作者:Chaohui Yu, Qiang Zhou, Jingliang Li
单位:阿里巴巴达摩院
来源:ACM
发表日期:2023
研究背景及意义
在数十亿图像文本对训练的 2D 扩散模型的推动下,文本到 3D 的生成最近引起了极大的关注。
现有方法主要依靠分数蒸馏来利用 2D 扩散先验来监督 3D 模型的生成,例如 NeRF。然而,分数蒸馏很容易出现视图不一致的问题,并且隐式 NeRF 建模也会导致任意形状,从而导致 3D 生成不太真实且无法控制。
在这项工作中,他们提出了一个灵活的 Points-to-3D 框架,使用 3D扩散模型生成的稀疏点云 Point-E作为几何先验,以单个参考图像为条件。更好的利用稀疏 3D 点,同时优化NeRF使外观具有一致性。
研究思路及方法
①提出了一种新颖且灵活的文本到 3D 生成框架,名为Points-to-3D,从预训练的 2D 和 3D 扩散中提取知识弥合了稀疏 3D 点与更真实且形状可控的 3D 生成之间的差距模型。
②为了充分利用稀疏的 3D 点,他们提出了一种有效的点云引导损失来优化 NeRF 的几何形状,并使用以文本和学习深度图为条件的 ControlNet 通过分数蒸馏来学习几何一致的外观。
③实验结果表明,Points-to-3D 可以显着缓解视图之间的不一致,并在文本到 3D 生成中实现对 3D形状的良好可控性。
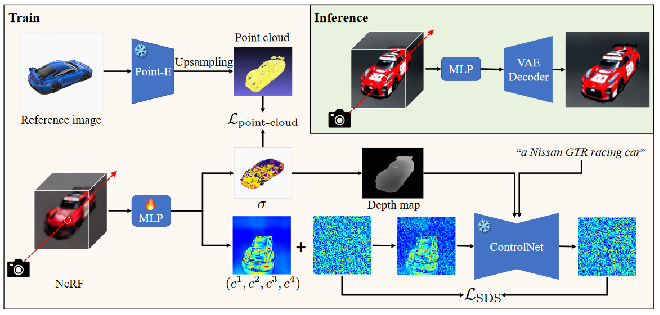
Points-to-3D 框架
其有三部分组成三部分组成:
场景表示模型(MLP)
文本到图像的2D扩散模型(ControlNet)
点云3D扩散模型(Point-E)
场景模型:神经辐射场(NeRF)是一种用于场景表示的重要技术,由体积光线追踪器和 MLP 组成。
Scene Model
在这项工作中,他们采用Latent-NeRF的高效设计,产生五个输出,包括体积密度 σ和四个伪彩色通道
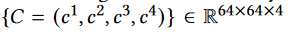
对应于潜在扩散模型的四个输入潜在特征:
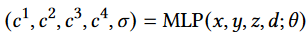
其中 x、y、z 表示 3D 坐标,d 是视图方向。我们默认使用Instant-NGP 作为场景表示模型。
Text-to-Image 2D Diffusion Model
在这个模型中使用以深度图为条件的预训练 ControlNet作为 Points-to-3D 中的 2D 扩散模型。
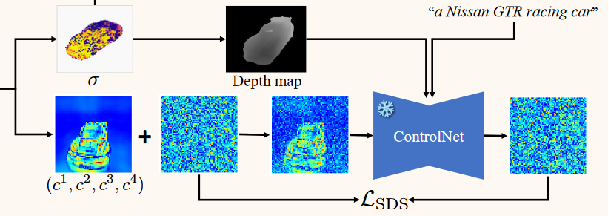
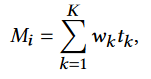
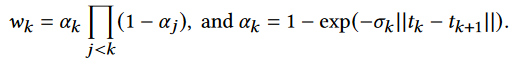
其中 K 是沿一条射线的采样点总数,tk 表示k点的深度假设。预测深度图 M 越好越准确,ControlNet 合成的几何视图就越一致。
Point Cloud 3D Diffusion Model
Sparse 3D Points Guidance
Points-to-3D的核心思想是引入可控的稀疏3D点来指导文本到3D的生成。在本节中,将详细介绍如何利用稀疏 3D点。使用稀疏的 3D 点云来指导NeRF 的几何学习是具有挑战性的。
这项工作提出了稀疏点云引导损失。具体来说,令
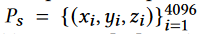
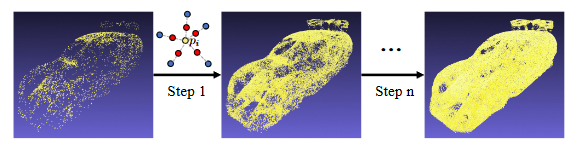
为Point-E在参考图像上生成的原始稀疏 3D 点。使稀疏点变得密集,本文通过一个简单的规则迭代执行 3D 点插值来对 Ps 进行上采样,即,对于每个点 pi,在每个最近的 q个邻居点和 pi 之间的中间位置添加一个新的 3D 点。该过程下图所示。
Training Objectives
Points-to-3D的训练目标由三部分组成:点云引导损失Lpoint-cloud,得分蒸馏采样损失 LSDS 和稀疏损失 Lsparse。提出了稀疏性损失,它可以通过正则化渲染权重来抑制漂浮物:
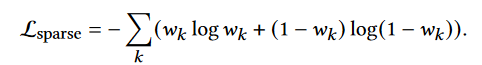
我们引入由下面等式计算的深度图条件M,并更新下一个等式中的分数蒸馏采样损失如下:
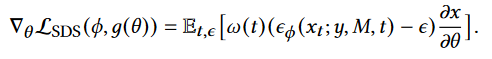
总体学习目标计算如下:
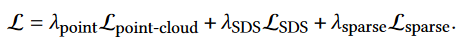
研究结论与创新

总结与思考
文本到3D和给定已知图像生成相似的3D内容在今后都有很广泛的使用,无论是在游戏、增强现实等多个方面。
Point-E相关的一些点云方法在3D的生成中能够起到很明显的作用。它能够更好的生成3D物体的合理形状。
现阶段进行方法改进的步骤流程为:
以点云生成3D物体或者场景的轮廓,再以扩散模型对其进行外观渲染,产生逼真合理的结果。