一、信息
来源: ACL2024
作者:Alex G. Kim、Keonwoo Kim、Sangwon Yoon
作者信息:芝加哥大学
二、背景与痛点
- 传统的评估方法,如ROUGE和BLEU,主要基于词汇层面的匹配,无法充分反映语义的一致性。
- 基于LLM的评估器:
- 多被用作文本评估的zero-shot评估器,大多数研究一种直接的方法,提供特定任务的说明来让LLM评估,是一种无参考度量。
- 现有研究通常采用单一代理的方式,容易受到模型偏见的影响。这种偏见限制了评估的有效性和稳定性,因此有必要引入更加客观的评估框架。
三、本文创新点
- 论文提出了一个新的NLG评估框架,名为DEBATE(Devil’s Advocate-Based Assessment and Text Evaluation)该框架引入了多代理评分系统,并且通过引入“魔鬼代言人”的角色来批判其他代理的评估结果,从而减少单一代理的偏见问题。
- DEBATE可以通过多次迭代辩论,深入挖掘文本之间的语义关联
- DEBATE通过多代理间的争论和批评,提高了评估的可靠性和与人类评分的相关性。
四、算法
DEBATE框架中包含三个主要角色:指挥官(Commander)、评分者(Scorer)和批评者(Critic)。指挥官负责组织辩论,评分者根据任务指令进行评估,批评者则扮演“魔鬼代言人”,批判评分者的评分结果,帮助平衡评估过程。
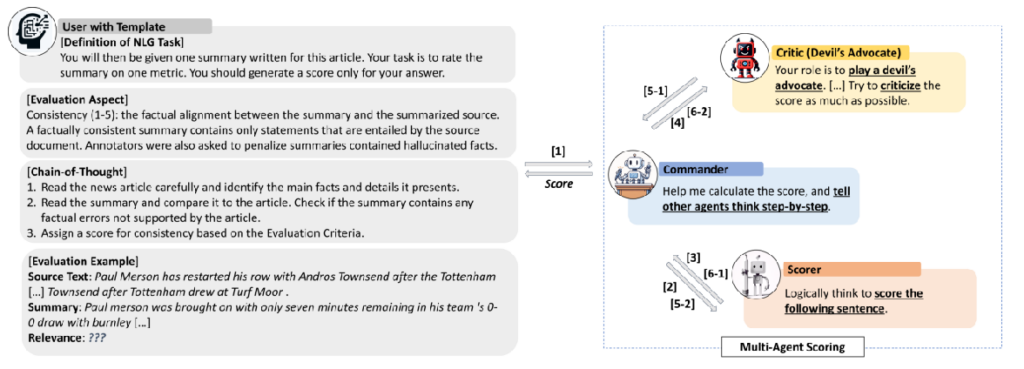
批评家的prompt为:

五、实验
1. 基准数据集
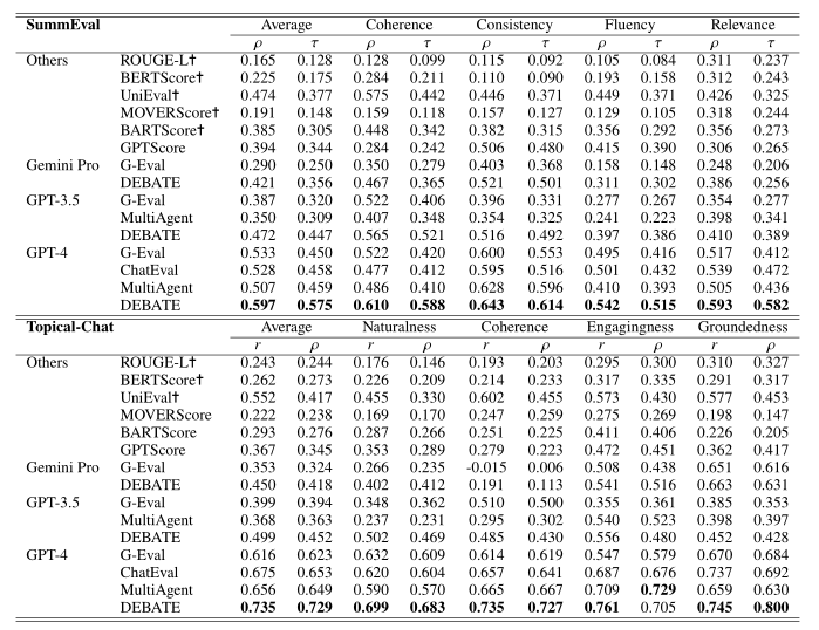
- SummEval:用于摘要生成的评估,考察文本的流畅性、一致性、连贯性和相关性。DEBATE在多个维度上超过了现有最优方法,显示出更高的人类相关性。
- Topical-Chat:用于对话生成的评估,考察对话的自然性、连贯性、吸引力和基础性。DEBATE同样取得了显著的提升,尤其在自然性和连贯性上表现突出。
2. 对比evalator
- 传统的评估器ROUGE-L (2004);
- 基于预训练语言模型的评估器,BERTScore (2022)、MoverScore (2019)、BARTScore (2021)和UniEval (2022);
- 最近基于llm的评估器,GPTScore (2023),G-Eval (2023)和ChatEval (2023)。
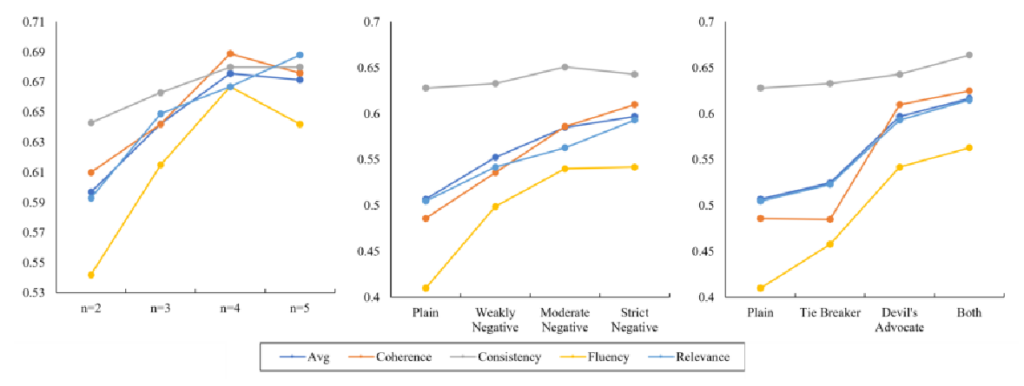
- 还包括MultiAgent,这是一个类似于DEBATE的框架,但批评家被分配了一个中立的辩论角色,标记为Plain。
3. 实验结果

六、总结与思考
- DEBATE框架通过引入多代理系统,尤其是“魔鬼代言人”的批评机制,有效改善了机器生成文本的评估质量,消除LLM的偏见和局限性,从而提高评估的准确性。
- 这一创新框架为未来的NLG评估提供了新的思路,证明了社会科学中的辩论策略在LLM评估中的潜力。
- 思考:DEBATE证明了多代理协作评估可以显著提升评估的质量,这为未来开发更复杂的、多层次的评估框架提供了可能。未来的评估方法可以借鉴DEBATE的多代理框架,结合更多的角色(如纠正者、补充者等),进行更加复杂的文本生成评估。