来源:Bioinformatics
作者:Minbyul Jeong 、 Jiwoong Sohn1、Mujeen Sung、Jaewoo Kang
单位:Korea University、Kyung Hee University、AIGEN Sciences
发表时间:2024年
一、论文介绍
背景:随着 LLMs 在 NLP 任务中的发展,为了解决 LLMs 在中医等缺乏专业知识和高质量数据的领域表现不佳的问题,研究者提出了一种框架,通过少量数据增强 LLMs 在中医诊断和处方任务上的表现。
目标:这篇论文开发了 Self-BioRAG 框架,利用 RAG 和自我反思机制增强大语言模型在医学问答中的准确性,减少幻觉,并推动医学 AI 应用。
二、核心内容
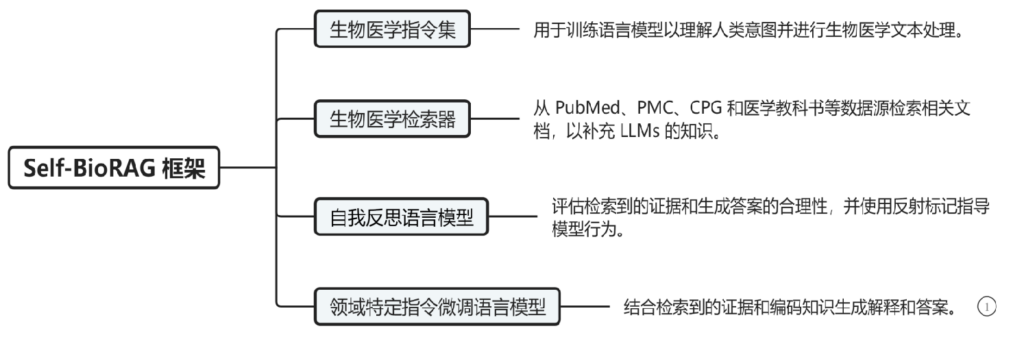
1、Self-BioRAG的框架包括四部分:生物医学指令集、生物医学检索器、自我反思语言模型、领域特定指令微调语言模型。
2、关于LM(语言模型)、RAG模型(检索增强生成模型)、Self-BioRAG三个框架的比较
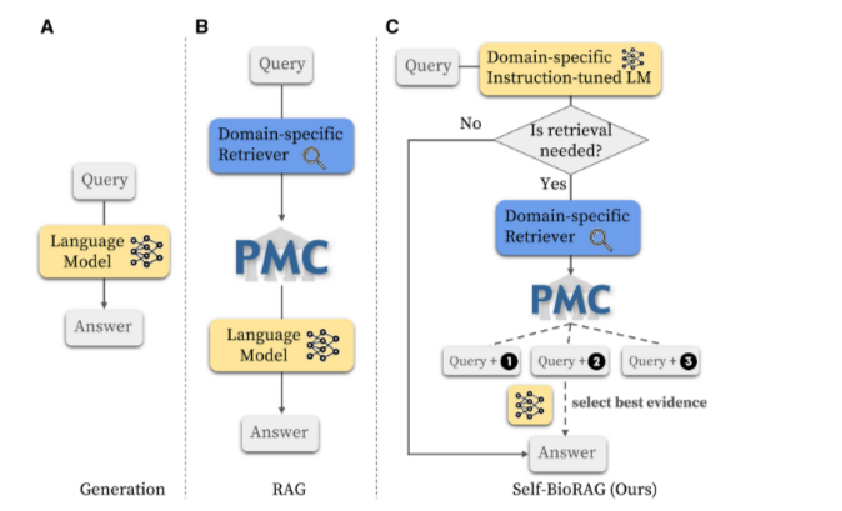
A:LM完全依赖于模型内部编码的知识来生成答案。
B:RAG模型在LM基础上增加了一个检索组件。它会从PubMed Central知识库中检索信息作为额外的上下文信息。
C:Self-BioRAG增加了领域特定的指令调整的语言模型预测信息检索的需求、利用MedCPT获取相关文档、并结合自我反思机制来生成并评估精准的医学解释和答案。
3、Self-BioRAG流程概述,通过从12万生物医学指令集中随机抽样5千个,利用GPT-4 API生成反思标记来训练Critic LM C,筛选后训练Generator LM M,实现直接生成答案或检索外部信息作答。
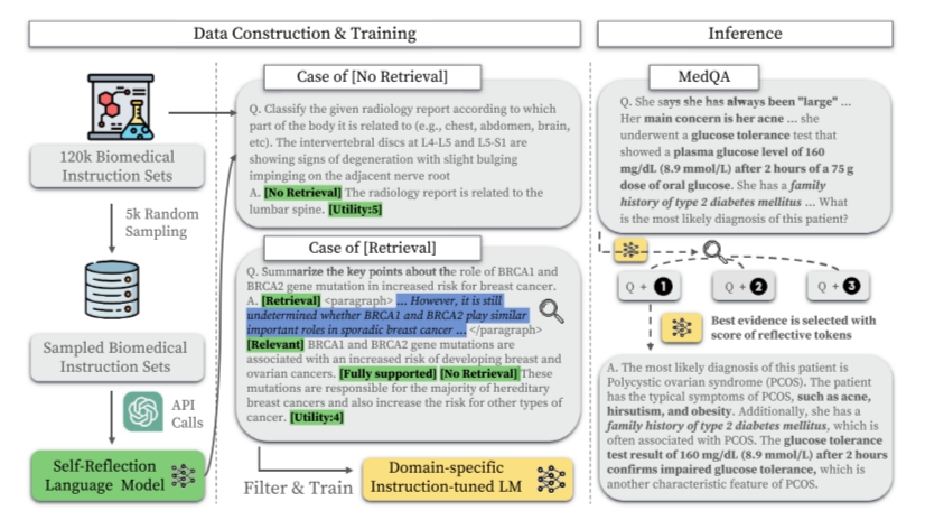
Self-BioRAG流程是一个生物医学领域的问题解答系统,它通过从12万生物医学指令集中随机抽取5000个样本,利用GPT-4 API生成反思标记来训练Critic LM C,然后筛选总体的生物医学指令集并训练Generator LM M,使其能够直接生成答案或检索外部信息以回答医学相关问题。
第二部分是举例两种情况:一种是不需要进行外部检索的直接利用内部指令和自我反思机制生成答案,另外一种是需要经过外部检索生成答案的。Critic LM C然后筛选总体的生物医学指令集并训练Generator LM M,使其能够直接生成答案或检索外部信息以回答医学相关问题。
第三部分是举实例演示
4、critic LM C训练过程以及generator LM M训练过程:critic LM C如何学会评估generator LM M的答案和generator LM M如何学会回答问题并自我评估
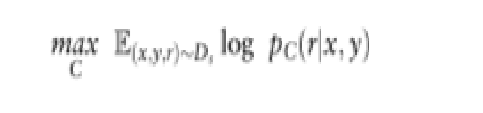
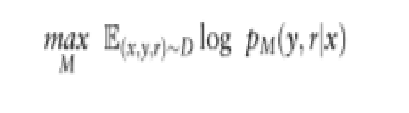
max :这个符号表示我们正在优化模型C(M)的参数,以最大化期望值。
C(M)
E(x,y,r)~Ds:这是期望值符号,Ds(D)表示训练数据集,它由输入x、输出y和反思令牌r组成。期望值是在所有训练样本上的平均值。
logpC(M)(r∣x,y)。这是模型C(M)预测给定输入x和输出y的反思令牌r的对数概率。希望模型C(M)能够准确预测这些反思令牌。
5、模型在生成答案时进行自我评估,并根据检索到的文档的相关性来选择最佳证据
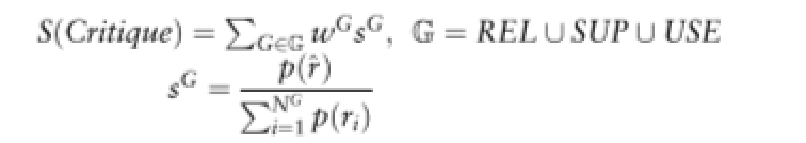
在这个公式中, S(Critique)是生成器模型M用来决定是否需要检索相关文档,并从检索到的前k个文档中选择最佳证据的总分数。该分数是根据不同反思标记类型(REL、SUP、USE)的加权和计算得出的,其中每个 wG是对应反思标记类型的权重超参数,用于调整这些反思标记在决定最佳证据时的重要性。sG表示模型预测最理想反思标记r^的概率与该类型所有可能反思标记概率之和的比值,反映了最理想反思标记的生成概率。通过这个公式,模型能够根据问题的需求,动态地评估和选择最有用的信息,以生成准确和有用的回答。
三、实验内容
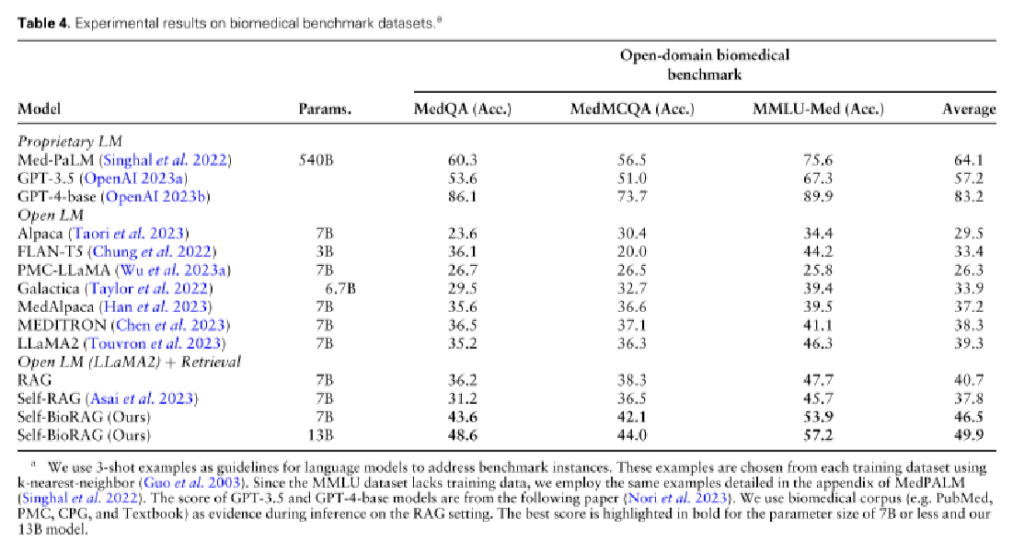
1、生物医学基准实验结果:实验包括6个临床主题2个数据集,旨在衡量语言模型中编码的生物医学和临床知识。
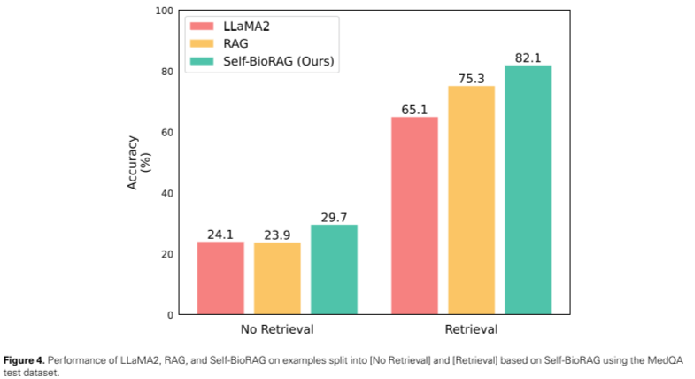
2、用MedQA测试数据集检测性能以及测试中的一个基于证据的Self-BioRAG预测病例报告

四、论文总结与思考
这篇论文提出的Self-BioRAG框架,通过集成领域特定的指令集和检索器,显著提升了大型语言模型在生物医学问答任务上的能力,为中医知识问答系统的研发提供了重要启示,强调了定制化数据和指令集的重要性,展示了检索与生成技术的结合优势,并指出了模型优化方向,以适应中医知识的复杂性和特殊性,从而提高问答系统的准确性和实用性。