单位:Zhejiang University,Alibaba Group,Nanjing University
来源:arxiv
发表时间:2024
背景
•改进查询重写的许多工作都试图利用带有反馈的强化学习的小模型,而非昂贵的大语言模型。
•目前的方法需要注释或反馈,泛化能力低且没有一个专门的查询重写的信号。
•灵感来源:传统信息检索(IR)系统中的重排模块,该模块基于查询对检索到的文档进行评分和排序,与查询重写的目标一致。
•该文提出RaFe,一个用于训练无注释的查询重写模型的框架。利用公开可用的重排器,RaFe提供了与重写目标非常一致的反馈。
Task
查询改写是将原查询q重新表述为另一种形式q’,以便更好地检索相关段落。 该方法目标是得到一个重写模型Mθ,将q重写为q’。
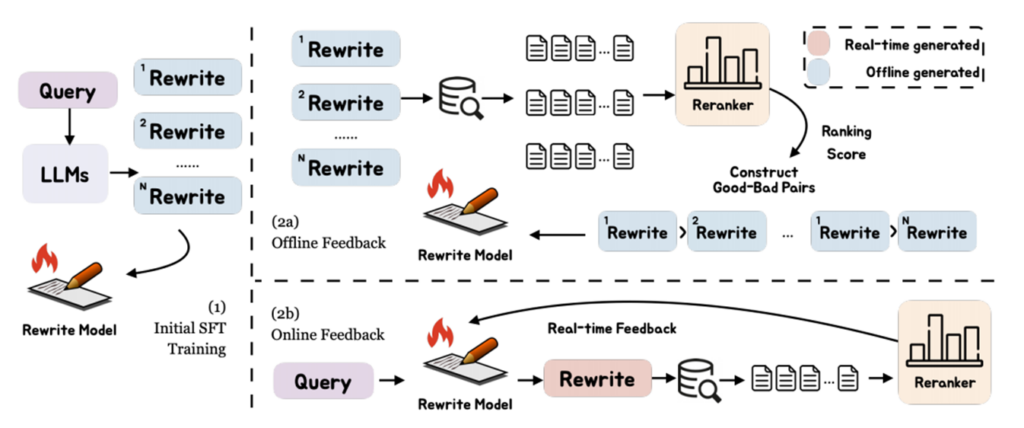
Initial Supervised Fine-Tuning
冷启动监督微调,初始化重写模型,以获得重写能力。
提示llm生成重写数据,制作一个训练重写的数据集。
由llm生成的重写记为Tall = {(q, q ‘)|q ’∈q‘},其中q’为原始查询q的重写集。
将训练实例分成两部分Tall = [Tsft: Tf],其中Tsft:和Tf分别表示用于SFT和反馈训练的实例。 用标准SFT损失训练重写模型Mθ。
对于英语数据,使用开放域QA数据集:NQ 、TriviaQA 、HotpotQA 。
从三个数据集的训练集中随机收集60k个实例,指导Tall来训练重写模型。
在评估方面,收集NQ和TriviaQA的测试集,以及HotpotQA的开发集作为保留的评估数据集。
使用FreshQA (Vu et al ., 2023)进行域外评估。
Feedback Training
使用重排器作为查询重写的自然反馈。
给定一个重新排序模型Mr,用查询q对文档d进行评分的过程可以表示为Mr(q, d)。根据Mr得到q’的排名分数,作为反馈信号。
离线反馈
•利用重写查询检索到的每个文档的排名分数来构造偏好数据。
•设置一个阈值来区分好的和坏的重写,平均排名分数与阈值的比较得到开放域QA的所有偏好对,(q, q’ g, q’ b)。
•使用DPO和KTO优化模型:DPO直接利用偏好对来优化模型,而KTO是一种可以从反馈中优化模型的方法,只需要一个能够表示q’是好重写还是坏重写的信号,而不需要整个偏好对。
在线反馈
•使用实时生成的排名分数作为在线反馈信号。
•利用近端策略优化(PPO) 算法来实现在线反馈训练。
•训练过程包括重写、检索、评分和最终提供反馈。
核心内容
•该文提出了一种新的查询重写框架RaFe,它利用重排器的反馈作为信号。
•RaFe不需要标注标签,确保了培训框架的通用性。
•该文使用通用的和公共的重排器验证RaFe在跨语言数据集上的有效性。
思考
•这种改写方式依赖于重排器的效能。
•使用带反馈的方法能有效改进查询改写的准确性。