作者:Hongyang Du, Zonghang Li, Dusit Niyato
来源:IEEE
发表日期:19 January 2024
一、研究背景
1.AIGC部分:随着我们朝着更具沉浸感和交互性的未来互联网迈进,AIGC 技术正迅速成为内容创建和交付的必要条件,内容创建和交付被认为是推动 Metaverse 的“引擎”。但AIGC 模型需要大型数据集和复杂的架构才能实现最先进的性能,从而导致大量资源消耗和更长的训练时间,且需要高端硬件和专用软件进行训练和推理,这使得个人难以访问和利用,高成本限制了 AIGC 的广泛采用,这是难点一。
2.Metaverse部分:Metaverse 预计将容纳许多用户类型,包括具有不同文化背景、语言和偏好的用户。因此,AIGC 模型必须能够生成为个人用户量身定制的内容,并满足他们的独特需求和期望,这难点二也具有挑战性。
3.核心相关部分:为了解决第一个难点,一种方法是采用 “一切即服务” 范式。具体来说,它们不是将经过训练的 AIGC 模型分发给用户设备,而是可以部署在网络边缘服务器上,从而通过无线边缘网络实现“AIGC 即服务”(AaaS)。当用户需要 AIGCservices 时,用户可以将需求上传到网络边缘服务器,该服务器通过 AIGC模式将结果返回给用户执行任务。而第二个难点是需要为许多用户选择最佳的 AIGC 服务提供商ASP,考虑他们的特定要求、个性、边缘服务器上可用的计算资源以及部署的 AIGC模型的属性,利用高效的调度算法,可以优化 AaaS 服务为用户带来的好处,增强他们的沉浸式体验和Metaverse的参与度。
二、论文主要贡献
在本文中,作者为了克服这些限制,提出了一种基于扩散模型的新型 AI GeneratedOptimalDecision(AGOD)算法。与扩散模型生成内容的 AIGC技术类似,调整扩散模型以生成最佳决策。
1.提出了一种 AaaS 架构,将 AIGC 模型部署在边缘网络中,为 Metaverse 中的用户提供无处不在的 AIGC 功能(适用于难点一)
2.提出了由扩散模型提供支持的 AGOD 算法,以在面对环境不确定性和可变性时生成最佳决策 (适用于难点二)
3.将提出的 AGOD 应用于 DRL,特别是以深度扩散软演员-评论家 (D2SAC) 算法的形式,该算法实现了高效和最优的 ASP选择,从而最大限度地提高了用户的主观体验(适用于难点一二)。
4.通过广泛的实验证明了所提出的算法算法的有效性,表明 D2SAC 优于DQN、DRQN、Prioritized-DQN、Rainbow、RE INFORCE、PPO和 SAC算法,不仅在研究的 ASP选择问题中,而且在各种标准控制任务中。
三、相关工作
为了使 AIGC 服务能够随时随地从任何设备访问,作者建议在网络边缘设备上部署 AIGC 模型,如图所示,以支持 AaaS。例如,Metaverse 用户可以通过移动设备将生成请求上传到边缘服务器。然后,服务器在完成任务后发送 AIGC的计算结果。此外,用户可以在将任务上传到 ASP 时自定义任务所需的计算资源。

而提高整个 AaaS 系统的 QoS,需要一种高效可行的算法来选择合适的 ASP。高质量的 AaaS 系统会产生令人满意的结果,并降低遇到可能对无线网络性能产生负面影响的问题或错误的可能性。ASP 选择问题类似于资源受限的任务分配问题,其目标是将传入的任务定位到可用资源,满足资源约束并最大化整体效用。同时引入了人类感知效用函数,用于具体描述该选择问题,凸显出用户选择适合的 ASP 的重要性。
四、算法提出
作者提出了 AGOD算法,该算法在扩散模型的帮助下从高斯噪声开始生成最优离散决策,并在此的基础上衍生出了新的深度扩散强化学习D2SAC算法。
1.AGOD 的动机
在决策问题中,决策方案可以表示为一组用于选择每个决策的离散概率。影响最佳决策方案的约束和任务相关因素可以被认为是环境。根据扩散模型,在当前环境下,最优决策解可以不断增加噪声直到它变为高斯,这称为概率噪声的正向过程。然后,在概率推理的逆过程中,可以将最优决策生成网络(即 πθ(·))视为一个降噪器,它从高斯噪声开始,根据环境条件(即 s)恢复最优决策解,即 x0。下图提供了扩散过程的图示。

2.概率噪声的正向过程
作为决策方案输出 x0 = πθ(s) ∼ R|A|是在观察到的环境状态 S 下选择的每个决策的概率分布,作者将前进过程中步骤 t 分布的离散向量表示为 xt,它与 x0 具有相同的维度。给定目标概率分布 x0,正向过程在每个步骤中添加一系列高斯噪声以获得 x1,x2,…,xT.从 xt−1 到 xt 的过渡定义为均值√ 1 −βtxt−1 且方差 βtI 为
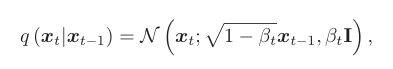
其中 t =1,…,T, βt =1−e−βmin T −2t−1 (6) 2T2 (βmax−βmin) 表示由变分后验 (VP) 调度程序控制的正向过程方差。由于 xt 在上一步仅依赖于 xt−1,因此前向过程可以被视为马尔可夫过程,给定 x0 的分布 xT 可以形成为跃迁 q(xt|xt−1) 在去噪步骤上的乘积,即
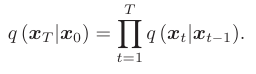
forwardprocess实际上并未执行,但它将 x0 和任何 xt 之间的数学关系建立为

其中αt =1−βt,̄ αt = t k=1αk 是 αk 在前一个去噪步骤 k (∀k ≤ t) 上的累积积,∼N(0,I) 是标准正常噪声。随着 t 的增加,xT 变为纯噪声,呈正态分布为 N(0,I)。
但是无线网络中的优化问题通常缺少数据集,因此在 AGOD 中不执行正向过程。
3.概率推断的反向过程
反向过程也称为采样过程,旨在通过去除噪声样本 xT ∼N(0,I) 来推断目标 x0。在AGOD 算法中,目的是从噪声样本中推断出最优决策方案。从 xt 到 xt−1 的跃迁定义为 p(xt−1|xt),不能直接计算。但是,它遵循由下式给出的高斯分布
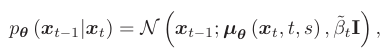
其中,平均值 μθ 可以通过深度模型学习,并且 ̃ βt = 1− ̄ αt−1 1− ̄ αt βt 是可以轻松计算的确定性方差幅度。
通过应用贝叶斯公式,我们将反向过程的计算转换为正向过程的计算,并将其重新格式化为高斯概率密度函数的形式。然后可以得到如下平均值:

AGOD 算法以探索性的方式学习,去噪网络的训练目标从最小化标记数据的误差转变为最大化决策方案的价值,即能够最大化优化目标。提出的一种可能的方法是构建一个决策价值网络,其输出评估决策方案产生的效用,即最优决策生成网络的输出。然后,可以联合训练这两个网络。然而这种方法是针对决策值是连续数值的情况。利用AGOD算法的适应性,目标是通过将 AGOD算法集成到先进的DRL 算法中,特别是在SAC 框架内来提高优化潜力。SAC 的效率和稳定的政策学习与 AGOD 的生成优势相辅相成。这种集成通过 AGOD 的探索和学习能力丰富了 SAC 模型,从而将 D2SAC 开发为基于扩散的 DRL 算法。
4.基于扩散的强化学习
下面作者对 ASP 选择问题进行建模,并通过在行动策略中应用 AGOD 来展示了创新的深度扩散强化学习算法D2SAC,下图为对应的算法结构部分。

五、实验和数据分析
作者全面评估了基于 AGOD 的 D2SAC 算法,并展示了与现有方法相比其优越的性能。我们的分析还为在离散动作空间中使用基于扩散的 DRL 提供了有价值的见解。
1.实验平台
实验是使用具有 24 GB 内存的 NVIDIA GeForce RTX 3090 GPU 和具有 128 GB RAM 的 AMD Ryzen 9 5950X 16 核处理器进行的。该工作站运行 Ubuntu 16.04 LTS 操作系统,并使用 PyTorch 1.13 以及 CUDAtoolkit 11.6 和 cuDNN 8.0。作者将软件环境和依赖项打包到 Docker 镜像中,以确保可重现性。
2.模型设计
D2SAC 采用基于扩散模型的 AGOD 作为参与者网络的核心,并使用两个具有相同结构的批评网络来缓解高估问题。下表显示了 actor 和 critic 网络的详细配置。
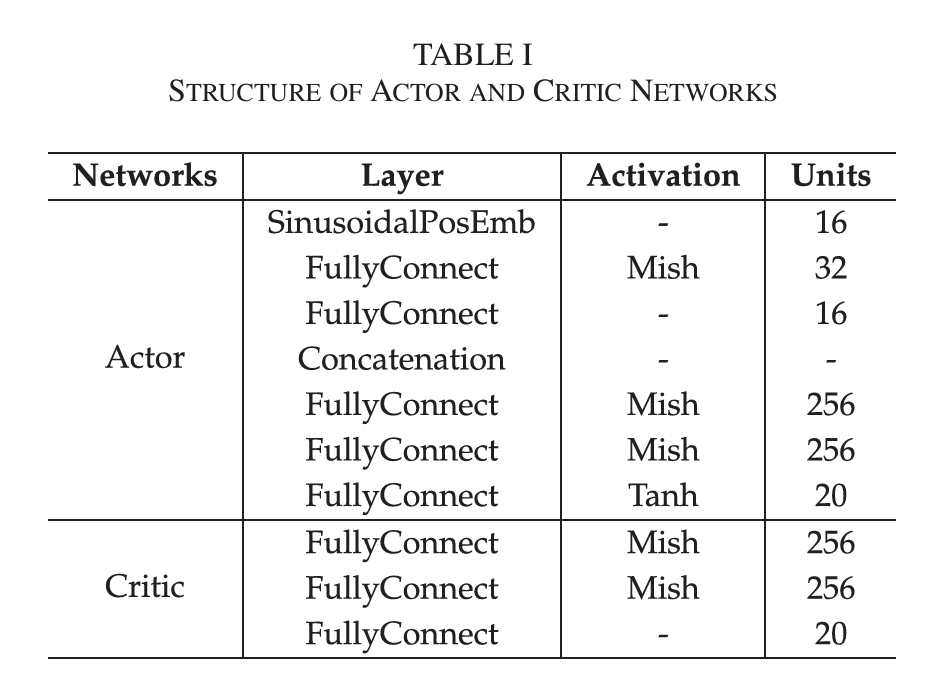
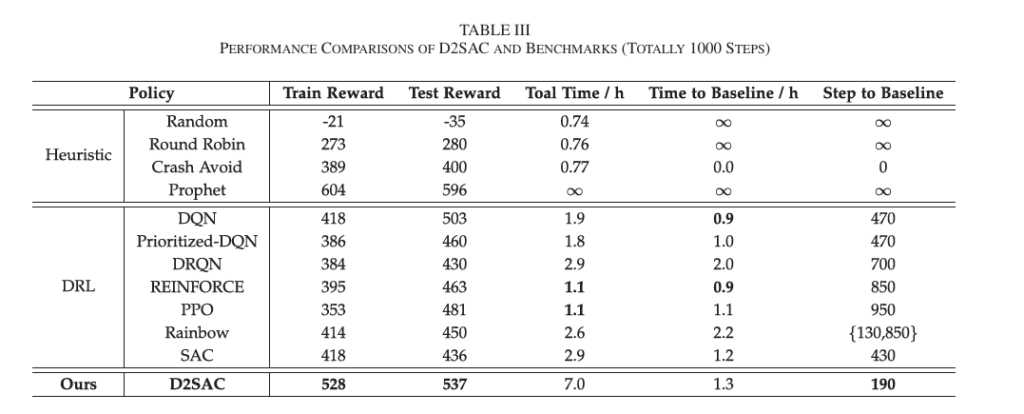
尽管与 SAC 相似,但 D2SAC 用基于扩散模型的 AGOD 取代了参与者网络。在下面的实验中,作者证明了 D2SAC优于这些基准。除了这些高级 DRL 基准之外,作者还实施了四种启发式策略:第一,将新任务随机分配给 ASPs,而不考虑可用资源、任务处理时间或其他约束,此策略用作计划性能的下限基线;第二,按循环顺序将任务分配给 ASP,当任务平衡良好时,此策略可以生成有利的计划;第三,根据它们可提供的资源,将任务分配给 ASPs,ASPs在任务分配中具有更多资源的优先级,以防止过载;最后,假设调度程序在分配任务之前提前知道 ASP 将为每个用户带来的每个实用程序,在这种情况下,通过将任务分配给具有最高效用的 ASP 来提供以人为中心的服务的性能上限,同时避免崩溃。
3.数值结果


六、总结
本文提出了一种创新的边缘 AaaS 架构,以实现无处不在的 AIGC 功能。为了应对环境不确定性和可变性的挑战,作者开发了基于扩散模型的 AGOD,该模型用于 DRL 以创建 D2SAC 算法,以实现高效和最优的 ASP 选择。广泛的实验结果证明了所提算法的有效性,在 ASP 选择问题和各种标准控制任务中都优于 7 种具有代表性的 DRL 算法。作者提出的方法为 Metaverse 中无处不在的 AIGC 服务提供了实用有效的解决方案。更重要的是,AGOD算法有可能应用于无线网络中的各种优化问题。