论文来源:arXiv:2401.02187v1
作者:Haonan Li,Martin Tomko,Timothy Baldwin
发表日期:2024.1.4
一、背景介绍
随着旅游问答系统的应用增加,现有模型在处理包含地理空间约束的大规模POI候选集时,面临效率低、准确性不足的问题。大部分方法要么依赖结构化查询,要么需要为每个POI单独生成编码,导致推理过程复杂度高,难以应对实际需求。
LAMB模型采用双编码器架构,分别对问题和POI进行独立编码。问题编码器处理问题文本,POI编码器结合文本和地理信息对POI进行编码。通过相似度计算,模型在大规模POI候选集中高效检索出最相关的POI。
二、主要内容
LAMB模型框架图
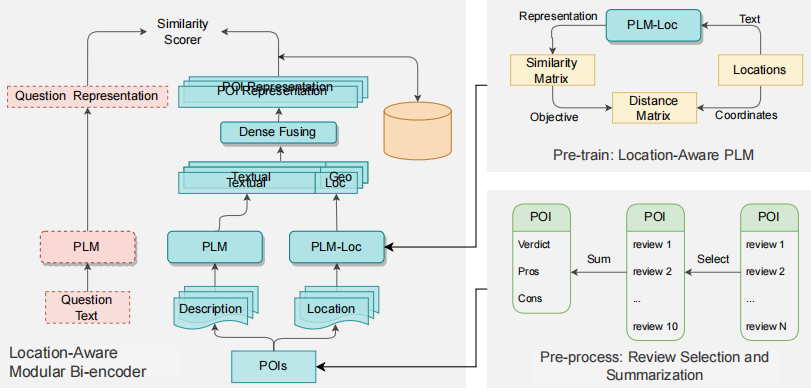
LAMB模型采用了双编码器架构,分别对用户提出的问题和POI(兴趣点)进行编码。问题编码器使用预训练语言模型(如DistilBERT)将问题文本转化为稠密向量,POI编码器则由文本模块和位置模块组成,对POI的描述和地理信息进行编码。文本和位置向量拼接后,通过稠密层融合生成完整的POI表示,并将这些表示预存和索引,以便快速匹配问题。在推理时,系统通过内积相似度计算问题向量与POI向量的匹配度,根据相似度得分排序并推荐最优POI。模型的训练采用对比学习和三元组损失,确保物理上接近的POI在向量空间中也相近,实现了文本与地理信息的高效融合和推荐优化。
三、实验评估
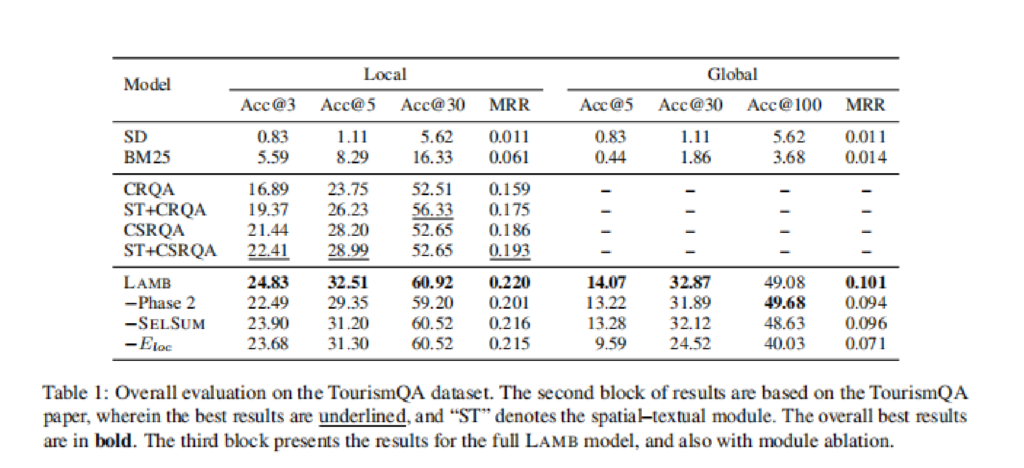
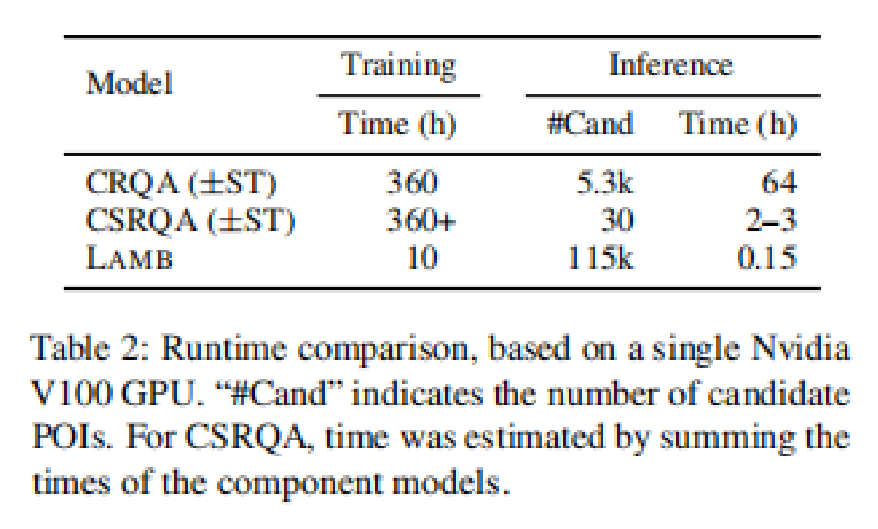
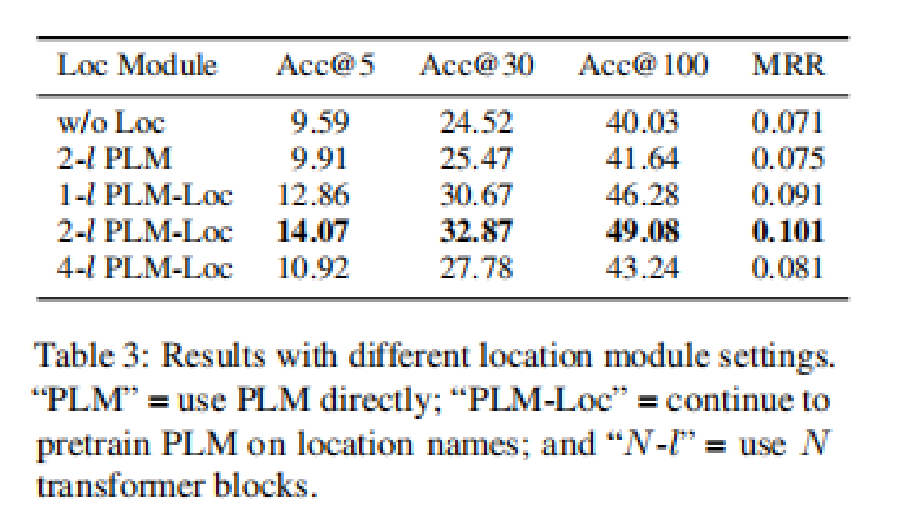
消融实验

四、启发思考
1、双编码器架构:用户与路线节点的高效匹配
在个性化路线规划中,也可以使用双编码器分别对用户历史行为数据和路线节点(景点、餐厅等POI)进行编码。
2、使用预存和索引机制:提前编码提升效率
通过捕捉用户的历史行为,生成用户的偏好标签,并基于用户偏好向量与POI表示向量之间的相似度,能够高效地提取出用户的兴趣点。
进一步地,可以通过聚类或分类算法为用户生成多个偏好标签,构建更精细的用户画像。
随着用户与系统的持续交互,偏好标签也可以动态更新,更精准地反映用户的兴趣变化,从而为个性化推荐和路线规划提供实时支持。