作者:Levon Khachatryan, Andranik Movsisyan, Vahram Tadevosyan
单位:Picsart AI Research
来源:ICCV
时间:2023
一、研究背景及意义
最近的text-to-video生成方法依赖于计算量大的训练,并且需要大规模的视频数据集。
本文引入了一个零样text-to-image转换生成,并通过利用现有的文本生成图像方法(例如:stable diffusion)的能力,提出了一种低成本的方法(无需任何训练或优化),使其适用于视频领域。
此方法不仅限于文本到视频的合成,而且,还在条件化、定制化视频以及指令引导的视频编辑方面都有较好的表现。
最终实验表明尽管此方法没有在额外的视频数据上进行训练,但方法的性能与最近的方法相当,有时甚至更好。
二、研究思路及方法
本文贡献
①提出了一个新问题:zero-shot text-to-video,旨在让文本引导的视频生成和编辑更易于实现。我们只使用了一个预训练的文本到图像的扩散模型,而没有任何进一步的微调或优化。
②两种新颖的post – hoc技术通过编码潜在代码中的运动动态来实现时间一致性生成,并使用新的跨帧注意力重新编写每一帧的自注意力。
③广泛的应用表明了我们方法的有效性,包括有条件和专门的视频生成,以及Video Instruct – Pix2Pix,即通过文本指令进行视频编辑。
方法
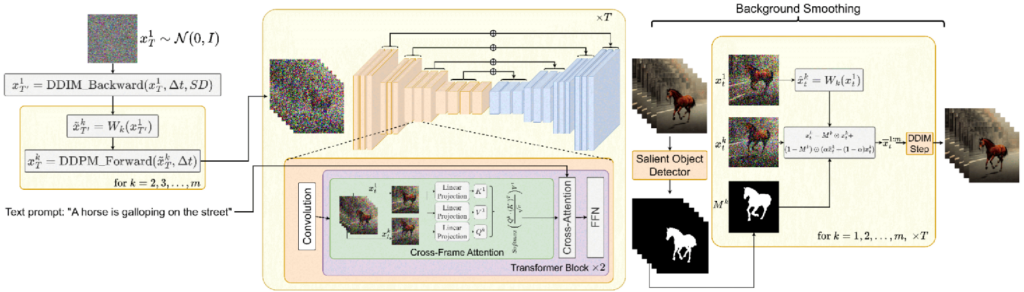
上图为方法的架构图,在此文章中,他们利用稳定扩散( SD )的文本生成图像功效来逼近零样本text-image的转换任务。由于本文需要生成视频而不是图像,SD应该对潜在的编码序列进行操作。朴素方法是从标准高斯分布中独立采样m个隐码,并应用DDIM采样得到对应的张量xk0 ( k = 1,..,m ),然后解码得到生成的视频序列{ D (xk0 ) } mk = 1∈Rm × H × W × 3。然而,这导致完全随机生成的图像仅共享由tao描述的语义,而没有对象外观和运动一致性(见附录图14第一行)。
为了解决这个问题,本文提出( i )在潜在编码x1T,..,xmT之间引入运动动态来保持全局场景时间一致,( ii )使用跨帧注意力机制来保持前景物体的外观和身份。我们方法的每一个组成部分都在下面进行了详细的描述。本文方法概述如图2所示。
从随机采样的隐形码x_T^1开始,我们使用预训练的稳定扩散模型( Stable Diffusion,SD )应用∆t DDIM后向步骤来获得x_T^’^1。一个指定的运动场导致了一个扭曲函数W_k中的每一帧k,使得x_T^’^1变为x_T^’^k。通过运动动力学增强潜在编码,我们确定了全局场景和相机运动,并实现了背景和全局场景的时间一致性。对于k = 1,..,m,随后的DDPM前向应用传递隐码xk T。通过使用(概率) DDPM方法,相对于物体的运动获得了更大的自由度。最后,利用提出的跨帧注意力机制,将潜在的编码传递给我们改进的SD模型,该模型利用第1帧的键和值生成第k = 1,..,m帧的图像。通过使用跨帧注意力,前景物体的外观和身份在整个序列中得到保留。可选地,我们应用背景平滑。为此,我们采用显著性目标检测,为每一帧k获取一个表示前景像素的掩膜M k。最后,针对背景(使用掩模M k),采用将帧1的隐码x1t翘曲到帧k与隐码xtk之间的凸组合,进一步提高背景的时间一致性。
Motion Dynamics in Latent Codes

本文没有对隐码x1:m T进行独立于标准高斯分布的随机采样,而是通过执行以下步骤:
①随机采样第1帧的潜码:x1T⋅N ( 0 , I)。
②通过使用SD模型在隐形码x1上执行t g 0 DDIM向后的步骤,并得到相应的隐形码x1 T′,其中T′= T-DIM-t。
③定义全局场景和相机运动的方向ö = ( φx , φ y)∈R2。默认φ可以是主对角线方向φ x = φy = 1。
④对于我们想要生成的每一帧k = 1,2,..,m,计算全局平移向量ö k = 1⁄4 · ( k-1 ) ö,其中1⁄4是控制全局运动量的超参数。
⑤将构造的运动(平移)流ö 1:m作用于x1T′,得到的序列用x ‘ 1:mT′表示:公式 ,其中Wk( x1T′)是向量φ k对转换的变形操作。
⑥对每个潜码x ‘ 2:m T ‘执行Δ t DDPM前向步骤,得到对应的潜码x2:m T。
然后我们将序列x1:m T作为后向(视频)扩散过程的起点。
然而,初始的潜在代码不足以描述特定的颜色、身份或形状,因此仍然存在导致时间上的不一致性,尤其是对于前景对象。
Reprogramming Cross-Frame Attention
为了解决上述问题,本文使用跨帧注意力机制在整个生成的视频中保留前景对象的外观、形状和身份信息。将其每个自注意力层替换为一个跨帧注意力,每一帧的注意力都在第一帧上。即在原始的SD UNet架构ϵ_θ^t(x_t,τ)中,每个自注意力层取一个特征映射x∈R^ℎ×w×c,线性地将其投影为查询、键、值特征Q,K,V∈R^ℎ×w×c,并通过如下公式(为了简单起见,这里只描述一个注意头) 计算层输出:

在本文中,每个注意力层接收m个输入:x^1:m=[x^1,…,x^m]。因此,线性投影层分别产生m个查询、键和值Q^1:m,K^1:m,V^1:m。因此,我们将每个自注意力层替换为第一帧上每一帧的跨帧注意力如下:
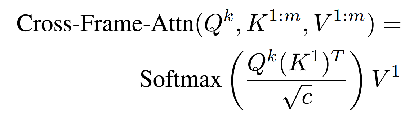
三、结构
Text-vedio

Conditional and Specialized Text-to-Video

四、总结与思考
这项工作的主要限制是无法生成具有动作序列的更长视频。未来的研究可以通过自回归场景动作生成等技术来丰富该方法,同时保持免训练。总的来说,此方法专注于生成视频关键帧,如在Imagen Video和Make -A -Video的第一阶段,因此可以被认为是通过整合时间上采样来生成更长和更平滑视频的良好基础。
此文展现出一个高效的、低成本的方法对于我们在设备和数据集上有相关限制的比较友好,能够在后面的研究中加入相关思想。