作者:Ali Anaissi, Ali Braytee, Junaid Akram.
单位:School of Computer Science, The University of Sydney, Australia
TD School, The University of Technology Sydney, Australia.
来源:2024 IEEE International Conference on Data Mining Workshops (ICDMW).
一、研究背景
1、现有微调方法:
LoRA:通过向特定模型层添加可训练的低秩适配器来促进有效的参数微调。
RsLoRA:通过引入秩稳定缩放因子来增强LoRA,从而防止梯度崩溃并确保更高秩的稳定学习。
DoRA:通过将预训练模型的权重分解为幅度和方向矩阵来改进该方法,从而实现更精确的模型自适应。
2、该文章创新点:
RsDoRA+:该方法将分解的模型权重与低秩矩阵的秩稳定和差分学习率相结合,从而显着提高LLM在医疗质量保证服务中的性能。
ReRAG:该方法集成了按需检索和问题重写组件,以提高医疗质量保证响应的准确性和相关性。
二、主要内容
1、rsDoRA+的工作原理
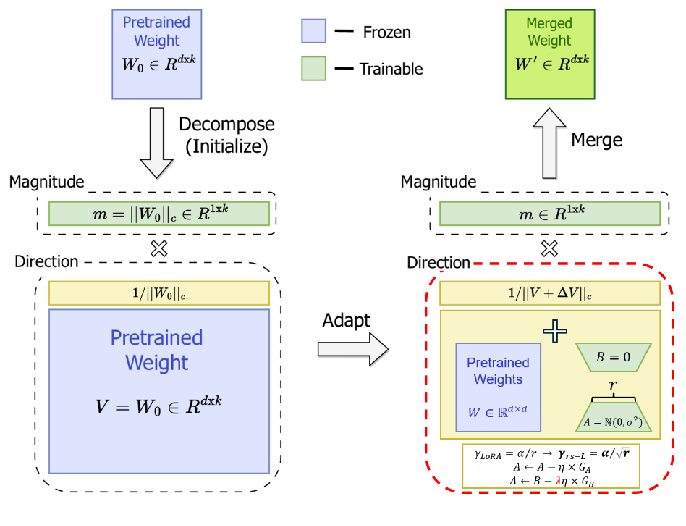
(1)模型权重分解:
首先,rsDoRA+ 将预训练模型的权重分解为两个低秩矩阵:一个表示权重的方向,另一个表示权重的幅度。
这种分解可以减少需要训练的参数数量,从而提高训练效率。
(2)Rank-Stabilized LoRA (rsLoRA):
rsDoRA+ 采用 rsLoRA 的方法,通过引入秩稳定化缩放因子来防止梯度消失或爆炸,从而提高学习效率和稳定性。
这使得模型能够在高秩情况下仍然保持良好的性能。
(3)LoRA+:
rsDoRA+ 还借鉴了 LoRA+ 的方法,为低秩矩阵的每个部分设置不同的学习率。
这有助于模型更有效地学习不同类型的特征,从而提高整体性能。
(4)NEFtune:
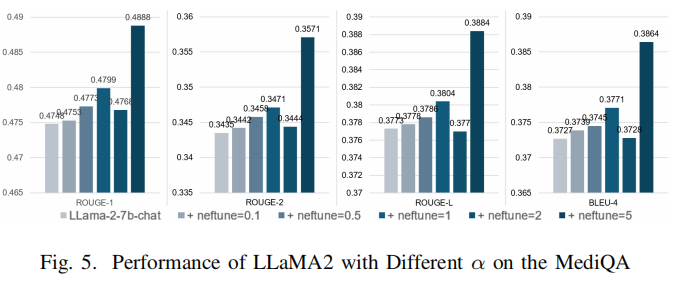
rsDoRA+ 还结合了 NEFtune 技术,通过在嵌入向量中添加噪声来防止过拟合。
这使得模型能够更好地泛化到未见过的数据,从而提高其鲁棒性。
2、RsDoRA+的重参数化
3、ReRAG
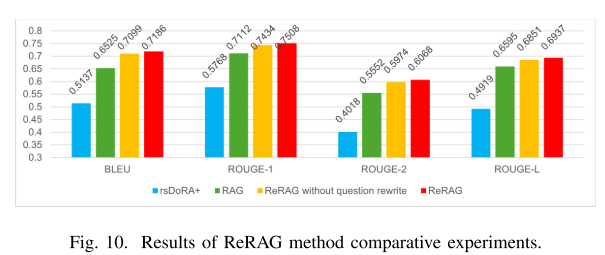
ReRAG模型受SlefRAG方法的启发,引入了标记来评估检索到的文本对回答问题的必要性和相关性。基本RAG模型有时会添加不相关或不必要的文本,从而降低性能。为了增强这一点,ReRAG结合了检索标记和相关性标记,以过滤掉无用的检索到的文本和不需要额外检索的问题。
ReRAG的简化结构,如下图所示,旨在通过集成一个问题重写组件来提高性能,该组件确保检索到最有用的文本。

三、实验评估
实验细节
1、数据集和环境设置:
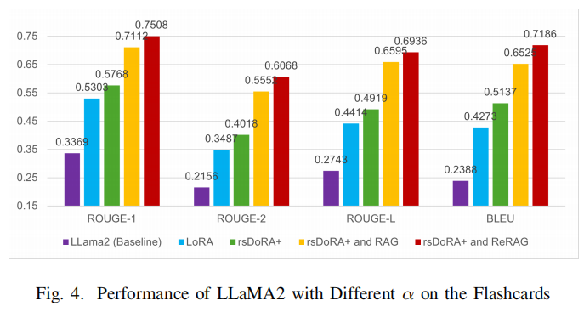
数据集:该实验使用了来自 Medical Meadow 的数据,其中包括 Anki Flashcards 和 MediQA 数据集。这两个数据集涵盖了广泛的医学知识,能够评估模型在不同场景下的表现。
环境设置:作者为 rsDoRA+ 和 ReRAG 分别设置了不同的实验环境。对于 rsDoRA+,需要安装必要的库和依赖项,并下载基础模型进行微调。对于 ReRAG,需要安装库,设置检索和向量数据库,并使用 rsDoRA+ 微调后的模型作为生成器。
2、实验设置和验证:
基线模型:作者使用了7B参数的 LLaMA2 和 Mistral 模型,并比较了全参数微调、LoRA 微调、rsDoRA+、rsLoRA+DoRA 和 LoRA+ 等不同方法的性能。
评估指标: 作者使用了 BLEU 和 ROUGE 等指标来评估模型生成的答案的准确性和相关性。
四、总结
1、该文章提出的结合体rsDoRA+ 。通过采用 rsLoRA 的方法,通过引入秩稳定化缩放因子来防止梯度消失或爆炸,从而提高学习效率和稳定性。rsDoRA+ 还借鉴了 LoRA+ 的方法,为低秩矩阵的每个部分设置不同的学习率。最后还结合了 NEFtune 技术,通过在嵌入向量中添加噪声来防止过拟合。
2、该文章提出的新检索方法ReRAG(按需检索和问题重写),它集成了检索和问题重写组件,以进一步增强模型性能。RsDoRA+通过利用具有秩稳定的分解模型权重来提高模型对医学术语、推理和上下文准确性的理解。ReRAG通过按需提供相关信息并确保检索最相关的数据来优化模型的性能。
3、对抗性训练通过引入对抗性示例来增强模型的鲁棒性,向数据集中添加了人类几乎无法察觉但会导致模型做出不正确预测的轻微扰动。这使得模型对此类示例更具抵抗力,并提高了鲁棒性。在训练期间向嵌入层添加噪声可以减少对特定细节的过度拟合,如格式、精确文本和微调数据集的文本长度。