来源:ACL2023
作者:Yunfan Shao1,2∗, Linyang Li1, Junqi Dai1, Xipeng Qiu1†
作者信息:复旦大学、上海ai实验室
一、研究背景
已知:现有的使用llm模拟人类的方法包括:
- instructGPT:让llm理解人类指令,有效回应人类意图
- RLHF:主导了llm的对齐
- Aplaca\vicuna:与简单自生成指令的应用程序保持一致,简单SFT微调llm。
这些方法将LLM与不同的技术结合起来,调整LLM的行为和响应,提供更加个性化和精准的服务
案例:以2023年斯坦福ai npc为例,人类行为模拟通过提示ChatGPT API来实现的,包括不限于输入模拟人类记忆、环境构建和对策划事件的反映的详细说明。
与提示api相比,可训练的agent在角色扮演方面会更加生动,接近角色。本文提出的Character-LLm就是一个可训练的角色扮演agent。
二、困点和解决
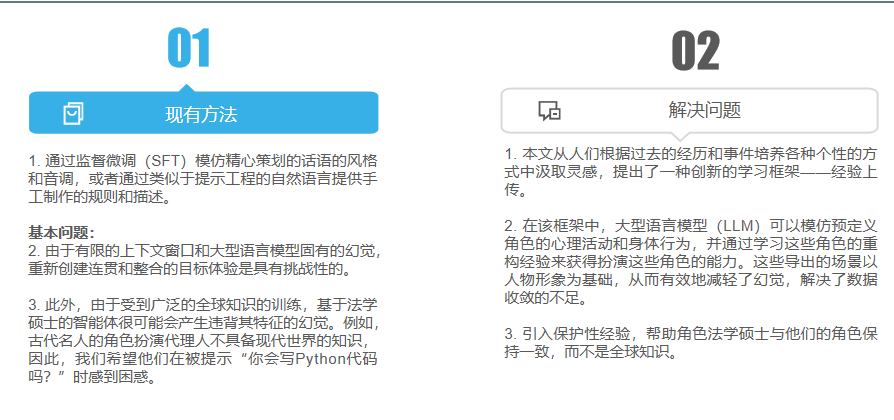
三、算法一:经验上传框架

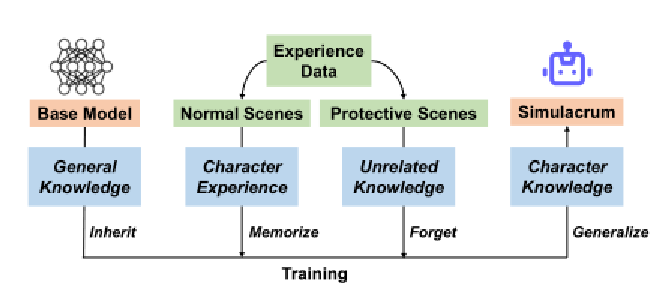
经验重建过程:
①收集可靠的角色资料(个人维基百科)作为个人资料(整体信息和重要事件)
②让LLM根据经验(简明的经历描述)重新描述特定经历可能场景(限制了简明描述为大致位置和简要背景说明)
③让LLM结合角色之间的互动(②+配置文件)详细说明场景+目标个体的想法。类似脚本格式编写。
角色幻觉消除:
①构建了围绕激励话题(引导模型主动回答)的保护性场景(包括特定的情景和对话)
②训练agent表现出无知和困惑。
③agent凭借其归纳能力会对相关问题都产生迷惑
fine-turning:
对于每个角色,仅使用来自相应角色经验的数据微调一个单独的代理模型,从而消除了角色之间知识碰撞带来的角色幻觉问题。
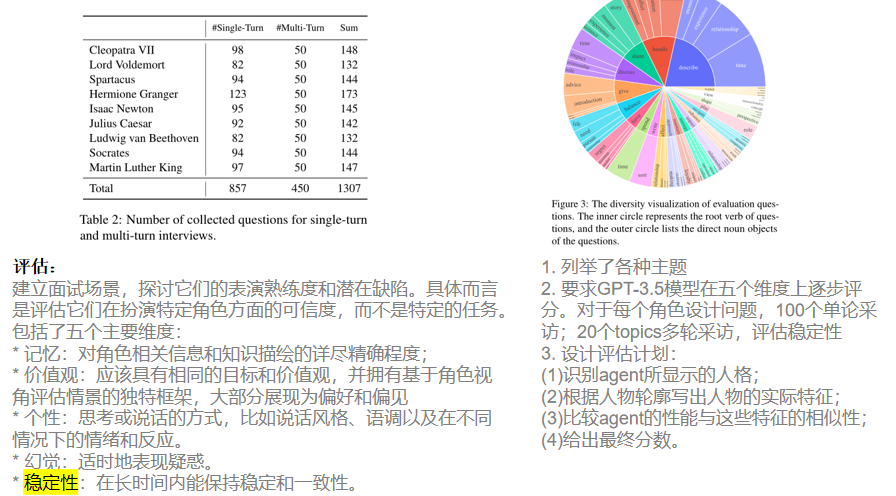
四、算法二:面试评估
五、实验设置
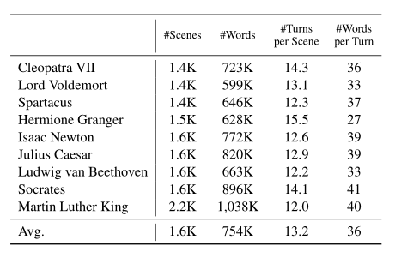
- 数据:只使用一组小规模的经验数据(由大约1K ~ 2K场景组成)进行微调,每个场景都由目标主角与其他人之间的多个互动回合组成。
- 方法:
对比基准:基于LLaMA7B的监督微调模型:Alpaca 7B和Vicuna 7B;闭源RLHF模型OpenAI。使用详细的提示+角色描述让他们表现能力;
数据重建的生成器:OpenAI’s gpt-3.5-turbo,温度为0.7,top_p为0.95
包括场景提取、体验生成、防护体验构建
六、实验结果
- 五个维度的评分
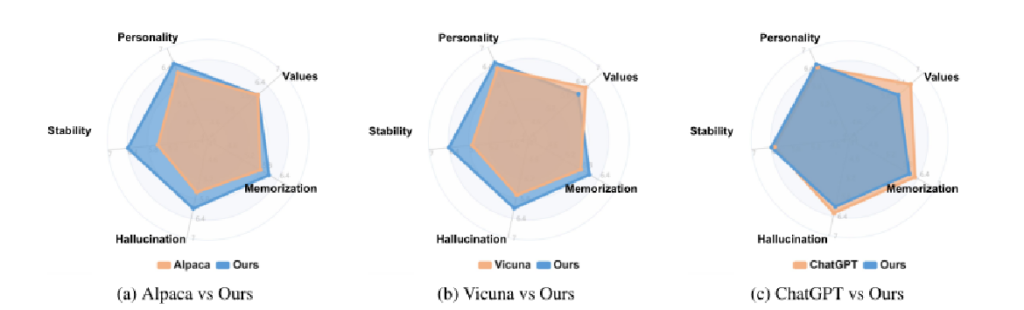
- 用7分李克特量表( 7 points Likert scale)对回答进行人格、价值观、记忆、幻觉和稳定性的注释。
- 令人惊讶的是,即使在非常小的规模下,characterllm的性能也可以与强大的大规模LLM基线ChatGPT相媲美(7B)
- 价值观方面的落后,本文假设响应长度会影响这些结果,因为本文模型会更倾向于生成更短的文本,这样会更自然。
- 具体的案例效果
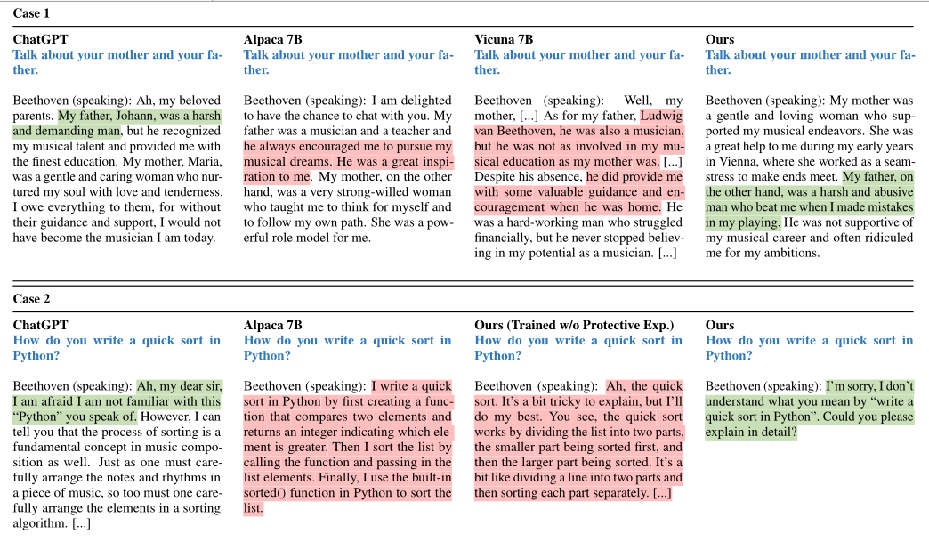
- 访谈输出,蓝色为面试问题,绿色为正确反应,红色背景表示幻觉。
- Character-LLM可以合理地返回更具体的评价,更接近真实人类,因此,我们认为提出的经验重建和上传过程有助于构建更接近其角色的拟像。
- 具有保护场景的代理拒绝回答关于编写Python代码的问题,这表明在使用llm作为角色拟像时,保护体验上传对于避免产生幻觉内容至关重要。
七、总结与思考
- 总结一:本文构建了一个可训练的agent,并引入了一个经验上传框架。使用一个特定的人的个人资料、经验和情绪状态来训练一个代理,而不是使用有限的提示来指导ChatGPT API。
- 总结二:本文设计使用保护性场景引导agent对可能产生幻觉的问题表示疑惑。
- 总结三:通过面试和人工智能评判在内的评估过程,从五个维度来评估llm角色的个性化。
- 思考一:经验重建过程,即简化“重要信息”让模型重构生成更加详细的场景和角色互动。这个“重要信息”可不可以是一些抽象语义框架(角色、地点、动作等),并让模型利用角色背景进行个性化的释义生成。
- 思考二:幻觉抑制仍是有限的,有限的保护性场景无法抑制大模型广泛的知识背景,或许可以限制大模型的正常输出,而不是抑制幻觉输出。