作者:Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, Abhinav Rastogi
单位:Abhinav RastogiGoogle DeepMind
来源:arxiv
一、文章主要工作
思维链 (CoT) 提示引导 LLM 将任务分解为中间步骤,从而提高性能。结果奖励模型 (ORM) 和过程奖励模型 (PRM) 提供反馈,而 PRM 在每个步骤提供更详细的监督。当前像 Math-Shepherd 和 MiPS 这样的方法使用蒙特卡洛估计来自动化数据收集,而自洽解码和使用高质量数据集进行微调也提高了 LLM 推理能力。
文章的主要贡献如下:
- 提出了一种新的分治式蒙特卡洛树搜索算法,用于自动过程监督数据生成。
- 将验证器与加权自一致性相结合,以进一步提高LLM推理的性能。我们在数学基准测试中达到了69.4%的成功率。
二、模型框架
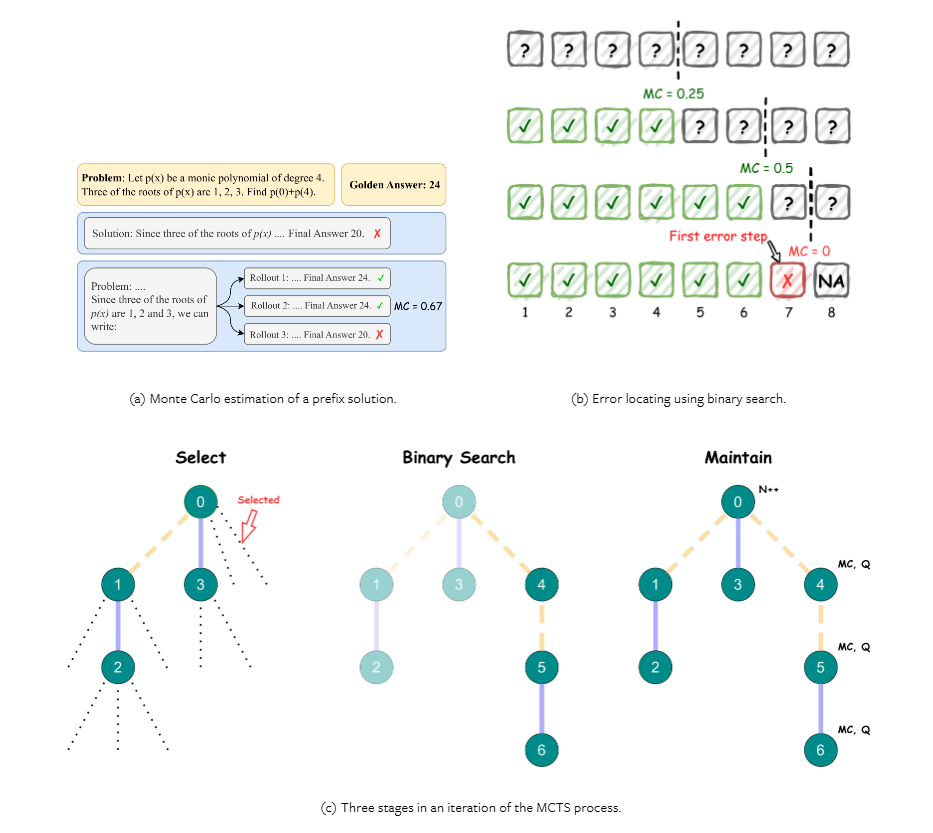
Google DeepMind 和 Google 的研究人员介绍了 OmegaPRM,这是一种用于自动过程监督数据收集的新方法。此方法采用分治蒙特卡洛树搜索 (MCTS) 算法来有效识别推理链中的第一个错误。OmegaPRM 使用二分搜索来平衡正例和负例的收集,确保高质量和高效率。这种自动化方法的特点是不需要昂贵的人工干预,因此使其成为提高 LLM 性能的可扩展解决方案。
OmegaPRM 方法包括创建一个状态-动作树来表示问题的详细推理路径。节点包含问题和前面的推理步骤,而边表示后续步骤。该算法使用温度采样来生成多个完成,视为近似动作空间。研究人员从 MATH 数据集中收集了超过 150 万个过程监督注释。使用这些数据训练的 Gemini Pro 模型利用加权自洽算法来提高性能,证明了 OmegaPRM 在训练 PRM 方面的有效性。
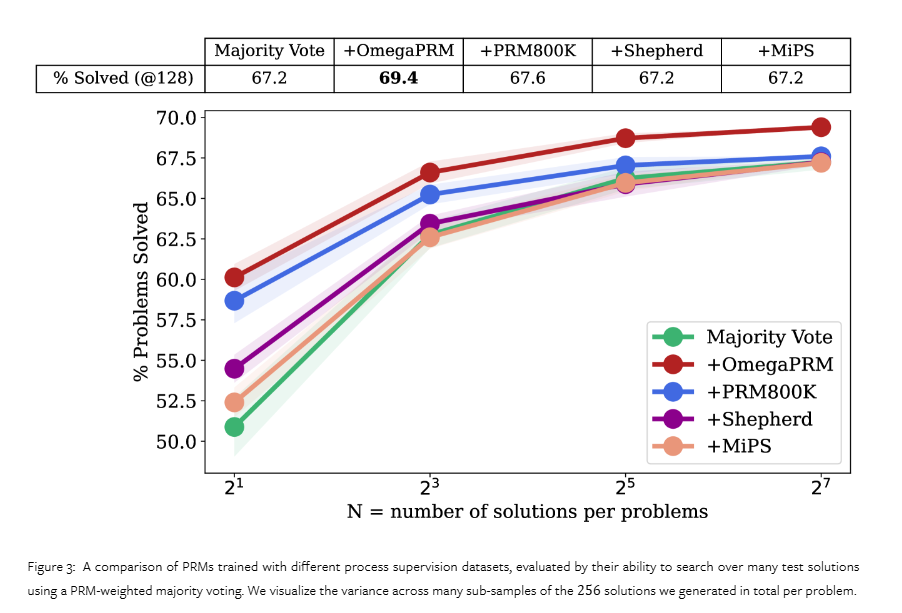
OmegaPRM 算法增强了指令微调的 Gemini Pro 模型的数学推理性能。该模型利用加权自洽算法以及自动过程监督,在 MATH 基准测试中取得了 69.4% 的成功率。这一成功率比基础模型 51% 的性能提高了 36%。研究人员的自动化方法确保数据收集成本与人工注释和暴力蒙特卡洛采样方法相比显着降低。这些改进突出了 OmegaPRM 在推进 LLM 在复杂多步推理任务中的能力方面的潜力。
三、实验结果


四、总结与思考
将COT方法拆分到中间步骤,在中间步骤中加入树的概念,利用蒙卡罗特搜索树的算法识别错误,选取最优解,从而实现基于进化思维树的大模型自洽推理这一概念的学习