作者:Jeongsoo Choi,Joon Son Chung等
单位:KAIST,Microsoft
来源:arXiv 2024年11月29日
一、主要内容
目前video-to-speech系统在说话人和词汇量受限数据集上显示出有前景的结果,但在无约束数据集上性能会下降。V2SFlow提出将语音信号分解成可控的子空间,每个子空间代表不同的属性,并直接从视觉去预测他们。为了从这些预测属性生成连贯真实的语音,采用基于Transformer架构的校正流匹配解码器,从随机噪声到目标语音分布的有效概率路径进行建模。达到sota性能甚至超越真实语音的自然度。
二、方法
语音分解:
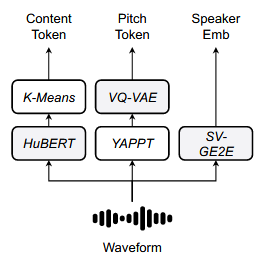
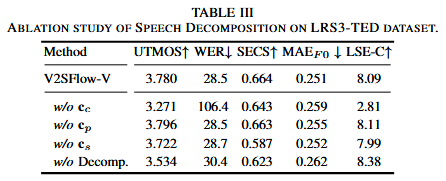
将语音分解成内容、基频和说话人音色三个子空间。内容标记由自监督语音模型HuBERT特征由K-means算法离散得到,可以捕获独立于副语言线索的语言信息;基频在表现韵律上至关重要,这篇文章采用YAPPT算法从原始音频中提取基频序列,在经过归一化获取基频变化,同时减少说话人信息,再训练一个VQ-VAE模型将序列编码到离散的隐空间中;说话人嵌入由GE2E损失优化的预训练说话人验证模型提取。
语音属性预测:
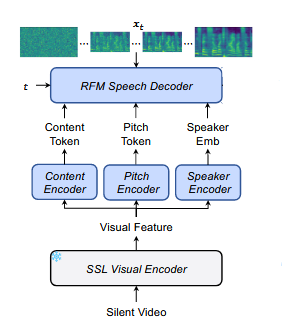
使用预训练的AV-HuBERT Large模型从视频中提取视觉特征,通过各自的编码器预测每个语音属性,模型使用Conformer。
内容编码器通过交叉熵损失优化,α为标签平滑参数:
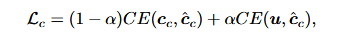
基频编码器使用交叉熵损失优化,α为标签平滑参数:
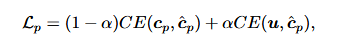
说话人编码器通过沿时间维度平均输出特征来生成单个全局说话人嵌入,应用余弦相似度损失优化:
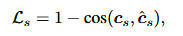
每个编码器都是单独训练的。
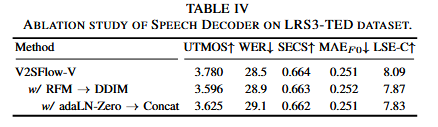
语音解码器:
引入基于Transformer主干的基于校正流RFM匹配解码器,RFM估计从随机噪声到目标数据样本的概率路径的向量场。与基于扩散的模型类似,它对易处理的先验分布和目标分布之间的概率路径进行建模。RFM的目标是在先验分布x0 ~ p0(x)和目标分布x1 ~ p1(x)之间建立直线路径,寻求最小化采样步数。给定条件c和时间步t ∈ [0, 1]的中间数据样本xt = (1-t)x0 + tx1,训练RFM生成器模型θ估计向量场u(xt, t | x1, c) = x1 – x0:
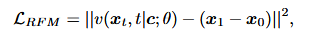
其中v(xt, t | c, θ)是估计的向量场。
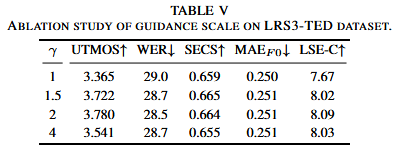
这篇文章通过沿通道维连接所有语音属性作为条件c。通过采用无分类器指导来放大条件采样轨迹。
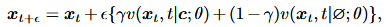
三、实验设置
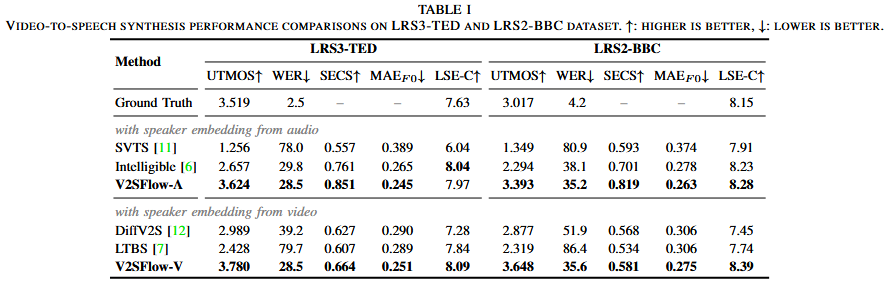
数据集:LRS3-TED上训练和推理,LRS2-BBC仅推理。
评估指标:UTMOS评估感知自然度,WER评估清晰度,SECS(说话人嵌入余弦相似度)评估说话人表示之间的相似性,MAE F0评估基频精度,LSE-C评估唇同步精度。
预处理:视频裁剪并转换为灰度,音频转换为80维mel谱图,跳大小160,窗口大小640并归一化,叠加20ms的mel谱图以获得50hz特征。
声码器采用HiFi-GAN。
基线模型:研究两种不同说话人嵌入的影响——一个来自参考音频,另一个从视频中预测。实验分为两种变体V2SFlow-A和V2SFlow-V。V2SFlow-A和SVTS、Intelligible进行比较,V2SFlow-V和DiffV2S、LTBS比较。
四、实验结果
语音质量比较:

消融实验:
五、总结思考
1、引入语音属性分解和校正流匹配生成mel谱,重构语音质量高。
2、消融实验中基频条件的消融在MAEF0的指标数值上变化不大,但其他指标都有所提升,可能是因为视觉特征和基频信息的关联性不大,预测的基频标记准确率不高,对最后重构的语音质量有害。