作者: Anjanava Biswas , Wrick Talukdar
期刊: Journal of Artificial Intelligence Research (CCF-B)
时间: 2024
1.背景
随着多模态大型语言模型(LLM)在自然语言处理(NLP)任务中展现出显著性能,其在文档数据提取中的应用受到了广泛关注。然而,现实世界中扫描文档常常存在平面旋转(即倾斜),这一常见问题会显著影响模型的准确性。以目前比较先进的三个大语言模型为例(Anthropic Claude V3 Sonnet、GPT-4-Turbo和Llava:v1.6),本文旨在系统研究大模型在识别理解文档关键键值对信息时,文档倾斜对其识别效果的影响。
2.核心内容
本研究系统地评估了文档倾斜对三个先进多模态大模型提取文档中关键键值对信息的性能影响。期望利用多模态LLM执行类似OCR的功能,以进行准确的结构化数据提取。研究的主要贡献包括:
1.明确文档偏斜对所测试的三种多模态LLM的提取精度都有显著影响。
2.确定了不同模型的安全平面旋转角度(SIPRA),即模型能够维持较高提取准确性的旋转角度范围。
3.分析了倾斜对模型产生幻觉(生成错误或虚构信息)的影响。
4.提出了新的多模态架构和预训练阶段的倾斜技术,以增强模型对文档倾斜的鲁棒性。
3.实验过程及结果
(1) 准备一个带有基本事实键值对注释的文档数据集。在原始的、未倾斜的文档图像中手动注释键值对。这些基本真值用作评估LLM从倾斜文档图像中提取的键值对准确性的参考。以编辑距离(Levenshtein)来衡量两个字符串之间的差异性。
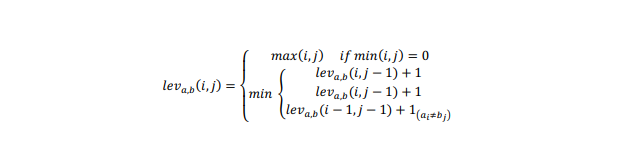
(2)使用图像处理技术对文档引入不同程度的倾斜。

(3)将偏斜的文档传递给所选的多模态LLM,并提取键值对。
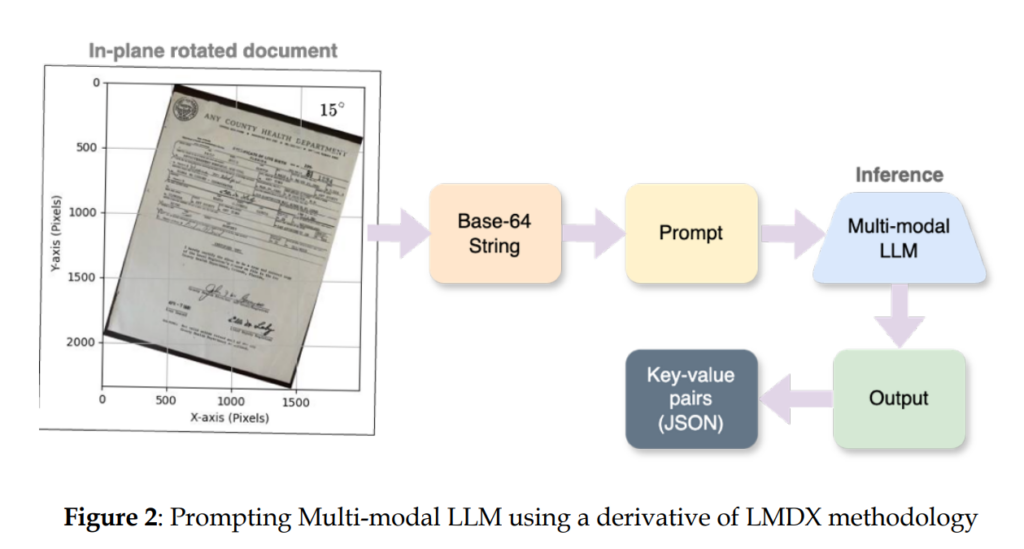
(4)使用精确度、召回率和F1分数等评估指标将提取的键值对与真实注释进行比较
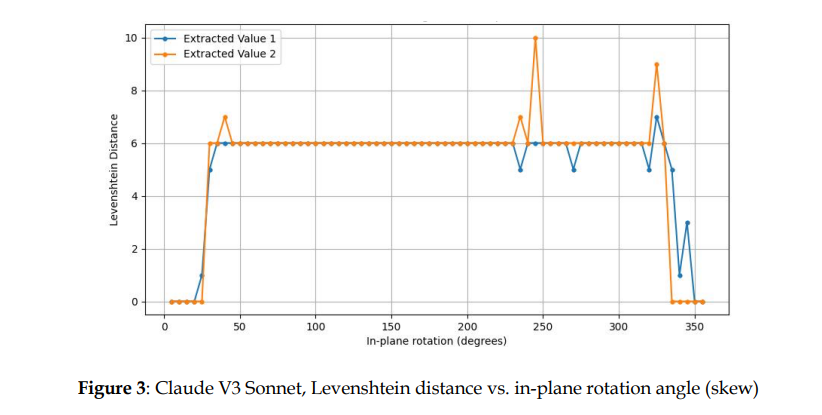
Claude V3 Sonnet模型实验结果
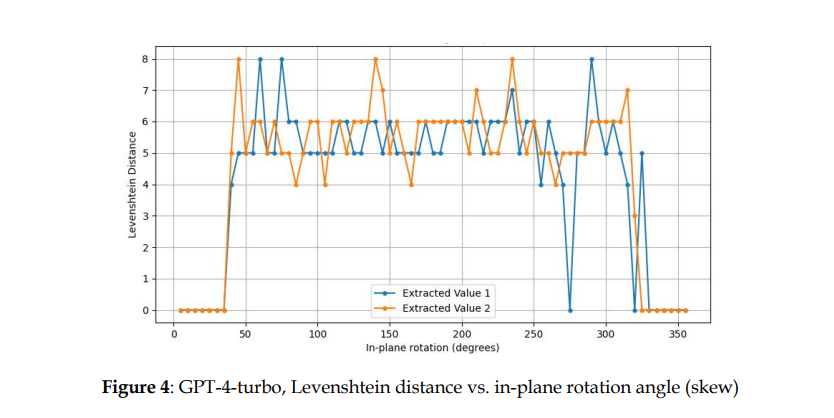
GPT-4-turbo模型实验结果
Llava:v1.6模型实验结果
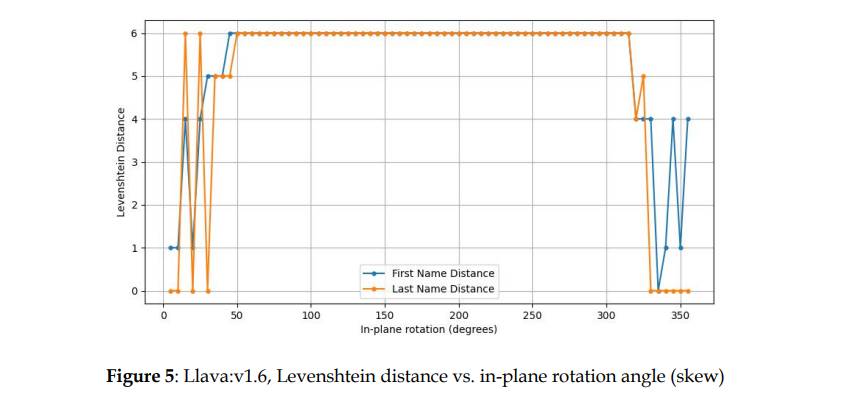
对比三个大模型对不同倾斜文档的识别结果可以得知,三种多模态LLM都在一定程度上受到文档偏斜的影响。
(5)分析不同偏斜程度对每种多模态LLM提取精度的影响
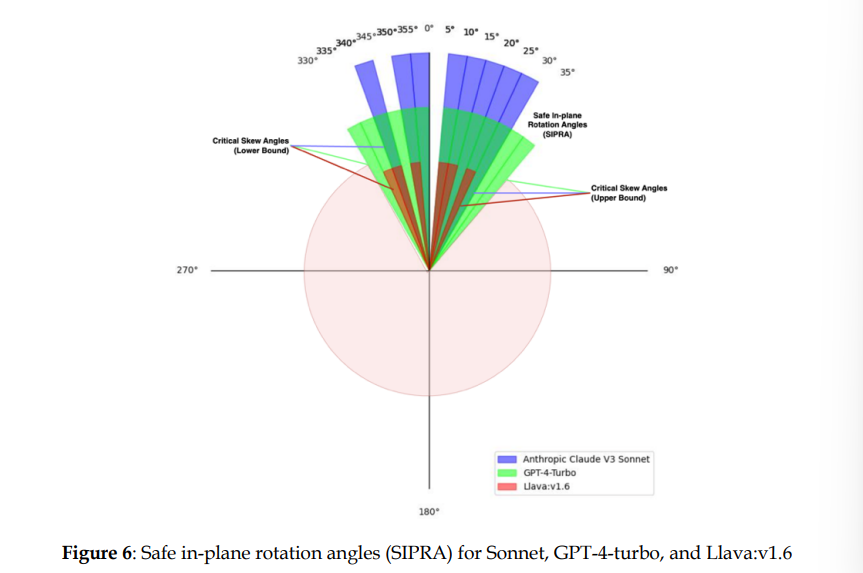
分析文档偏转角度与模型识别精确度等信息的饼状图我们可以得出:
1)GPT-4-Turbo、Anthropic Claude V3 Sonnet、Llava:v1.6文档倾斜的敏感程度不同。其中Llava:v1.6对文档倾斜最为敏感,GPT-4-Turbo对文档倾斜的适应性最大。
2)在文档倾斜达到一定程度后,各个模型出现了不同程度的幻觉。产生了错误的虚假信息。
3)对于倾斜文档对大模型识别效果产生影响的问题,文档提出了两种可行的方案以消除其影响。一是通过各种算法对文档进行预处理,将文档倾斜提前识别出来,并对其进行纠正;而是在训练大模型时,将倾斜文档也作为其训练数据的一部分,使大模型能够拥有完善的识别各类倾斜文档的能力,以实现对倾斜文档的识别处理。
4.总结与思考
1.本文的核心思路是利用多模态大模型执行类似OCR的功能,利用大模型对以图像为载体的文档数据进行处理,以进行准确的结构化数据提取。分析了文档倾斜因素对多模态大模型识别效果的负面影响以及消除影响的方法。
2.提供了利用多模态大模型进行数据处理的一种新的研究方法和研究视角。在利用多模态大模型处理网页信息数据和其他形式数据时,应注意类似“文档倾斜”因素对数据提取处理效果的影响。