来源:Computer Communications 2023
作者:Wang Zhenhua, Guo Yan, Li Ning, Yuan Hao, Hu Shiguang, Lei Binghan, Wei Jianyu
单位:中国人民解放军陆军工程大学,中国人民解放军空军工程大学
一、背景
未来战争格局具有强对抗性、强博弈性、高动态性等显著属性,战场上敌我信息不对称、不完整,敌我双方会引进大量无人作战装备,因此,未来战争作战格局逐渐演变为敌我无人系统群组(unmanned system group,以下简称USG)对抗。战场进程和节奏急剧加快,从而对前线指挥员的战场态势评估和作战意图决策能力提出了更高的要求。得益于深度强化学习(DRL)等人工智能技术在USG自主协同控制领域的广泛而深入的应用,以无人机(UAV)为代表的USG在协同侦察、饱和攻击、协同探测、协同围捕、协同搜索、精确打击等方面应用广泛,已经成为建立多任务无人作战系统精确协同协调体系的重要支撑。其中,利用USG对目标区域内多个运动时敏目标进行协同搜索是USG重要的实战应用方向,对构建USG自主对抗策略学习进化(ACSLE)机制具有重要的参考意义。
针对于此,该文的研究动机是进一步提高USG自主对抗策略的实战应用可信度,强化实战指挥员在对抗循环中USG自主对抗策略学习演化过程中的指导地位,以及与USG自主对抗策略学习演化过程相关的多个问题。 研究了通过与指挥员持续交互实现高动态实战场景下USG自主对抗策略主动学习进化,提出了一种实战循环下USG自主对抗策略学习进化机制(ACS-ACL)。
二、贡献
文章主要设计了一种实战循环下USG自主对抗策略学习进化机制(ACS-ACL),该算法主要贡献如下:
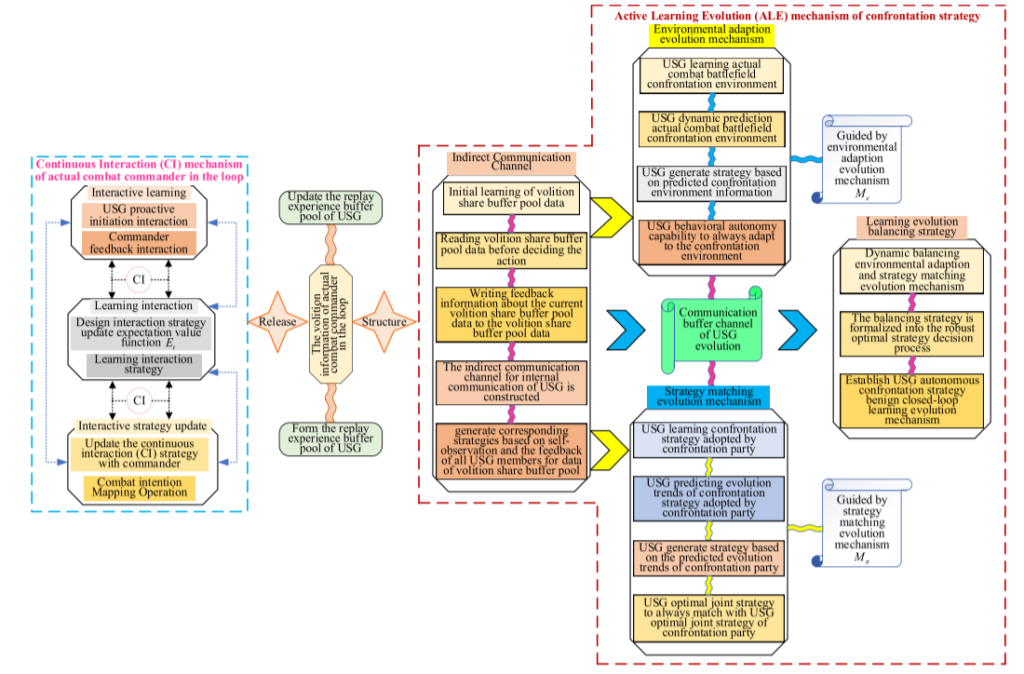
1.提出了持续交互(Continuous Interaction,CI)机制,通过与实战指挥员的循环持续交互不断填补自我体验差距。加快USG经验学习进程,生成与指挥员意志相结合的USG自主对抗策略,进一步提高USG自主对抗策略的实战应用可信度,强化实战指挥员在USG自主对抗循环中的指导地位。
2.提出了自主对抗策略主动学习进化(Active Learning Evolution,ALE)机制,在ALE机制的作用下,USG自主对抗策略结合指挥官意志触发有针对性的主动学习进化,一方面引导USG行为自主能力始终适应强博弈性、高机动性、高强度的复杂实战战场对抗环境;另一方面引导USG最优联合策略与对抗方USG最优联合策略不断匹配,实现作战意图驱动下自主对抗策略学习的持续良性演化。
三、方法
1.问题描述
USG对敌执行协同搜索移动目标任务是跨域协同作战的重要作战模式。选择多架无人机作为USG实体,假设己方多架无人机无序分布在某个未知的连续动态有限作战空域,敌方多架无人地面车辆(UGV)无序分布在该作战空域映射的地面上,无人机 己方无人机搭载目视侦察设备,实现对地面目标的有效搜索识别,敌方无人无人车搭载反侦察设备,有效躲避己方无人机的搜索识别。
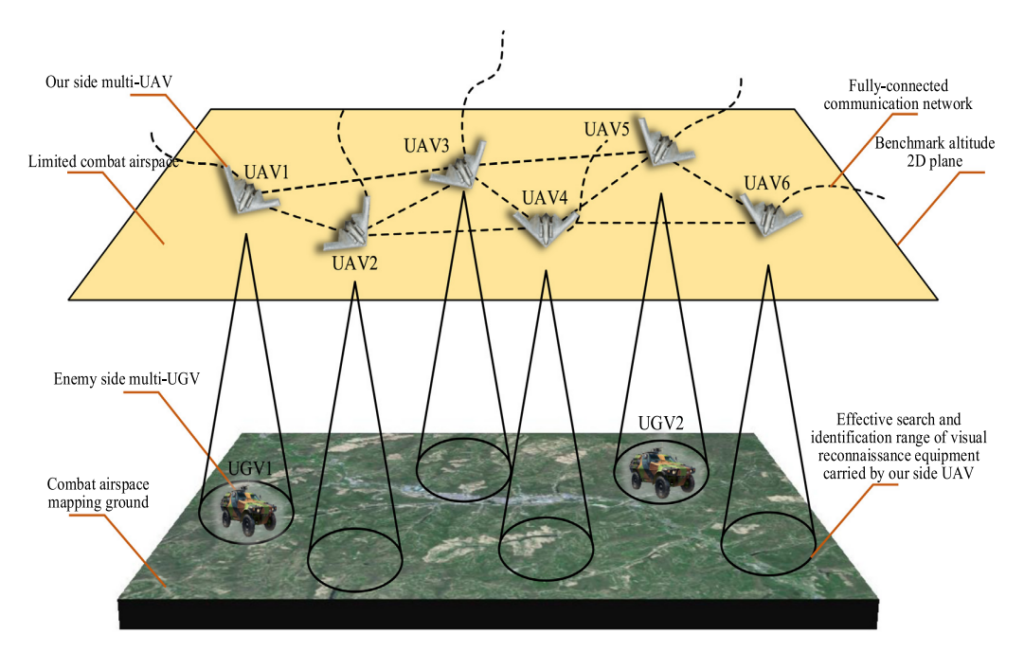
2.自主对抗策略生成模型
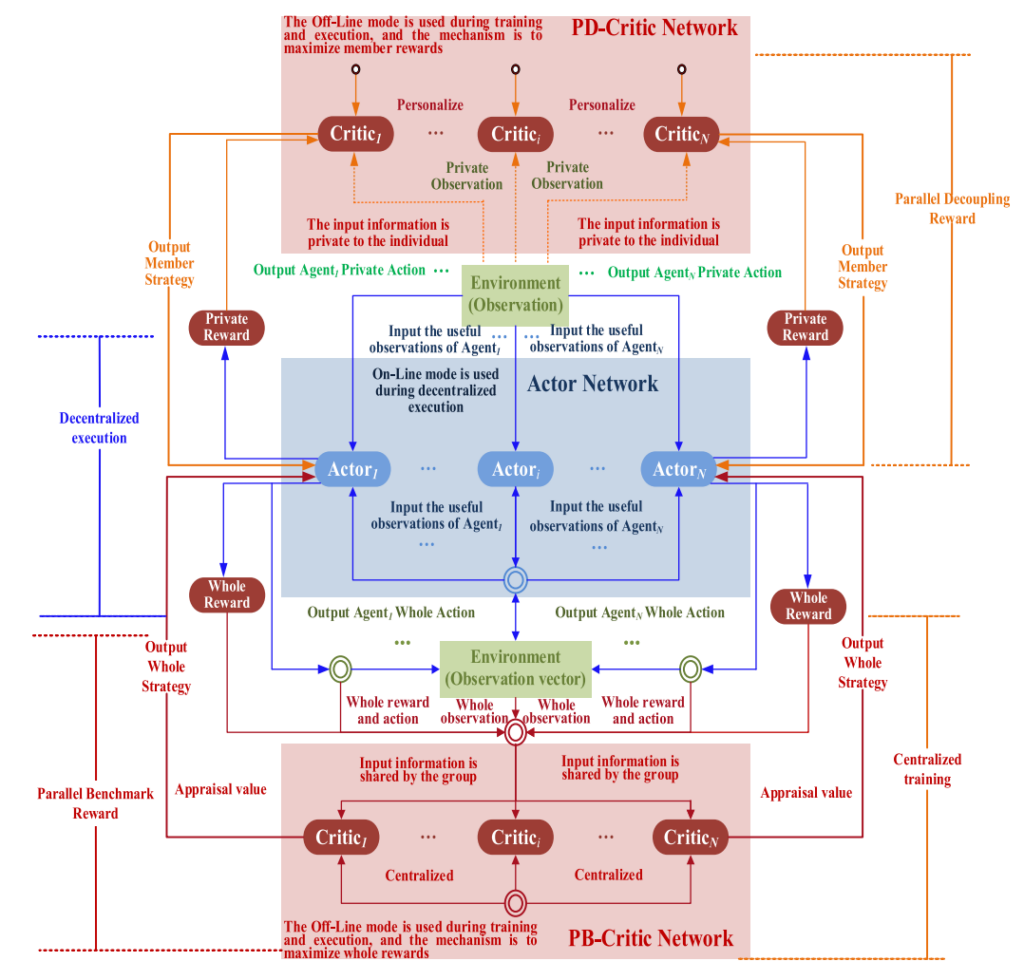
为了在并行时间上最大化USG的整体奖励和成员奖励,提高MADDPG算法的收敛效率,在MADDPG算法的基础上融入并行解耦的思想(PDRM-MADDPG)。
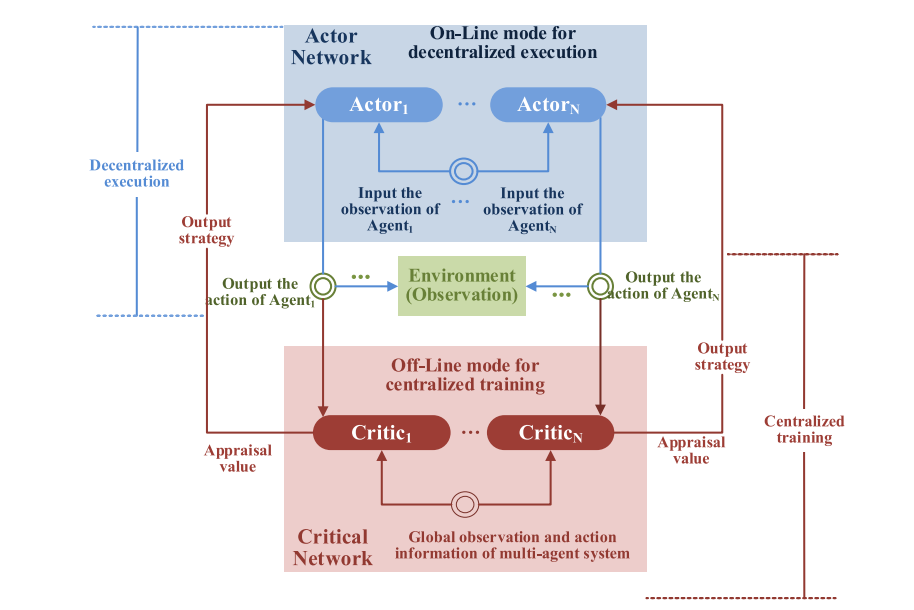
MADDPG:
PDRM-MADDPG:
3.实战指挥员循环持续互动机制
为进一步提高USG自主对抗策略的实战应用可信度,强化实战指挥员在循环中USG自主对抗策略学习演化过程中的指导地位,引导USG的经验学习过程与USG自主对抗策略的学习过程耦合,引入了持续交互(CI)机制。
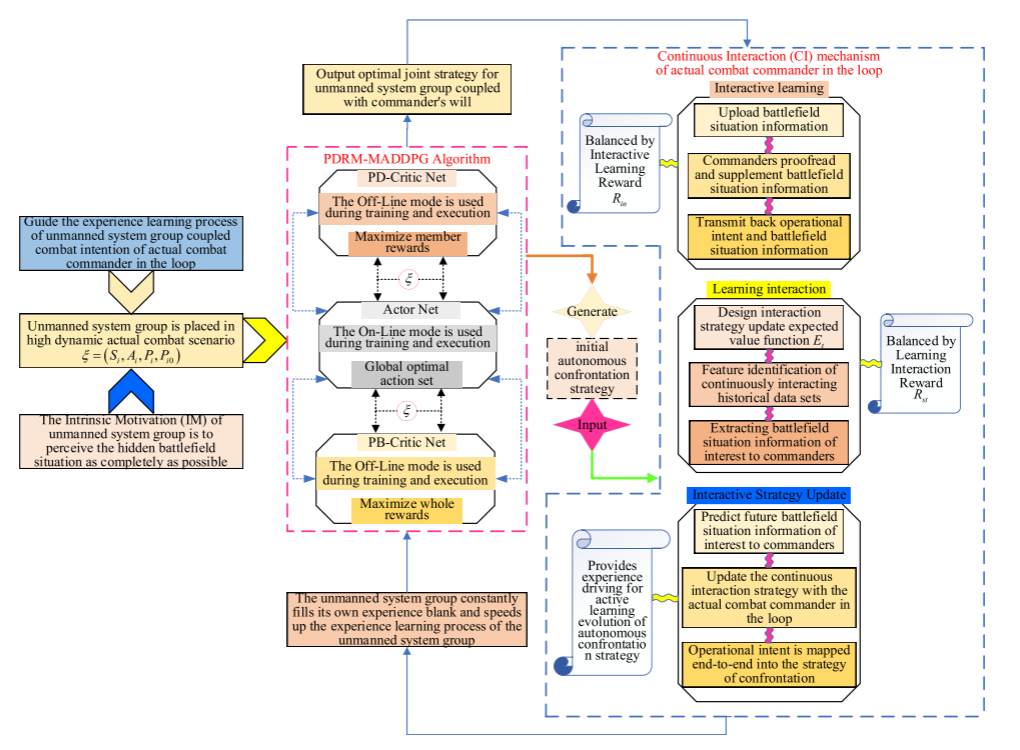
4.自主对抗策略主动学习进化机制
为了引导通过连续交互(CI)机制生成的指挥员意志耦合USG自主对抗策略主动学习演化,充分利用实战指挥员在连续交互(CI)过程中释放的意志信息来更新回放USG的经验缓冲池(REBP),将实战指挥员的作战意图以端到端的形式循环映射到USG自主对抗策略学习进化过程,引入了对抗策略的主动学习进化(ALE)机制。
四、结论
ACS-ACL算法与PDRM-MADDPG算法相比,获得了更高质量的训练和执行效果,并且随着训练次数的继续,ACS-ACL算法的收敛效率和质量有不断变好的趋势。 通过增加对抗环境的复杂性和增强对抗方的策略智能程度,ACS-ACL算法与PDRM-MADDPG算法的性能差异进一步拉大,表明ACS-ACL算法具有主动学习进化属性,可以实现持续的学习进化属性和作战意图驱动下自主对抗策略的良性演化,在未来空战无人对抗领域具有可观的应用前景。