作者:Yuanhe Tian, Ruyi Gan, Yan Song, Jiaxing Zhang, Yongdong Zhang.
单位:University of Science and Technology of China,University ofWashington,
International Digital Economy Academy.
来源:ACL (Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics)
时间:2024.8
一、研究背景与目的:
1、研究背景:
医疗领域需求:随着医疗服务需求的增长,医疗基础设施的差距愈发明显,大数据特别是文本数据成为医疗服务的基础,迫切需要针对医疗领域的自然语言处理(NLP)解决方案。
现有模型局限性:虽然现有的大型语言模型(LLMs)为医疗文本处理提供了先进的基础,但大多数医疗LLMs仅通过监督微调(SFT)进行训练,虽然能高效理解并响应医疗指令,但在学习领域知识和与人类偏好对齐方面存在局限。
2、研究目的:
设计目标:为解决上述问题,该文提出CHIMED-GPT,一个专为中文医疗领域设计的新基准LLM。
训练体系:CHIMED-GPT经历了包括预训练、监督微调和从人类反馈的强化学习(RLHF)在内的全面训练体系。
二、主要内容

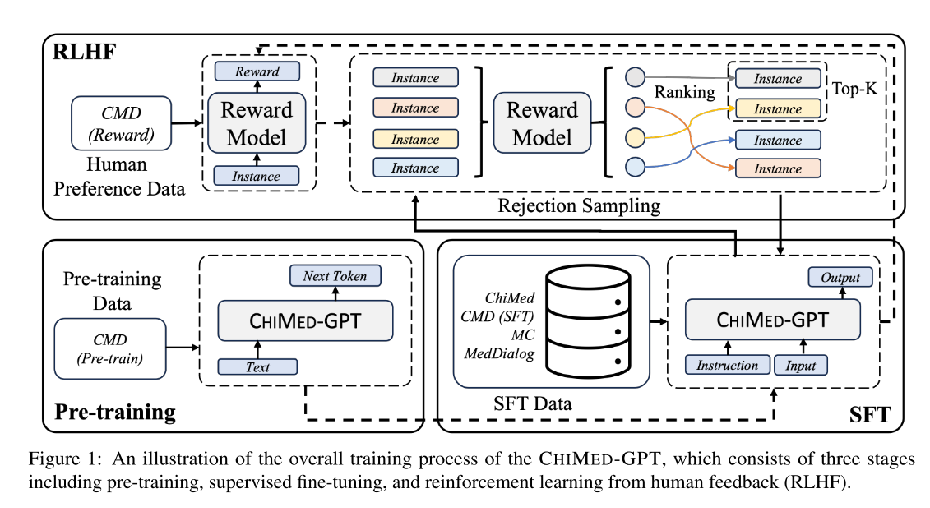
1、预训练
该文采用中国医学数据集 (CMD)的预训练子集,基座模型为Ziya-13-v2 。该子集包括两部分,第一部分包括来自医学百科全书数据的 369,800 份文档,而第二部分包括来自医学教科书的 8,475 篇文章。鉴于其丰富的医学内容,CMD (pre-train) 被证明非常适合预训练模型。
2、SFT
SFT 数据的质量和多样性至关重要。为了增强模型在真实医疗环境中理解人类指令的能力,该文还设计了一个强大的 SFT 流程,该流程利用医生和患者之间的 QA 和对话数据(包括ChiMed、CMD (SFT)、中文医学对话数据集(MC)和MedDialog)。
3、RLHF
对于奖励模型训练,该文采用CMD的奖励子集CMD(Reward)作为学习奖励模型的数据集。具体来说,CMD(Reward)由4K实例组成,这些实例分为训练集、验证集和测试集。每个实例都有一个从CMD(SFT)数据集中采样的问题,并附有一个被接受的答案和一个被拒绝的答案,其中被接受的答案由医生提供,被拒绝的答案由BenTsao LLM提供。与以前的研究不同,作者进一步通过从 GPT-4 和 GPT-3.5-Turbo3 中提取的两个额外的中间响应来增强 CMD(奖励),而不是直接将其应用于训练奖励模型,因此模型生成的响应能够更好地符合人类偏好,从而进一步降低 CHIMED-GPT 生成不适当内容的风险。
答案按照与人类偏好重新排序:被接受的答案、GPT-4 的回答、GPT-3.5-Turbo 的回答和被拒绝的答案。
首先从 SFT 数据中随机抽样 10K 提示,并将它们提供给CHIMEDGPT。然后,使用奖励模型为最后一步生成的输出分配分数。之后,根据 LLM 产生的文本对他们的分数进行排名,并选择前 k 名的回答,这些回答被视为进一步微调的数据集构成。
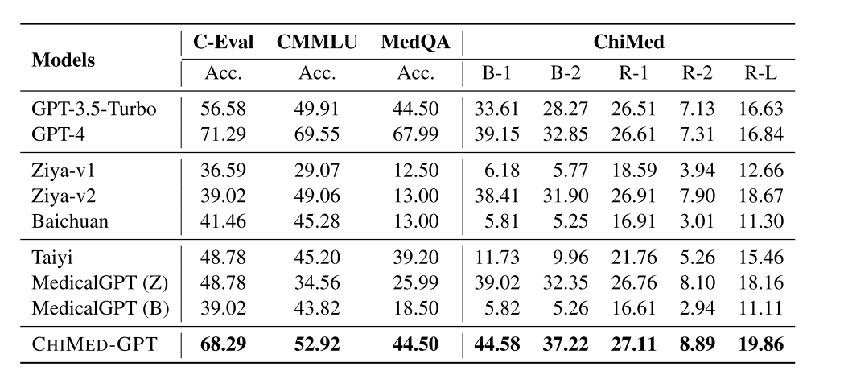
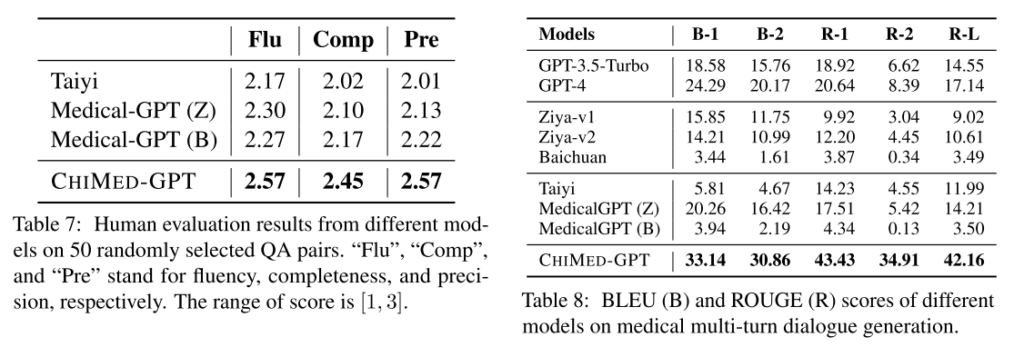
三、实验评估

四、论文总结
在该文中,作者提出了用于中文医学文本处理的 CHIMED-GPT,它建立在 Ziya-13B-v2 之上,并继承了其处理大量上下文长度的能力。
CHIMED-GPT 是通过一个整体训练框架学习的,该框架无缝集成了预训练、SFT 和 RLHF 阶段,并确保它不仅捕获特定领域的知识,而且能够适应多种场景,超越通常仅求助于 SFT 的现有模型。
典型医学文本处理任务(即信息提取、问答和对话生成)的实证结果表明了 CHIMED-GPT 的有效性,它优于不同基准数据集上的强大基线和现有研究。进一步的分析表明,CHIMED-GPT 的偏差相对较低,这证实了CHIMED-GPT在医学领域的能力。