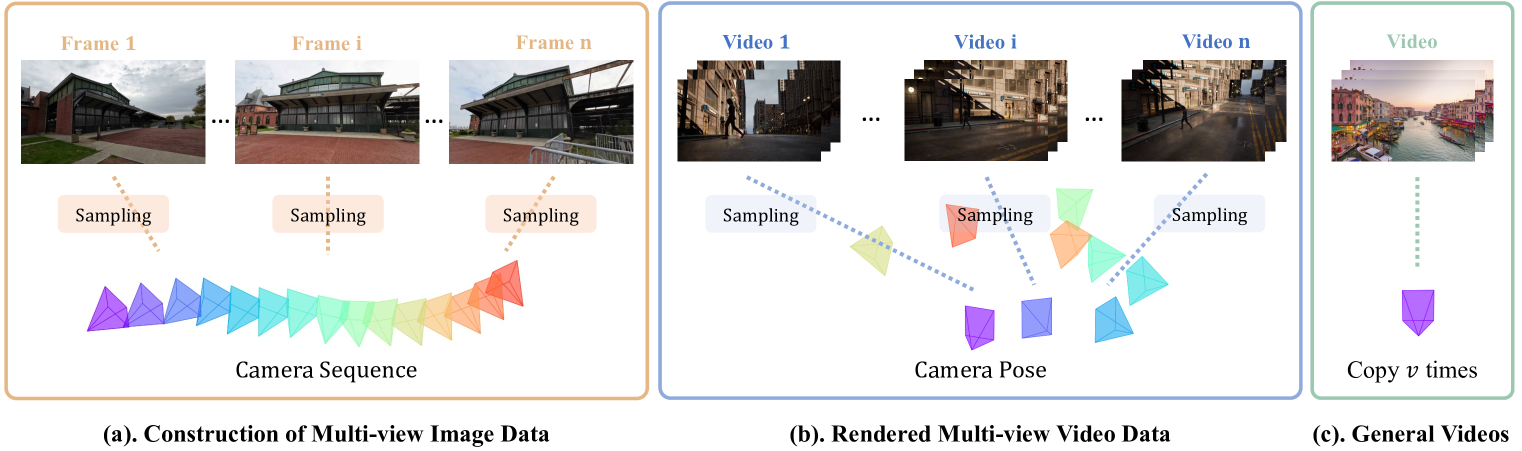
2)使用多视图图像数据进行联合训练。
为了缓解多机位视频数据不足的问题,作者按照单机位视频数据采样来构建多视角图像数据。我们利用 DL3DV-10K作为辅助图像数据,其中包括∼在室内和室外场景中均采用广角摄像机移动的 10K 视频。研究结果表明,使用多视图图像数据的联合训练显着增强了 SynCamMaster 的泛化能力。
3)使用单视图视频数据进行联合训练。
为了提高合成视频的视觉质量,我们建议将高质量的视频数据(没有摄像头信息)作为正则化。给定一个单视图视频,我们通过复制它来将其扩充为多视图视频v时间,并在视图中设置相同的照相机参数。换句话说,单观视频被视为具有v训练期间的重叠视图。
四、实验
1.实验设置
我们主要从交叉视图同步和视觉质量方面对所提出的方法进行评估。在交叉视图同步方面,我们采用了最先进的图像匹配方法 GIM,1) 置信度大于阈值的匹配像素数,表示为 Mat. Pix.,以及 2) 由 GIM 估计的每帧的旋转矩阵和平移向量之间的平均误差与其真实值,分别表示为 RotErr 和 TransErr。
2.与最先进方法的比较

3.消融实验

4.渐进式训练的消融实验
当旨在生成具有较大视点差异的视频时,视图同步合成尤其具有挑战性,因为视图之间的匹配特征较少。为了解决这个问题,作者提出了一种渐进式训练策略,在训练过程中逐渐增加不同视点之间的相对角度。作者将没有或没有建议的渐进式训练策略的训练的综合结果可视化。据观察,虽然简单地使用具有任意相对角度的样本进行训练也可以生成视图一致的视频,但在相对角度较大的相机上进行调节时,它们将无法实现姿势跟踪能力。
五、总结
1.作者提出了 SynCamMaster ,这一方法可以从任意视点生成同步的真实世界视频。
2.方法利用预先训练的文本到视频生成模型并设计了一个多视图同步模块,以保持不同视点之间的外观和几何一致性。
3.该方法还扩展到 novel view video synthesis 以重新渲染输入视频。