作者:Jin, Qiao and Wang, Zifeng and Floudas, Charalampos S and Chen,
单位:nbci(美国国家生物技术信息中心)
来源:Nature Communications
时间:2024年10月1日
一、研究背景与动机
• 临床试验的关键作用:临床试验是验证医疗干预有效性和安全性的重要手段,不仅为临床实践提供关键科学依据,也为患者提供获取创新治疗方案的机会。
• 患者匹配的现实挑战:目前患者与临床试验的匹配过程面临着严峻挑战。人工匹配不仅需要详细分析患者的病历信息、症状和检查结果,还要理解复杂的试验入排标准。
• 现有技术方案的局限:传统的双编码器方法会独立编码文档和查询,而不考虑文档的上下文信息。这种缺乏上下文的嵌入在出域(out-of-domain)检索任务中表现不佳。
二、研究目标
本文旨在通过增加上下文信息来提升文档嵌入的效果,尤其在特定领域的检索任务中,实现更好的跨域泛化能力。通过构建一个端到端的框架,实现从患者筛选到最终匹配的全流程自动化,同时保证匹配结果的准确性和可解释性。
首次提出利用大语言模型进行零样本患者-试验匹配的框架TrialGPT。该框架无需大规模配对训练数据,可以适应新的临床试验标准,具有良好的泛化能力。通过创新的三模块架构设计,实现了高效精准的患者筛选,并提供详细的匹配理由和证据支持。
三、框架
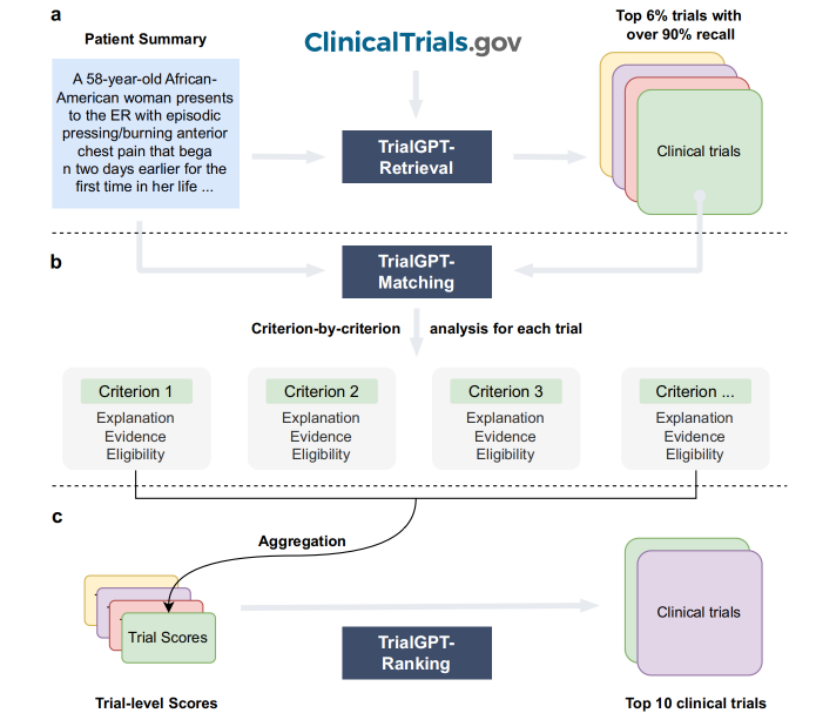
- TrialGPT-Retrieval用于大规模候选试验筛选
- TrialGPT-Matching进行标准级别的患者资格预测
- TrialGPT-Ranking负责生成试验级别的评分
该框架的主要优势在于其端到端的处理能力和高度的可解释性。通过自然语言生成技术,系统能够提供详细的匹配理由和证据支持,帮助医疗专家快速理解和验证匹配结果。同时,其零样本学习能力使其能够适应不同疾病领域的临床试验。
四、实验
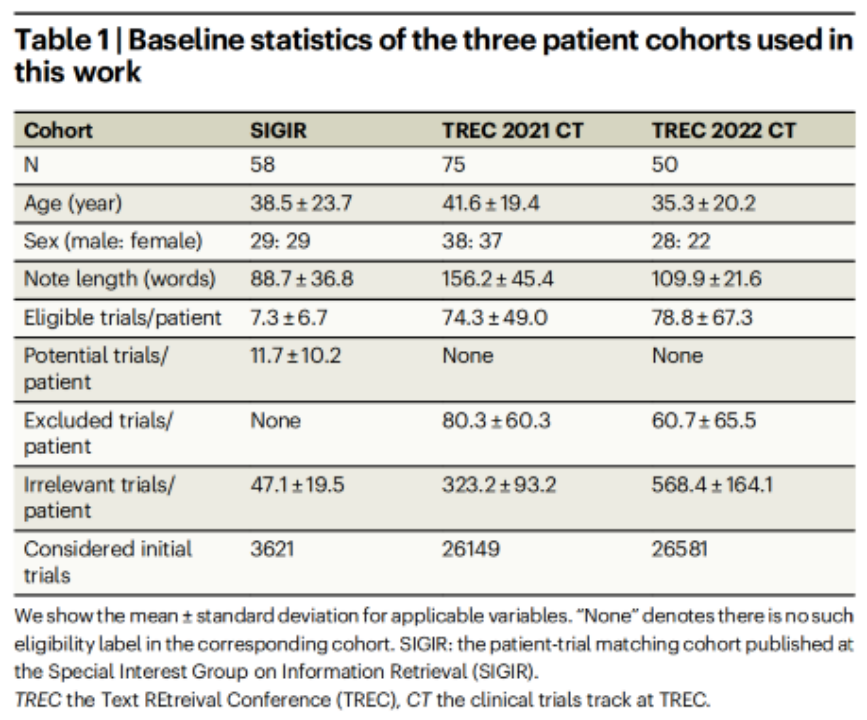
数据集详情
性能评估:
实验结果表明,TrialGPT在各项指标上都取得了显著提升。在检索阶段,仅需使用5.5%的初始集合即可实现90%的召回率。匹配准确率达到87.3%,接近专家水平。在排序任务中,比现有最佳方法提升了43.8%的性能。
用户验证:
通过在国家癌症研究所进行的实际用户研究,证实系统可以显著提高工作效率。两位医生的对照实验显示,使用TrialGPT可以节省42.6%的筛选时间,同时保持97.2%的准确率,充分证明了系统的实用价值。
五、对齐思考
首先,论文采用的三级架构(Retrieval-Matching-Ranking)设计值得借鉴,特别是在检索阶段使用LLM生成关键词,并采用混合检索策略(结合BM25词法匹配和MedCPT语义匹配)的方法很有参考价值。但值得注意的是,TrialGPT的个性化主要体现在患者-试验匹配上,而医学文献检索需要考虑研究者的专业背景、研究兴趣等更复杂的个性化因素。这启发我们在设计个性化prompt时,不仅要考虑用户的检索意图,还要融入用户画像、领域知识等信息,并设计动态调整机制来优化prompt策略。此外,在评估体系上也需要更全面,除了传统的召回率和准确率,还应该关注文献的相关性、研究价值等多个维度。