来源:arXiv
作者:Zhongzhen Huang、Kui Xue、Linjie Mu等
单位:Shanghai Jiao Tong University、Shanghai AI Laboratory
发表时间:2024年04月
一、论文介绍
1.背景:大型语言模型(LLM)在自然语言处理领域取得了显著进展,但在处理知识密集型任务时仍存在幻觉和时序错位等问题。检索增强生成(RAG)通过引入外部知识库来缓解这些问题,但在医疗领域应用时面临着缺乏领域知识和复杂场景的挑战。
2.目标:研究旨在探索RAG框架在医疗领域知识密集型任务中的应用,并评估LLM的能力。
二、核心内容
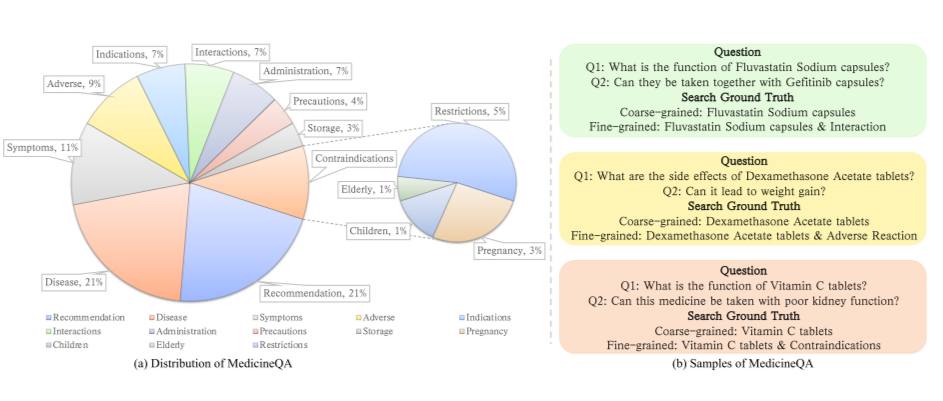
- 图 1: MedicineQA 数据集
- (a) MedicineQA 数据集分布: 该图展示了 MedicineQA 数据集中不同用药咨询场景的分布情况,包括药物相互作用、不良反应、禁忌症等。
- (b) MedicineQA 数据集样本: 该图展示了 MedicineQA 数据集中几个示例对话,包括用户提问、药物信息检索以及专业人员的回答。
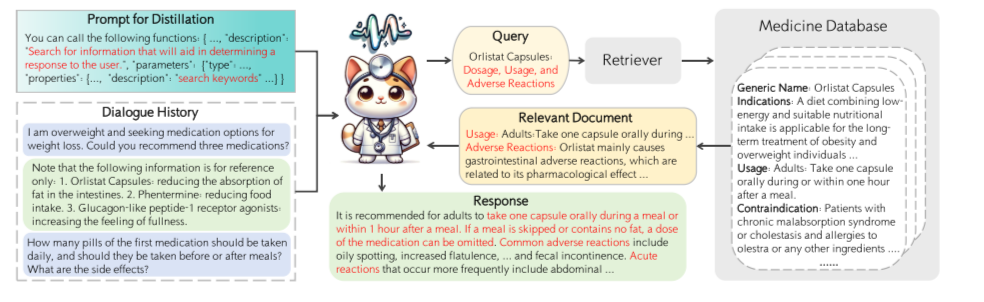
- 图 2: RagPULSE 工作流程
- 说明: 该图展示了 RagPULSE 模型的整体工作流程,包括对话历史蒸馏、证据检索和回答生成三个步骤。
- 意义: 该图清晰地展示了 RagPULSE 模型如何利用工具调用机制进行对话历史蒸馏,并利用检索到的证据生成准确的回答。
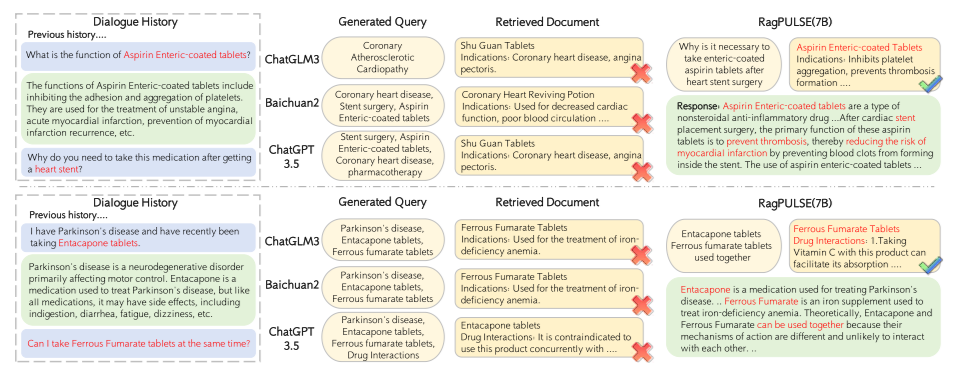
- 图 3: LLM 检索过程和生成回答的案例研究
- 说明: 该图展示了 ChatGLM3、Baichuan2、ChatGPT3.5 和 RagPULSE-7B 模型在检索过程和生成回答方面的案例,包括它们生成的搜索查询和检索到的证据。
- 意义: 该图直观地展示了不同模型在处理复杂对话历史和生成准确回答方面的差异,以及 RagPULSE 模型的优势。
三、实验内容
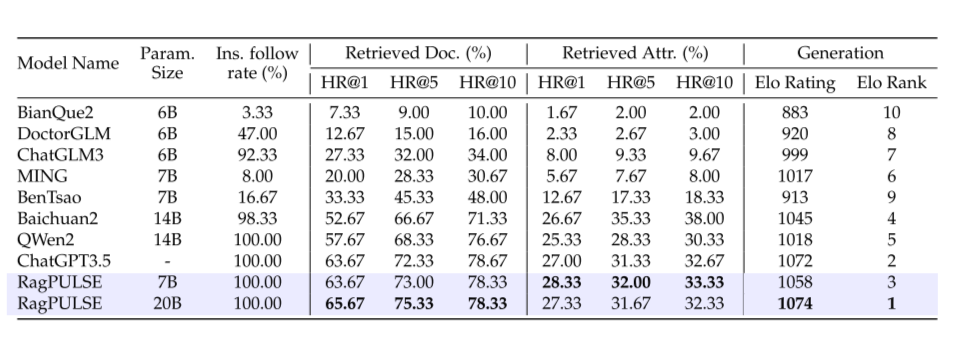
- 表 1: MedicineQA 数据集上的模型评估结果
- 说明: 该表展示了不同 LLM 模型和商业产品在 MedicineQA 数据集上的评估结果,包括证据检索准确率和用药咨询回答的 Elo 评分。
- 意义: 该表直观地展示了 RagPULSE 模型在证据检索和用药咨询回答方面的优越性能。
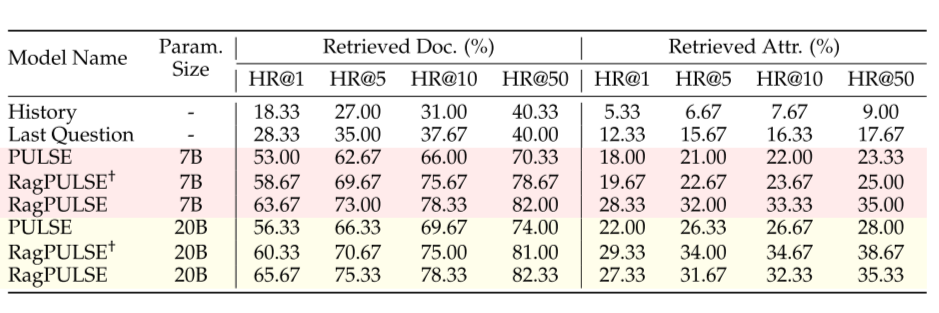
- 表 2: Distill-Retrieve-Read 框架的消融实验结果
- 说明: 该表展示了 Distill-Retrieve-Read 框架中不同组件对模型性能的影响,包括仅使用对话历史、仅使用最后一个问题以及结合工具调用机制的情况。
- 意义: 该表证明了 Distill-Retrieve-Read 框架的有效性,以及工具调用机制在提高证据检索准确率方面的关键作用。
四、总结与思考
总结:
1.提出MedicineQA,一个新的基准,从现实世界的药物咨询,旨在评估LLM在医学领域的能力。
2.通过“工具调用”机制提出了一个开创性的检索增强框架,蒸馏-检索-读取。
3.结合该框架,提出的RagPUSLE在性能上优于所有公开可用的模型,并且与具有较小参数大小的最先进的商业产品竞争
思考:
1.扩展MedicineQA数据集,涵盖更多用药咨询场景和药物种类。
2.探索更复杂的工具调用机制,例如结合自然语言处理技术进行语义理解和推理。
3.将RagPULSE模型应用于其他知识密集型任务,例如医疗报告生成和医疗诊断。