作者: Ruoling Peng, Kang Liu, Po Yang, Zhipeng Yuan, Shunbao Li
来源: University of Sheffield Sheffield, Uk
时间: 2023.08
一、背景
大多数农民无法在田间准确识别害虫,且缺乏可用于快速查询的结构化数据源。随着信息时代数据量的激增,信息提取(IE)变得日益重要,尤其是在农业领域,大量信息被埋没在新闻、论文和政府及组织网站中。传统的信息提取方法需要领域特定的训练或手工制定的模式,这对于大量异构文档来说是一个挑战。同时,普通的农业人员可能不熟悉信息提取技术,也没有时间或能力从繁杂的专业书籍或者论文中查阅需要的知识。
二、核心创新
文章的核心是提出了一个名为FINDER的系统,该系统基于通用的大型预训练语言模型(LLM)和基于嵌入的检索(EBR)方法,实现从非结构化文档中零样本(zero-shot)信息提取。该系统能够自动提取实体、属性和相应的描述性术语,并将它们绑定,生成易于使用的结构化数据,无需用户了解自然语言处理(NLP)。
三、技术路线
3.1 FINDER系统的框架结构
EBR filter:EBR(基于嵌入的检索)是一种文本检索技术,它通过将文档矢量化并存储在矢量数据库中来克服大型语言模型(LLM)的输入限制。这种方法将文档转换为向量,使得相似文档在向量空间中的距离更近,而不同文档的距离更远。检索时,通过计算文档向量与搜索内容向量之间的距离来确定文档的相关性。
第一阶段:识别描述性词汇。目标是利用LLM识别文本中用于描述实体的所有词汇。通过EBR过滤器返回的文本作为输入,对每个文本片段执行单轮问答。将匹配的元素作为列表返回。
第二阶段:将描述性词汇转换为属性。任务是将第一阶段收集的描述性词汇转换为属性。这一阶段通过将描述性词汇作为上下文生成提示,并询问LLM这些词汇代表哪些类型的属性。可以聚合所有识别出的属性,并使用LLM过滤它们,保留那些意义相似的属性中出现频率最高的属性。
第三阶段:实体提取。利用LLM从文本中提取主体,对应 NLP 中的命名实体识别(NER)技术。在处理农业相关信息时,FINDER系统只关注有描述的实体。例如,在处理关于“成虫”和“幼虫”的描述时,LLM将识别这些为主语,而忽略如触角、腿、头部等非主体部分。
第四阶段:属性–实体匹配。再次利用EBR过滤器,提取出包含正在研究的实体以及我们希望识别的属性的所有句子,交给大模型LLM用于匹配实体和属性,并以JSON格式返回文档。这一阶段的输出结果是结构化数据,例如将颜色、大小、行为等属性与相应的实体(如成虫或幼虫)相匹配。
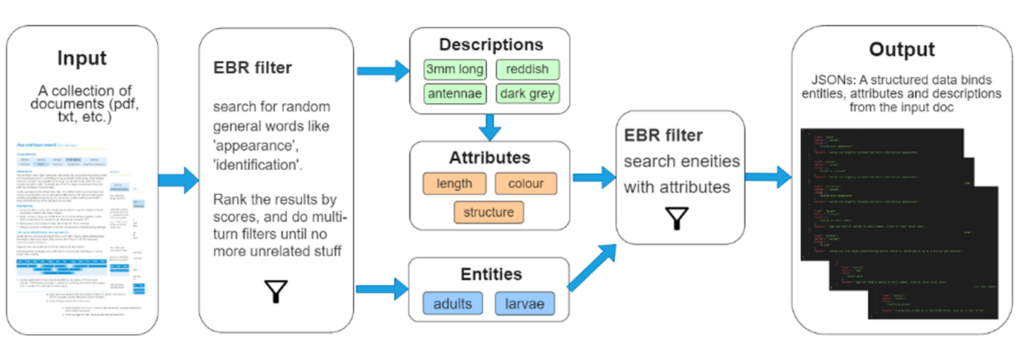
在这个FINDER系统中,IE任务被分解为一个4阶段、多轮问答过程,中间穿插EBR以提取相关文本,避免了token限制并降低了成本。在第一阶段,系统搜索用于描述文本中实体的单词。然后,在第二阶段,它识别出所有已描述的实体。在第三阶段,它提取描述性单词表示的属性,最后在第四阶段,它在文本中搜索描述这些属性的单词,并将其绑定到实体,形成结构化数据。
四、实验
4.1 实验设计
系统的工作流由六个部分组成,其中两个部分是EBR滤波算法,最后一步是结果输出。由于EBR滤波器的特性,它只返回符合要求的结果,对评估没有意义,因此不考虑。
实验仅考虑使用LLM完成的属性提取(阶段2)、实体提取(阶段3)和最终属性实体匹配(阶段4)这三个部分的性能。
在每次测试中人类评估人员将评估LLM的输出为“真”、“假”。因此,可以计算出准确率、召回率和F1分数。在第2阶段和第4阶段,还引入了另一个标准“可接受”。“可接受的”一词意味着,尽管LLM输出和手动处理的文本之间可能存在差异,但答案仍然可以被视为正确,并将被添加到真阳性中。在现实问题中,这可能会出现2个以上看似正确的答案,有多个可接受的答案。
最终结果由人工检查,并与人工注释的答案进行比较。
4.2 实验结果
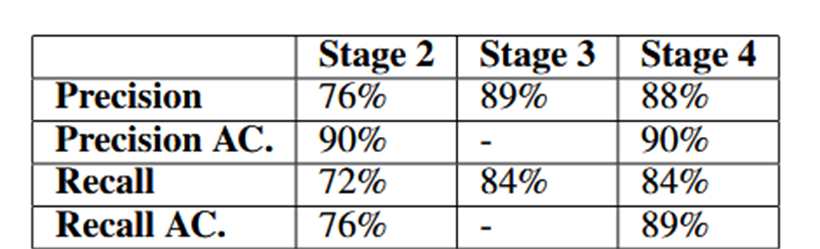
框架在gpt3.5-urbo 在零样本条件下的性能。
该模型在第三阶段(即实体提取)表现出很高的准确性,但在其他两个方面表现不佳。然而,在认为一些答案“可接受”后,准确率显著提高,最大提高了13%。这是一个有趣的现象。事实上,很多事情都可以用多种方式来解释,没有必要严格遵守一个正确答案。然而,“可接受”的标准因人而异。因此该实验不能完全证明LLM在输出可接受的答案时具有很高的准确性。
4.3 局限
虽然这个框架已经具备了一些信息提取的能力,但它是否可以实际应用仍然是一个未知数,还有很大的改进空间。并且,在测试中发现LLM的输出并不总是完全满足要求,如下所示:
(1)在将描述性文本转换为属性时,输出属性通常看起来有点偏离。例如,“黑点”可以被识别为“颜色”或“图案”。这种区别有时可以被认为是可以接受的,尽管这种可接受性标准非常主观,导致整个管道的准确性波动
(2)在匹配值和属性时,LLM的输出也不完全令人满意。例如,属性“尺寸”LLM匹配的值为“成熟时长度为6mm”时。而理想的输出应该只输出“6mm”。
五、总结与思考
1.论文提出了一个完整的异构数据信息提取框架FINDER,展示了LLM在大规模异构数据中提取信息的潜力,而且几乎不需要人为干预。
2.论文利用EBR(基于嵌入的检索)技术将文档矢量化并存储在矢量数据库中,检索时通过计算文档向量与搜索内容向量之间的距离来确定相关文档。以此来克服大型语言模型(LLM)输入限制的思路比较新颖,值得后续实验思考和借鉴。
3.尽管该框架已经具备一定的信息提取能力,但不能使LLM的输出高精确度的答案,有一部分答案处于“可接受”的范围,不精准,但又部分正确。所以该框架否能够实际应用仍然是未知的,有很大的改进空间。